
OpenAI-Compatible Is Becoming a Fiction We Keep Paying For — The Production Edges That Break in…

OpenAI-Compatible Is Becoming a Fiction We Keep Paying For — The Production Edges That Break in 2026
I’ve watched “OpenAI-compatible” stop meaning portable the moment a workflow needed structured output, file handling, or tool calls that weren’t on the happy path.
As of 2026–03–10, my working definition is blunt: most vendors mean wire compatibility, not behavior compatibility. The request shape often looks close enough that the OpenAI SDK connects. The trouble starts one layer up — schema-enforced outputs, file inputs, streaming event semantics, reasoning fields, and tool-call replay. That’s where production systems actually live.
The evidence piles up quickly. Ollama users hit ValidationError and empty content when using OpenAI SDK parsing with gpt-oss:20b against a local OpenAI-style endpoint (issue #11691). PDF upload can succeed and still fail later in streaming because MIME metadata disappears across API stages (issue #2472). And LangChain maintainers now say plainly that it is “not practical” for a generic OpenAI wrapper to absorb every third-party extension (issue #34328).
So I no longer design around “swap the base URL.” I design around explicit capability boundaries.
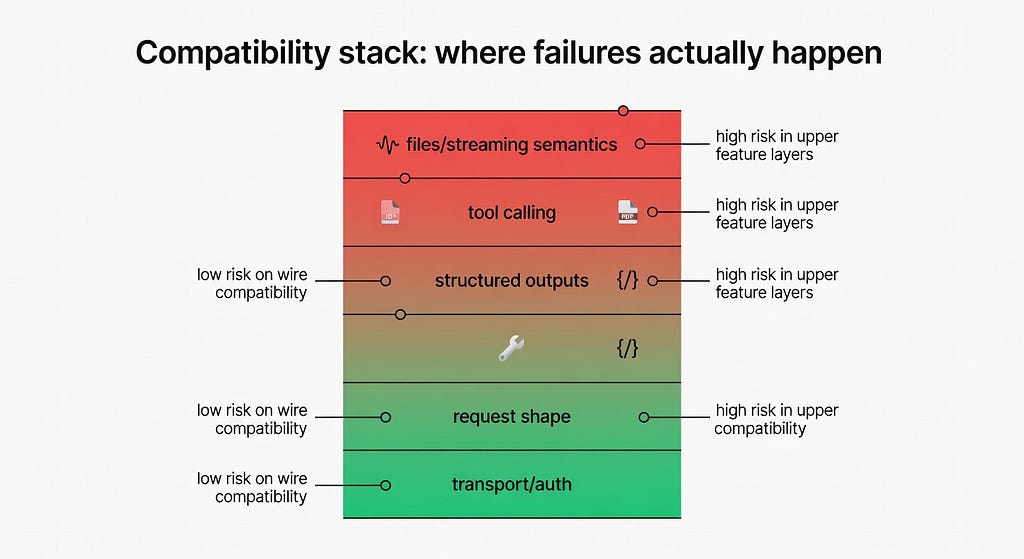
The happy path is usually real. The trouble starts one layer up, where contracts and stateful behavior matter more than matching an endpoint shape.
The Promise Sounds Great Because the Happy Path Is Real
Last month I noticed I was repeating the same mistake in different projects.
A workflow would start on one provider, usually with plain chat completions, and everything looked fine. Then I’d swap in a cheaper route, a local endpoint, or a proxy because costs were creeping up or latency looked better on paper. For a day or two, it felt like the abstraction held. Same SDK. Same method names. Same base_url trick.
Then the real workload showed up.
A WhatsApp automation needed strict JSON because n8n nodes downstream were brittle. A coding workflow needed tool calls to round-trip cleanly. A document flow needed PDF input plus streaming. And suddenly “OpenAI-compatible” turned into a bit of a mess.
That’s why I think the framing in buyer guides is incomplete. Hivenet’s buyer guide to OpenAI-compatible APIs is useful as a checklist for routes, payloads, SSE, errors, and headers. But it still treats compatibility as something you can mostly verify at the transport layer. In practice, what I’ve found is that production failures cluster at the feature layer — the exact place where your app stops being a chat demo and starts being software.
LangChain’s maintainers have basically said the quiet part out loud. In the still-open tracking issue #34328, Mason Daugherty writes, “It is not practical for ChatOpenAI to handle each addition that third party providers make to the Chat Completions standard,” and later adds, “The recommendation remains to use provider-specific packages which are purpose-built to handle these fields correctly.” That is why LangChain has been pushing dedicated integrations such as ChatOpenRouter and, separately, first-party support for langchain-openrouter and langchain-litellm rather than pretending one generic wrapper can absorb every proxy, router, and quasi-compatible extension.
That’s not a minor caveat. That’s the architecture talking.
And once you see it, you can’t unsee it.
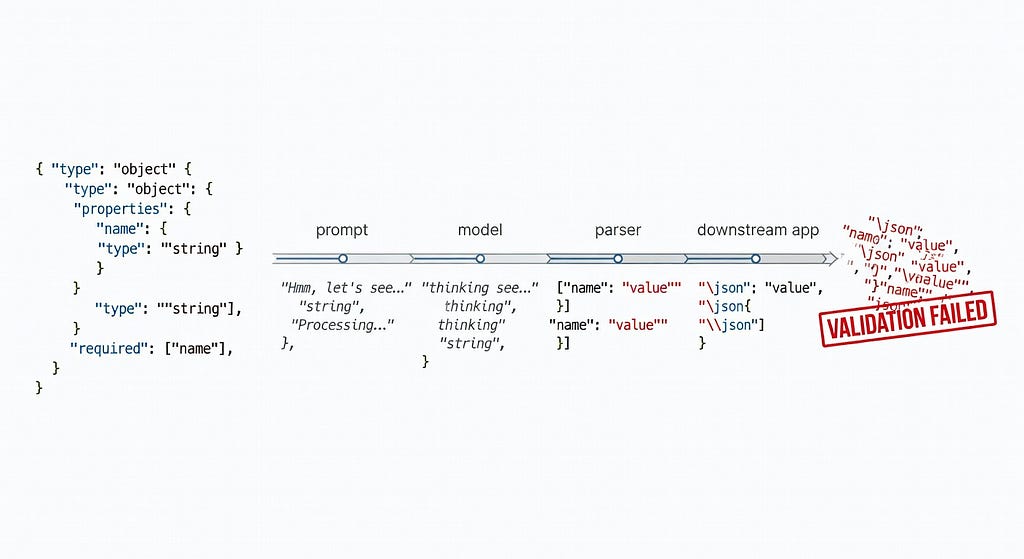
Structured output is usually the first crack because downstream systems need a contract, not a model that was trying its best.
Structured Output Is Usually the First Crack
The cleanest example is structured output, because it exposes the difference between “valid JSON sometimes” and “schema-enforced output as a contract.”
OpenAI’s docs are explicit here. Structured Outputs “ensures the model will always generate responses that adhere to your supplied JSON Schema,” and OpenAI recommends using it instead of JSON mode when possible (docs). That promise matters because downstream systems don’t care whether the model was trying its best. They care whether the object parses.
Now compare that to what happens when you point the same SDK pattern at an OpenAI-style endpoint that only imitates the surface.
Failure reproduction: OpenAI SDK parse() against Ollama gpt-oss:20b
The reproducer in Ollama issue #11691 is almost offensively simple:
import openai
from pydantic import BaseModel
class Response(BaseModel):
response: str
client = openai.OpenAI(api_key="NONE", base_url="http://localhost:11434/v1")
response = client.beta.chat.completions.parse(
messages=[{"role": "user", "content": "Hello, how are you?"}],
model="gpt-oss:20b",
response_format=Response,
)
print(response)
The observed failure:
pydantic_core._pydantic_core.ValidationError: 1 validation error for Response
Invalid JSON: expected value at line 1 column 1
That alone would be enough. But the thread gets uglier in a very familiar way. Users report empty content, leaked thinking text, random fragments, and behavior that changes depending on whether format=”json” or prompt-level schema instructions are used (#11691). One test in the thread shows format: “json” returning partial garbage like:
"response": ""Hello there! Respond in the JSON format { "nn }"
Remove the JSON format parameter, and the model may emit a plausible JSON string in response while also emitting separate thinking content. In other words: the model can produce something that looks salvageable, but the compatibility layer does not preserve the contract the SDK expects.
A few workarounds show up in the thread: put the schema in the prompt, strip markdown fences, or run a second small model to reformat the first model’s answer into JSON (timeline discussion). I’ve used all three variants in one form or another. They work the way duct tape works on a leaking pipe — sometimes long enough to get through the week.
But they are regressions. You’re back to pre-structured-output reliability, where parsing is probabilistic and every downstream consumer needs defensive code.
As of 2026–03–10, the issue remains open despite a linked PR (#14288, Feb 2026) targeting structured outputs for thinking models in /api/generate. That is real progress. It is also not the same thing as saying the problem is solved. Users are still reporting that structured outputs for gpt-oss are not fully dependable in the ways production systems actually care about.
That distinction matters.
Oddly enough, that’s the part many teams miss when they say “it works for us.” Sure. It works until the contract matters.
And no, prompt-level JSON is not the same fallback. OpenAI’s own docs draw a hard line: JSON mode ensures valid JSON, while Structured Outputs ensures schema adherence (docs). Those are different guarantees, and production code feels the difference immediately.
Silent incompatibility is worse than a hard failure
There’s a nastier pattern than explicit breakage: the request appears to work, returns plausible output, and quietly drops the behavior you depended on.
LangChain issue #35320 is a good example. A user showed that chaining .bind(tools=[…]) and then .with_structured_output(…) on ChatOpenAI silently removed the previously bound tools from the final request. No exception. No warning. Just a structured-looking answer that hallucinated weather because the web_search tool never ran. As the reporter put it, “There is no error. That is the core problem — this fails completely silently.”
The workaround is telling: pass tools directly into with_structured_output(…, tools=[…]) instead, which contributors said does preserve them (#35320). The root cause, according to a contributor in the same thread, sits in RunnableBinding.__getattr__, where configs were forwarded but **kwargs were ignored.
This is not exactly the same as provider incompatibility. But it rhymes with it in the worst way. The system degrades silently, the output still looks polished, and the missing capability only shows up when you inspect raw requests or notice the model confidently inventing facts. Hard failures are annoying. Silent compatibility failures are pager bait.
Reasoning fields still drift across “compatible” stacks
The same pattern shows up in reasoning metadata, which sounds minor right up until your UI, tracing, or replay logic depends on it. Recent duplicates tied back to LangChain’s broader compatibility mess — #35059 and #35516 — show vLLM and DeepSeek still dropping or failing to extract reasoning_content in OpenAI-style wrappers and streaming paths. One report says ChatOpenAI “silently drops” the field, while another says DeepSeek streaming leaves reasoning_content undefined (source, source).
And the problem doesn’t stop at LangChain. AG-UI’s LangGraph integration has its own open bug for dropping DeepSeek-style reasoning tokens from additional_kwargs.reasoning_content, which means no reasoning events get emitted downstream (issue #1251). Looks like a naming quirk. Behaves like lost state.

Most breakages aren’t about connecting the SDK. They’re about the awkward gap between surface similarity and behavioral guarantees.
Files and Streaming Fail Across Stages, Not Just Endpoints
File handling exposes a different failure pattern.
A lot of people test “can I upload a file?” and stop there. But the real workflow is multi-stage: upload, reference, infer, maybe stream, maybe combine with tools, maybe run on a cloud variant that lags the public API. Compatibility can break at any seam.
A PDF can upload successfully and still fail later
In openai-python issue #2472, a user uploads PDF bytes through the Files API, gets back a file_id, and then uses that file in a streaming request. The upload succeeds. The later inference request fails with a 400:
“Invalid file data: ‘file_id’. Expected a file with an application/pdf MIME type, but got unsupported MIME type ‘None’.” (#2472)
That’s a great example of why production compatibility testing is annoying and necessary. The failure is not “files unsupported.” It’s subtler: metadata got lost or wasn’t inferred correctly between upload and streaming usage. The issue references fixes around automatic MIME detection and a PDF upload-plus-streaming example, which tells you the bug lived in the glue layer, not the conceptual feature (issue thread).
I’ve seen this class of problem in no-code automation too — one stage happily stores an opaque file handle, the next stage assumes richer metadata than it actually has. Same pattern, different clothes. I’ve seen the same thing in platforms like Atiendia.com when an upstream abstraction claims document support but the downstream action really expects a narrower file contract.
And to be clear, the reporter explicitly marked this one as a Python SDK issue rather than an underlying OpenAI API issue (#2472). That makes the lesson sharper: even first-party SDKs can lose metadata in multi-stage flows, so third-party compatible layers deserve even less trust.
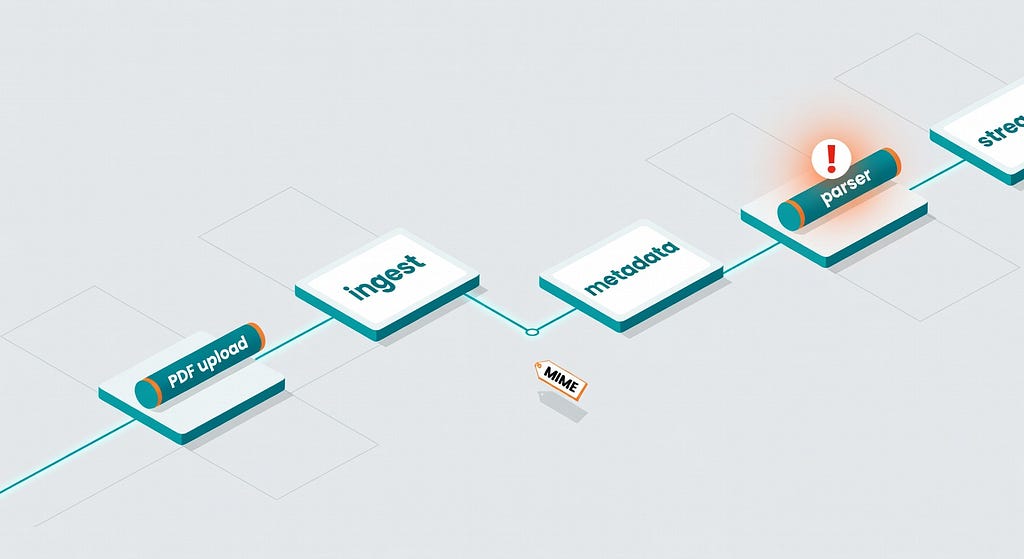
File workflows can succeed at upload and still fail later when metadata or semantics don’t survive the trip across API stages.
Tool Calling Breaks on Semantics, Not Just Syntax
Tool calling is where abstractions really start sweating.
The request schema may look compatible. The model may even emit something that resembles a tool call. But tool use is a conversation protocol, not a single payload. You need agreement on tool definitions, tool choice behavior, streamed arguments, replay rules, reasoning items, and what has to be passed back on the next turn.
That’s why LangChain’s tracking issue #34328 matters so much. It’s basically a catalog of ways OpenRouter, LiteLLM proxies, vLLM, DeepSeek-style reasoning models, and other OpenAI-like providers diverge from what ChatOpenAI can safely normalize. Structured output failures. Missing reasoning fields. Malformed JSON. Tool replay mismatches. Provider-specific metadata. Null choices. Headers that differ. Response schemas that differ.
The maintainer conclusion is not “we’ll patch over all of it.” It’s the opposite: use provider-specific packages where possible. They explicitly recommend purpose-built integrations like ChatOpenRouter and langchain-litellm rather than pretending one generic OpenAI wrapper can absorb every extension (#34328).
That’s an architectural admission — and a healthy one.
A nice micro-example is reasoning metadata. LangChain’s own discussion around #34328 points to field drift across reasoning_content, reasoning, thinking, and reasoning_details depending on provider. That sounds minor until a wrapper drops one of those fields and your debugging, replay logic, or UI quietly loses the model’s intermediate state.
Looks compatible. Behaves differently.
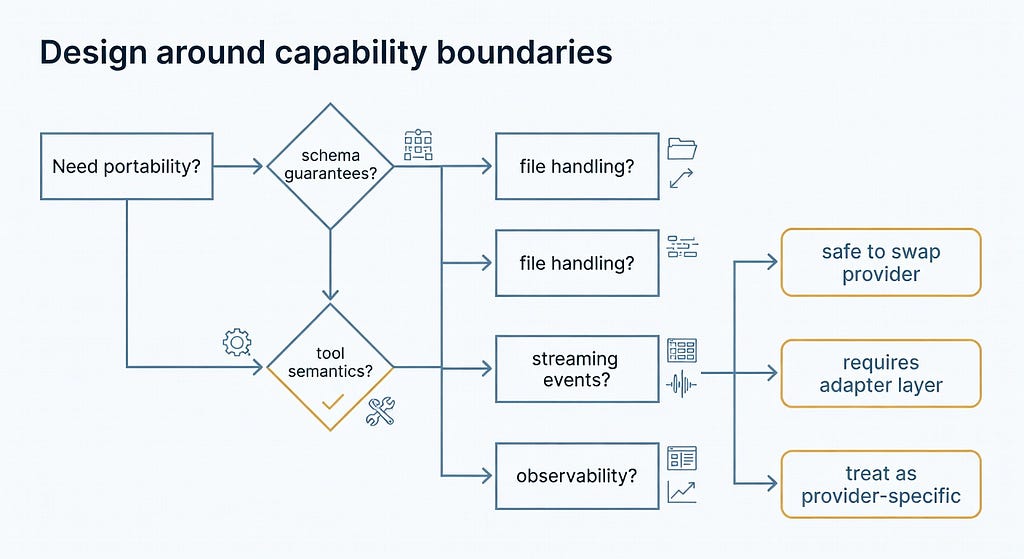
The sane approach isn’t “swap the base URL.” It’s mapping explicit capability boundaries before production traffic finds the rough edges for you.
What I Do Now Instead
I’m probably oversimplifying, but here’s the model I use now: portability is selective, not universal.
I assume basic text generation may port. I assume everything else must be proven.
So before I swap a base_url, I build a capability matrix for the exact provider-model pair I want to use. Not the provider in general. Not the marketing page. The exact route and model. I want answers for:
- strict structured outputs vs prompt-level JSON only
- non-streaming and streaming behavior
- tool calling round-trip, including replay after tool results
- reasoning field names and whether wrappers preserve them
- file upload, file reference, and file use during streaming
- error schema and request IDs
- rate-limit headers and cloud-specific limits
This sounds tedious because it is. But it’s less tedious than a Friday night rollback.
I also keep provider-specific adapters thin and explicit. Not giant framework forks — just enough code to normalize the parts I actually depend on. If one provider needs reasoning, another needs reasoning_content, and a third drops both, I’d rather handle that in a small adapter than pretend a generic abstraction solved it for me.
And I test the edges first. Structured output before freeform chat. Tool loops before plain completions. File-plus-streaming before “hello world.” The Hivenet buyer guide is right that you should verify endpoints, SSE, errors, and headers (guide). My only addition is that those checks are table stakes. The real preflight is failure-mode testing on the features your app cannot live without.
Here’s where the rubber meets the road.
The Architectural Reality
The phrase “OpenAI-compatible” still has value. I’m not saying it’s meaningless.
It’s useful shorthand for transport-level familiarity: SDKs connect, routes look familiar, auth is similar, and simple chat flows often work. That’s real. It saves time. It lowers switching costs at the start.
But if you treat it as a promise of production portability, you’re going to get burned.
What I’m seeing now is a market converging on partial compatibility plus explicit escape hatches. LangChain is shipping provider-specific packages instead of overloading ChatOpenAI (#34328). AI tooling is increasingly exposing provider-specific integrations because providers differ in ways that matter. Even the Ollama story fits that pattern: there is active work toward structured outputs for thinking models, but the gap between “OpenAI-style endpoint” and “reliable production contract” is still very much with us (#11691).
That’s not failure. It’s honesty.
And this part still trips teams up: the abstraction is most convincing right before it fails. The first request works. The demo works. The migration script works. Then the app asks for one strict schema, one PDF, one streamed tool loop — and the fiction ends.
As of 2026–03–10, I no longer buy “OpenAI-compatible” as a guarantee of portability in production. I buy it as a starting point — and then test the contracts that really matter. This is already happening in my own pipelines.
OpenAI-Compatible Is Becoming a Fiction We Keep Paying For — The Production Edges That Break in… was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.