![Demystifying RF-DETR [ICLR 2026]: A Real-Time Transformer Pushing the Limits of Object Detection](https://www.digitado.com.br/wp-content/uploads/2026/03/1bssGkhOvPFDRUqp_UxznrA-oFdytR-978x400.jpg "Demystifying RF-DETR [ICLR 2026]: A Real-Time Transformer Pushing the Limits of Object Detection")
Demystifying RF-DETR [ICLR 2026]: A Real-Time Transformer Pushing the Limits of Object Detection
RF‑DETR: Neural architecture search for real-time detection transformers. The first real-time detector to surpass 60 mAP on COCO [1].

RF-DETR has been accepted to ICLR 2026 (International Conference on Learning Representations).
Introduction
In recent years, neural networks have achieved remarkable progress in many computer vision tasks.
In particular, in the field of object detection, there are super-fast models that can be used in high-performance applications where inference speed is crucial. Examples of such real-time object detectors include variants of the YOLO family, with the latest release, namely YOLO26 [2], as well as transformer-based detectors like D-FINE [3], RT-DETR [4] and LW-DETR [5]. However, these real-time object detectors generalize poorly to real-world datasets and often need careful tuning of learning rate schedulers and augmentations to achieve competitive performance [1].
At the same time, Vision Language Models (VLMs) have emerged and demonstrate remarkable zero-shot performance at the cost of inference speed. Examples include GroundingDINO [6] and YOLO-World [7]. Despite their strong transfer learning capabilities, these models still struggle to generalize to out-of-distribution classes, tasks and imaging modalities not typically seen during pre-training and require further fine-tuning to achieve optimal performance on downstream tasks [1].
RF-DETR is introduced as a lightweight detection transformer that leverages internet-scale pre-training and weight-sharing neural architecture search (NAS) [15] to achieve strong performance on both standard benchmarks and more diverse, real-world data distributions. The paper proposes a family of scheduler-free, NAS-based detection and segmentation models that outperform prior state-of-the-art, real-time methods (with latencies ≤ 40 ms) on COCO and on the Roboflow100-VL benchmark [1]. The authors claim that, RF-DETR is the first real-time detector to exceed 60 mAP on COCO [1], setting a new state-of-the-art for efficient detection transformers.
In this post, we will explain the key advancements of RF-DETR and some additional contributions introduced in the paper.
Prior Work
To evaluate the contributions of the paper, we will first review some prior work and current advancements in the field of object detection.
Real-Time CNN-based Detectors
Traditionally, object detectors were composed of two stages: region proposal extraction and classification–bounding box refinement. Representative examples include Faster-RCNN [8] and Mask-RCNN [9]. While these detectors achieved strong performance, this came at the cost of slower inference.
Single-stage detectors, such as the Single Shot MultiBox Detector (SSD) [10] and the YOLO [11] series, subsequently emerged, offering faster inference by sacrificing accuracy.
Recent YOLO variants focus on improving both accuracy and inference time, achieving remarkable performance with reduced latency through advanced techniques such as data augmentation, optimized training settings, and architectural innovations, making them increasingly adopted in high-performance applications. However, these detectors rely on Non-Maximum-Suppression (NMS) [12] to eliminate redundant bounding boxes, which introduces additional latency
The latest variant of YOLO, YOLO26 [2], introduces key architectural enhancements that eliminate the need for Non-Maximum Suppression (NMS), adopting an NMS-free approach.
Transformer-based Detectors
All detectors described in the previous paragraph are CNN-based. With the proliferation of transformers, transformer-based detectors emerged, surpassing many real-time CNN detectors in accuracy, but at the cost of increased inference time.
These approaches were initiated with the DEtection TRansformer (DETR [13]), which streamlines the detection process by effectively removing the need for many hand-designed components, such as Non-Maximum Suppression (NMS) and anchor box generation. It employs a set-based global loss that forces unique predictions via bipartite matching and a transformer encoder-decoder architecture [13]. Given a fixed, small set of learned object queries, DETR uses the transformer’s self-attention mechanism to model both the relationships between objects and the overall context of the entire image, enabling it to directly predict the final set of detections in parallel. While DETR achieved strong performance, its increased latency limited its use in real-time applications.
The image below illustrates the DETR architecture. DETR uses a conventional CNN backbone to extract a 2D feature representation of an input image. The feature map is flattened and combined with positional encodings before being passed to a transformer encoder. The transformer decoder takes a small, fixed set of learned positional embeddings, called object queries, and attends to the encoder output. Each decoder output embedding is then fed into a shared feed-forward network (FFN), which predicts either an object (class and bounding box) or a “no object” (∅) class.
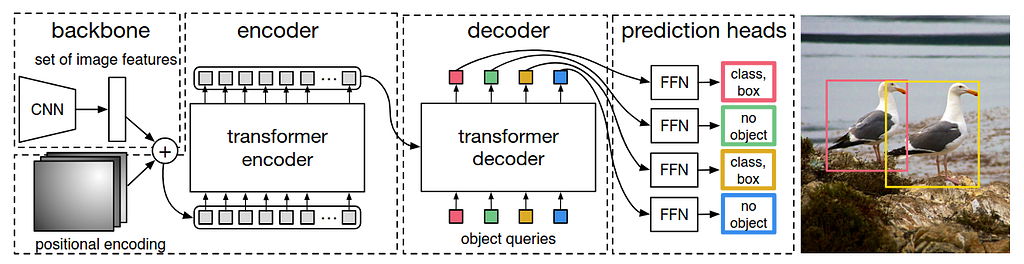
DETR predicts the final set of detections directly and in parallel by combining a CNN backbone with a transformer architecture, as shown in the following image. During training, bipartite matching uniquely assigns each prediction to a ground-truth box. Predictions that are not matched are assigned a “no object” (∅) class. Because each ground-truth object is assigned to exactly one prediction, the model is trained as a set prediction problem, therefore DETR avoids duplicate detections, making traditional post-processing steps like Non-Maximum Suppression (NMS) unnecessary.

Real-Time Transformer-based Detectors
Recent publications, such as D-FINE [3], RT-DETR [4] and LW-DETR [5] have adapted DETR for real-time applications.
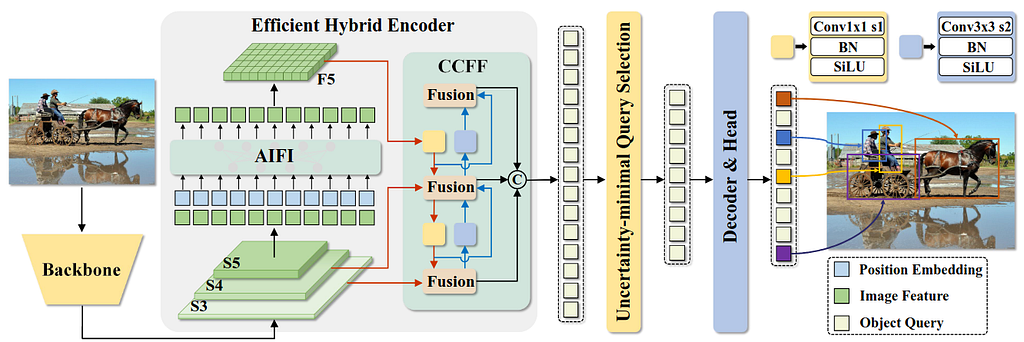
Real-Time DEtection TRansformer (RT-DETR [4]) is the first transformer-based object detector optimized for real-time applications. It builds on DETR by maintaining strong detection accuracy while significantly improving inference speed [4]. RT-DETR achieves this through several key innovations. First, it employs an efficient hybrid encoder that processes multi-scale features by separating intra-scale interactions from cross-scale fusion, reducing computational overhead and speeding up feature encoding. Second, it introduces uncertainty-minimal query selection, which identifies high-quality initial object queries for the decoder, enhancing detection accuracy. Finally, RT-DETR supports flexible speed tuning by adjusting the number of decoder layers, the model can balance speed and accuracy to adapt to different scenarios without requiring retraining.
The image below highlights the architecture of RT-DETR. Features from the last three stages of the backbone are fed into the encoder. The efficient hybrid encoder converts these multi-scale features into a sequence of image features using Attention-based Intra-scale Feature Interaction (AIFI) and CNN-based Cross-scale Feature Fusion (CCFF). Next, the uncertainty-minimal query selection module picks a fixed number of encoder features to serve as initial object queries for the decoder. Finally, the decoder, equipped with auxiliary prediction heads, iteratively refines the object queries to predict both object categories and bounding boxes.
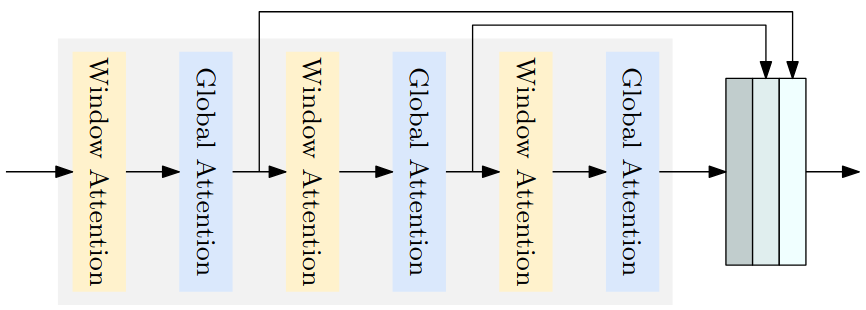
LW-DETR [5] is a light-weight detection transformer, which outperforms CNN-based real-time object detectors. Its architecture consists of a Vision Transformer (ViT) encoder, a projector and a shallow DETR decoder [5]. LW-DETR incorporates several advanced techniques to improve both accuracy and efficiency. First, it uses training-effective methods, including improved loss functions and pretraining strategies, to enhance model convergence and detection performance. Second, it reduces the computational complexity of the ViT encoder by employing interleaved window and global attentions, which efficiently capture both local and global context. Additionally, LW-DETR aggregates multi-level feature maps, combining intermediate and final representations of the ViT encoder to produce richer feature representations for downstream detection. To further improve computational efficiency, it introduces a window-major feature map organization, which optimizes the interleaved attention computation and reduces memory overhead. These innovations enable LW-DETR to deliver accurate detection while maintaining real-time inference speed.
The following image shows an example of a transformer encoder that aggregates multi-level feature maps and alternates between window and global attention.
D-FINE [3] is a powerful real-time object detector that achieves remarkable localization precision by redefining the bounding box regression task of
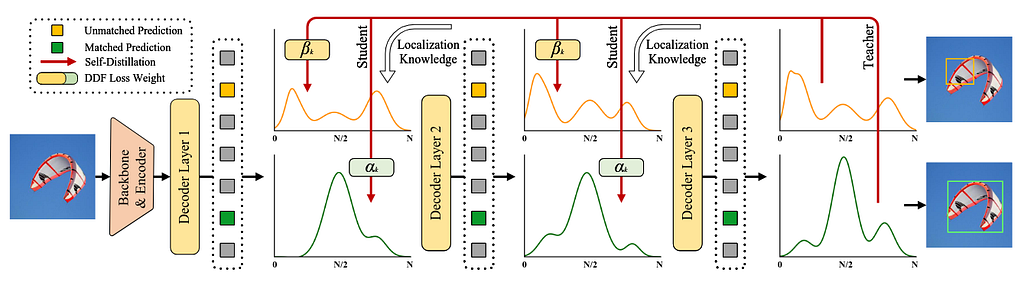
DETR [3]. D-FINE consist of two key components: Fine-grained Distribution Refinement (FDR) and Global Optimal Localization Self-Distillation (GO-LSD) [3]. Instead of predicting fixed bounding box coordinates, FDR iteratively refines probability distributions, creating a fine-grained intermediate representation that significantly improves localization accuracy. GO-LSD transfers localization knowledge from refined distributions to shallower layers via self-distillation, while simultaneously simplifying the residual prediction tasks for deeper layers.
The image below illustrates the FDR process in D-FINE. Probability distributions, serving as a fine-grained intermediate representation, are iteratively refined by the decoder layers in a residual manner.

The following image demonstrates the GO-LSD process in D-FINE. Localization knowledge from the final layer’s refined distributions is distilled into shallower layers using the Decoupled Distillation Focal (DDF) loss with decoupled weighting strategies.
YOLOv12 [14] is an attention-centric real-time object detector, which maintains the high inference speed of previous CNN-based detectors, while leveraging the representational power of attention mechanisms. By incorporating attention modules, YOLOv12 can more effectively capture long-term and contextual relationships in the image, leading to improved detection without sacrificing real-time performance.
Overall, these models demonstrate that transformer-based detectors are capable of real-time object detection.
Neural Architecture Search (NAS)
Neural Architecture Search (NAS) [15] is a method for automatically designing neural network architectures, rather than manually selecting the model’s structure (e.g., feed forward/convolutional layers, filters, attention heads, decoding layers, dropout rates, etc.). Its goal is to identify networks that achieve optimal performance for a given task. Many prior works utilized NAS primarily to maximize accuracy, often resulting in computationally expensive architectures.
One of the earliest approaches for automatically designing neural networks utilized a recurrent neural network (RNN) to generate neural network architectures [15]. The RNN was trained with reinforcement learning to propose architectures that maximize performance (e.g., accuracy).
NASNet [16] searches for small building blocks on a small dataset and then transfers them to larger datasets for scalable image recognition. This approach improves search efficiency and produces architectures that generalize well across datasets.
ENAS [17] further reduces computational cost by sharing parameters among candidate architectures during the search process, avoiding the need to train each candidate from scratch.
OFA [18] introduces a Once-For-All (OFA) network, a weight-sharing NAS approach that decouples training and search by simultaneously optimizing thousands of sub-networks. After training, a specialized sub-network can be directly retrieved from the OFA network without additional training, significantly reducing computational cost.
All these methods illustrate that NAS is a powerful tool for designing neural networks, and weight-sharing NAS makes it feasible to efficiently discover high-performing architectures.
Methodology
In this section, we will explain the key architectural advancements introduced in RF-DETR.
RF-DETR builds on LW-DETR [5], combining the fast inference of real-time detectors with the internet-scale priors of VLMs to achieve state-of-the-art performance [1]. Inspired by OFA [18], RF-DETR leverages NAS to automatically identify families of architectures, optimized for different accuracy–latency tradeoffs [1]. It discovers these architectures by systematically exploring architectural variants within a predefined search space, evaluating how design choice affects both model performance and inference speed.
1. RF-DETR Architecture
The architecture of RF-DETR is illustrated in the following image.

Encoder
RF-DETR employs a pre-trained Vision Transformer (ViT) backbone [21], DINOv2 [20], to extract rich multi-scale features from the input image. The input image is first divided into 14×14 patches (patch size 14), which are linearly projected into tokens. Positional embeddings are added to each token to preserve spatial information that would otherwise be lost when flattening the 2-D image into a 1-D sequence.
In the following image, the architecture of the vision transformer (ViT) is shown. Input image is first divided into fixed-size patches, which are flattened and linearly projected into patch embeddings. Positional embeddings are added to preserve spatial information. The resulting sequence of tokens is then processed by a standard Transformer encoder. Through self-attention, each token can attend to all others, allowing it to capture information from the entire image rather than only its local neighborhood. In ViT, multi-head attention is utilized, with multiple self-attention heads operating in parallel, allowing the model to attend to different relationships between image patches simultaneously.

To balance detection accuracy and computational efficiency, the RF-DETR architecture interleaves windowed and global (non-windowed) attention blocks in the ViT encoder (ViT backbone). Window Attention, introduced in Swin Transformer [22], enables self-attention to scale efficiently to high-resolution inputs, particularly in computer vision tasks. In global (non-windowed) attention every token attends to all other tokens, which causes computational complexity to grow rapidly with input resolution. In contrast, windowed attention splits the image into smaller windows and computes self-attention only within each window, significantly reducing computational cost while preserving local context. These two attention mechanisms complement each other by balancing computational efficiency with the ability to capture global context.
- Windowed attention: Computes self-attention within small local regions, reducing computational complexity while capturing local relationships.
- Global (non-windowed) attention: Captures long-range dependencies and preserves global context.
By utilizing both windowed and global (non-windowed) attention blocks, the model captures local details and global context, effectively balancing accuracy and latency.
Projector
A projector in RF-DETR, implemented as a C2f block, an efficient convolutional block introduced in YOLOv8 [24], takes the encoded features as input and aggregates them into compact, multi-scale representations suitable for the decoder.
Bilinear Up-sampling
Furthermore, both the deformable cross-attention layers [23] in the decoder and the segmentation head rescale the output of the projector using bilinear interpolation (bilinear up-sampling), ensuring consistent spatial alignment and feature map resolution across different stages of the network.
Query Selection
A mixed-query selection scheme [26] is employed to create the object queries by combining content queries and spatial queries [5]. The content queries consist of learnable embeddings that capture semantic information about potential objects. In contrast, the spatial queries are generated using a two-stage process: top-K features are first selected from the final layer of the projector, preliminary bounding boxes are predicted from these features, and the corresponding bounding box coordinates are then transformed into embeddings that encode spatial priors. This combination provides both semantic and localization cues, improving query initialization and overall detection performance.
The mixed query selection strategy is illustrated in the image below. The encoder processes input tokens and the query selection module extracts dynamic spatial queries (top-K features converted into spatial embeddings) while static content queries provide semantic information that remains fixed across images. These two types of queries are combined and fed into the decoder. The term static means that these queries remain fixed across all images during inference.
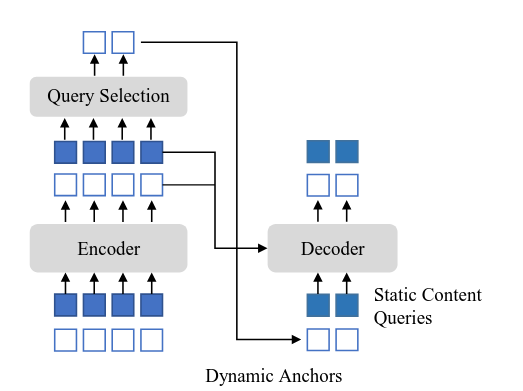
Decoder
The RF-DETR decoder consists of a stack of transformer decoder layers, organized into decoder groups [25]. These groups implement a one-to-many assignment strategy and perform self-attention separately, which is architecturally equivalent to parallel decoders [25].
Grouped queries refer to dividing the queries into multiple sets, where each group independently predicts objects using the same decoder. One-to-one assignment within a group means that each ground-truth object is assigned to a single prediction that is considered the most accurate among that group’s predictions (bipartite matching). As a result, information only needs to be gathered from predictions within the same group, rather than across all groups, thus self-attention is performed over queries for each group separately [25].
Multiple decoder groups allow the model to independently refine several sets of object queries in parallel. These decoders share the same parameters while benefiting from stronger supervision during training. At inference, only a single group of queries is used, but training with multiple groups accelerates convergence and improves detection performance.
The group-wise one-to-many assignment is illustrated in the following image. The decoder consists of K parallel decoders (decoder groups) that share parameters, with no interaction between queries from different groups. This design is called the Group Decoder [25]. Each group of queries predicts multiple outputs in parallel. Across groups, multiple predictions can correspond to the same ground-truth object, implementing a one-to-many assignment that provides redundancy and improves the likelihood of accurate detection. Although K groups exist during training, only one group is used during inference, ensuring efficient prediction without changing the model architecture.
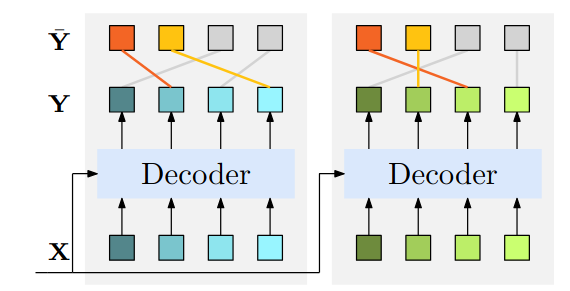
Equivalent to Parallel Decoder), Source: Group DETR: Fast DETR Training with Group-Wise One-to-Many Assignment
Each decoder layer in RF-DETR includes self-attention for interactions between queries, deformable cross-attention [23] to efficiently sample multi‑scale features from the image, and feed-forward networks for prediction refinement. Queries are iteratively updated at each layer, improving both bounding box localization and class predictions.
Deformable attention layers [23] attend only to a small, learnable set of key sampling points around each reference location. These key points are deformable, which means that the model learns offsets to adjust them slightly for capturing the most relevant local information. This design reduces computational cost compared to standard attention while still preserving important local details and spatial structure. By leveraging multiple reference points, the model can also effectively capture long-range dependencies.
The following image illustrates the deformable attention module [23]. The query feature generates sampling offsets and attention weights via linear layers. These offsets define adaptive spatial locations on the input feature map and are used to sample values from multiple attention heads. Sampled values are aggregated using the learned attention weights to produce the final output.

The image below highlights the architecture of Deformable DETR [23]. The deformable attention module can be naturally extended to aggregate multi-scale features without relying on a Feature Pyramid Network (FPN). In fact, multi-scale deformable attention modules can directly replace standard transformer attention modules when processing feature maps.
The encoder uses multi-scale deformable self-attention to extract features from different resolution levels simultaneously. The decoder employs multi-scale deformable cross-attention to attend to relevant spatial locations across scales, when generating object queries. This hierarchical processing enables the model to efficiently capture both fine-grained details and global context, ultimately producing accurate bounding box predictions for objects at various scales.
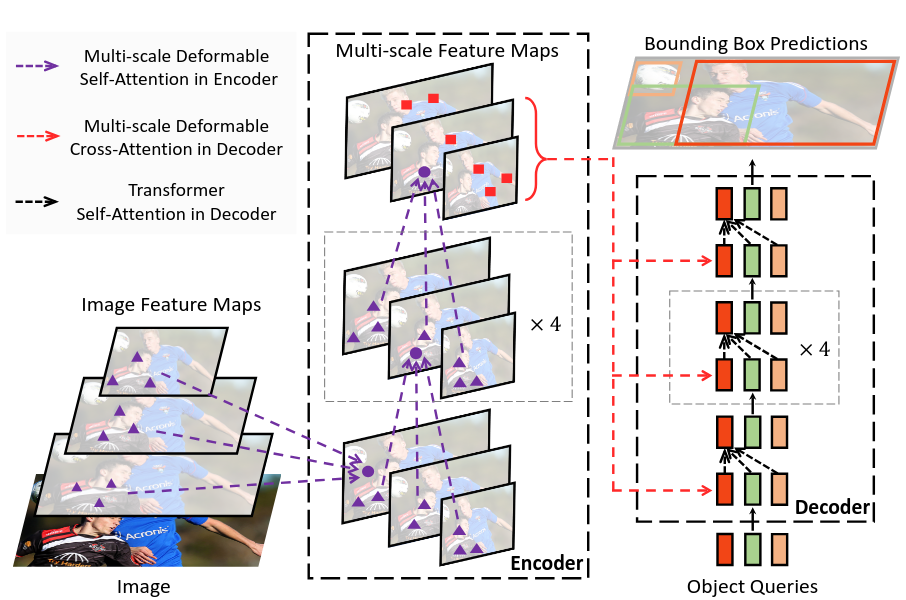
RF-DETR builds upon this architecture, but unlike Deformable DETR, which employs a multi-scale feature extraction strategy, RF-DETR relies on a single-scale backbone output, simplifying the feature hierarchy while still leveraging the deformable attention mechanism.
Detection and Segmentation Heads
Finally, dedicated detection and segmentation heads produce the final predictions for each task. The detection head consists of a classification head for predicting object categories and a regression head for estimating bounding box coordinates. Since predictions are generated in a set-based manner and are inherently unique, Non-Maximum Suppression (NMS) is not required.
The segmentation head leverages the same shared features in parallel, to support instance segmentation with minimal additional computational cost, employing depth-wise convolutions to maintain efficiency.
Detection and segmentation losses in RF-DETR are applied at every decoder layer, providing deep supervision during training and enabling decoder layer dropout at inference time.
Moreover, RF-DETR is pre-trained on the Objects-365 dataset to achieve better performance.
Finally, gradient accumulation is utilized by replacing Batch Normalization with Layer Normalization in the multi-scale projector, which facilitates training on GPUs with limited memory.
2. DINOv2 Backbone — Internet-Scale Priors
RF-DETR advances LW-DETR [5] by modifying both its architecture and training procedure to improve generalization to real-word data distributions. Specifically, CAEv2 [19] backbone used in LW-DETR [5] is replaced with DINOv2 [20].
DINOv2 is a foundational Vision Transformer pre-trained on a large amount of curated data collected from diverse sources using self-supervised learning. It produces general-purpose visual features that transfer well across different image distributions and downstream tasks, often without task-specific fine-tuning. By utilizing DINOv2’s pre-trained weights, RF-DETR benefits from strong internet-scale priors, which significantly improve detection performance, particularly on small datasets through transfer learning.
The CAEv2 encoder consists of 10 layers with a patch size of 16, whereas DINOv2 encoder comprises 12 layers with a patch size of 14. Although the DINOv2 backbone is deeper and introduces higher computational cost compared to CAEv2, the additional latency is compensated through the use of NAS technique.
3. Real-Time Instance Segmentation
RF-DETR employs a lightweight instance segmentation head to additionally predict segmentation masks.
As mentioned above, the low-resolution feature map produced by the encoder is up-sampled using bilinear interpolation to ensure consistent spatial alignment and feature map resolution. A lightweight projector then generates a pixel embedding map, representing the visual features at each spatial location. Segmentation masks are produced by computing the dot product between all projected query token embeddings (the output of each decoder layer transformed through a feed-forward network (FFN)) and the pixel embedding map. These pixel embeddings can be interpreted as segmentation prototypes [1].
To minimize latency, multi-scale backbone features are not used in the segmentation head. Additionally, RF-DETR is pre-trained on the Objects-365 dataset using pseudo-labels (instance masks) generated by SAM2 [27] to further improve performance.
4. End-to-End Neural Architecture Search (NAS)
RF-DETR is the first object detector to leverage weight-sharing NAS for end-to-end object detection and segmentation [1].
Inspired by OFA [18], RF-DETR utilizes dynamic input configurations (e.g., image resolution) and architectural components (e.g., patch size) during training. Additionally, weight-sharing NAS enables the modification of inference configurations, such as the number of decoder layers and query tokens, allowing the base model to specialize for different scenarios without additional fine-tuning. In contrast, several approaches apply NAS to object detection by simply replacing standard backbones with NAS backbones, within existing detection frameworks.
Unlike prior work, RF-DETR directly optimizes end-to-end object detection accuracy to find Pareto optimal accuracy-latency tradeoffs for any target dataset. To achieve this, it evaluates thousands of model configurations with different input image resolutions, patch sizes, window attention blocks, decoder layers, and query tokens. During training, a random model configuration is uniformly sampled at each iteration and a gradient update is performed, enabling thousands of sub-networks to be trained in parallel. At inference, several model configurations with different number of parameters and latencies are evaluated without additional fine-tuning. The optimal configurations are then selected based on Pareto optimal accuracy-latency trade-offs. This process effectively acts as architecture augmentation, serving as a regularizer that improves generalization [1].
Pareto curves are used to visualize the trade-off between model performance and inference speed. They represent a set of non-dominated models, where no other model can simultaneously achieve higher accuracy and lower latency.
The “tunable knobs” of weight-sharing NAS are illustrated in the following image. Adjusting each of these parameters introduces a trade-off between performance and computational efficiency. Specifically, the “tunable knobs” in RF-DETR include:
- (a) Patch Size: RF-DETR interpolates between patch sizes during training. Smaller patch sizes generally improve detection performance by preserving finer spatial details, but they also increase computational cost due to a larger number of tokens.
- (b) Number of Decoder Layers: Regression loss is applied to all decoder layers during training, enabling deep supervision. Consequently, any decoder layer can be removed at inference time to reduce latency. Removing the entire decoder during inference effectively converts RF-DETR into a single-stage detector [1].
- (c) Number of Queries: Query tokens are dropped at inference time to limit the maximum number of detected objects and decrease computational cost. The optimal number of queries implicitly encodes dataset statistics about the average number of objects per image in a target dataset [1].
- (d) Image Resolution: RF-DETR pre-allocates N positional embeddings corresponding to the largest image resolution divided by the smallest patch size. These embeddings are interpolated for smaller resolutions or larger patch sizes. Higher image resolutions typically improve performance, especially for small objects, but increase inference latency.
- (e) Number of Windows per Attention Block: As explained before, windowed attention restricts self-attention within small local regions, reducing computational complexity. Adjusting the number of windows per block balances accuracy, computational efficiency and the model’s ability to capture global context.

5. Training Schedulers and Augmentations Bias Model Performance
Several state-of-the-art detectors require careful hyper-parameter tuning to achieve optimal performance, which can introduce biases toward specific datasets. For example, cosine learning rate schedules assume a fixed optimization horizon [1]. Similarly, data augmentations can introduce biases by relying on prior knowledge of dataset characteristics.
To eliminate dataset biases RF-DETR limits augmentations to horizontal flips and random crops. Additionally, images are resized at batch level to minimize padded pixels per batch and to expose the model to a wide range of positional encoding resolutions during training, enabling it to handle inputs of varying sizes effectively.
6. Standardized Benchmarking Protocol for Measuring Latency
RF-DETR introduces a standardized benchmarking protocol for measuring latency to improve reproducibility. This protocol includes pausing for 200ms between consecutive forward passes during inference, which helps mitigate GPU power throttling (caused by GPU overheating) and ensures that latency measurements are not artificially skewed by hardware constraints. Additionally, potential sources of unfair evaluation between models are eliminated, such as omitting non-maximum suppression (NMS) or reporting latency using lower precision settings.
Experiments
RF-DETR achieves state-of-the-art performance among real-time methods on both COCO and RF100-VL benchmarks.
Benchmarks
RF-DETR is evaluated on the COCO dataset to compare its performance with prior methods and on RF100-VL dataset to assess generalization to real-world scenarios. The RF100-VL comprises 100 diverse datasets and performance on this benchmark can serve as a proxy for transferability to any target domain [1].
Experimental Results
The accuracy-latency Pareto curves in the following figure show that RF-DETR consistently achieves the highest accuracy across COCO and RF100-VL benchmarks for both detection and segmentation, while maintaining competitive inference speeds.
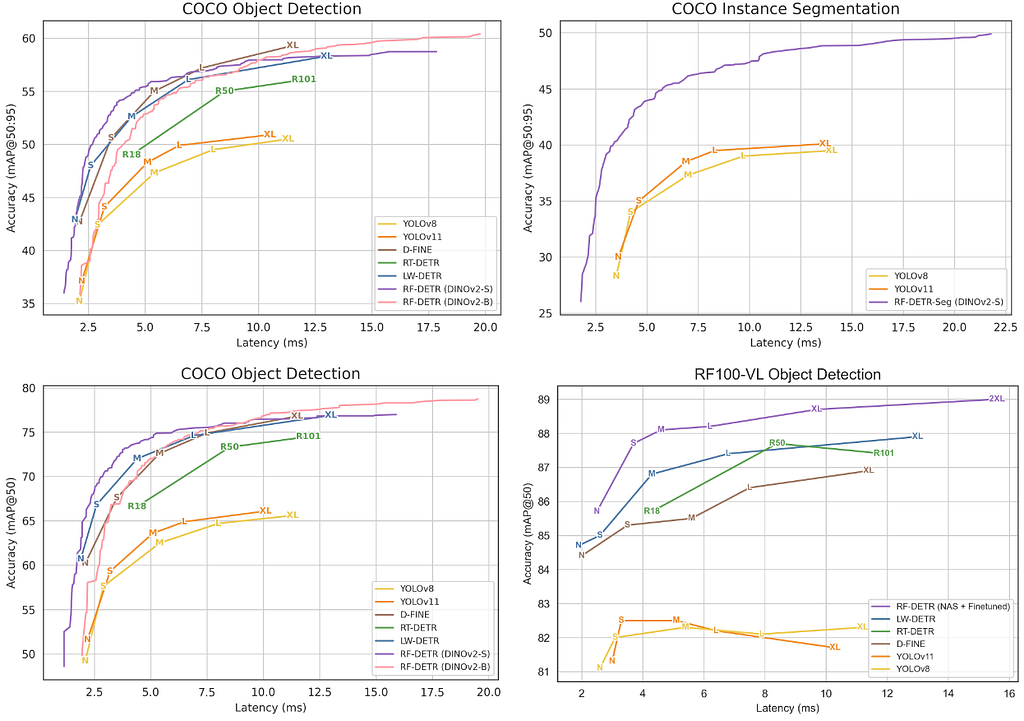
The figure below presents more comprehensive results, showing that RF-DETR outperforms real-time object detection models on both benchmarks.

The following figure shows that RF-DETR outperforms real-time instance segmentation models on the COCO benchmark.

RF-DETR is compared with popular real-time and open-vocabulary object detectors on the COCO dataset in the table below. RF-DETR-Nano outperforms D-FINE-Nano and LW-DETR-Tiny by more than 5 AP (Average Precision). Additionally, RF-DETR significantly surpasses YOLOv8 and YOLOv11, while its nano variant achieves performance comparable to YOLOv8-Medium and YOLOv11-Medium models.
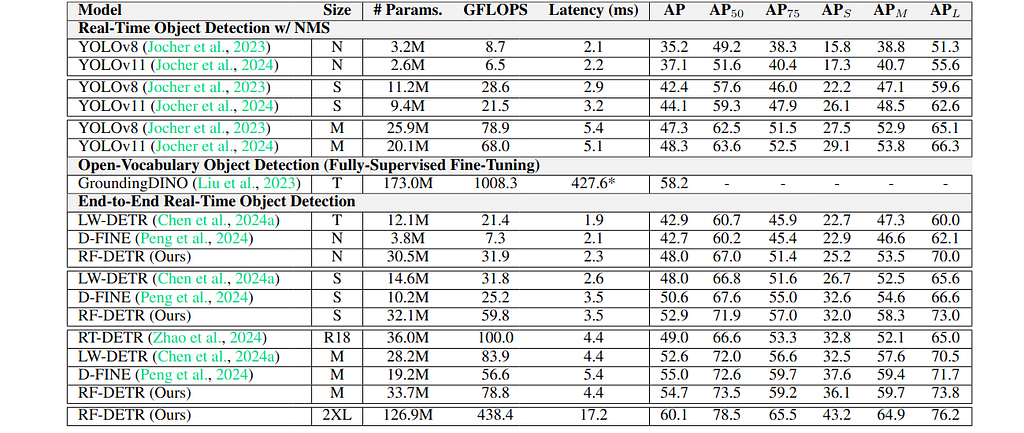
RF-DETR is compared with popular real-time instance segmentation methods on the COCO dataset in the table below. RF-DETR-Nano outperforms all reported YOLOv8 and YOLOv11 model sizes. Additionally, RF-DETR-Nano surpasses FastInst by 5.4% while running nearly ten times faster. RF-DETR-Medium approaches the performance of MaskDINO while requiring significantly less inference time.

RF-DETR is also compared with popular real-time and open-vocabulary object detectors on the RF100-VL benchmark. RF-DETR-2X-large outperforms GroundingDINO-Tiny and LLMDet-Tiny with much lower computational cost. It is also worth mentioning that RF-DETR benefits from scaling to larger backbone sizes.
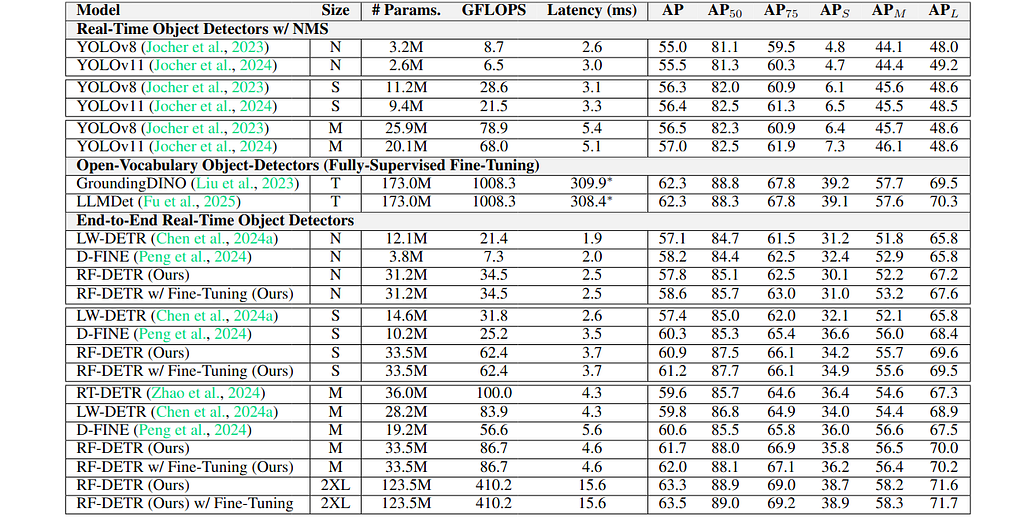
The impact of each “tunable knob” on accuracy and latency is illustrated below. Using a gentler set of hyperparameters compared to LW-DETR (e.g.,
smaller batch size, lower learning rate, replacing batch normalization with layer normalization) reduces performance by approximately 1%. However, this loss is recovered by replacing LW-DETR’s CAEV2 backbone with DINOv2. The lower learning rate and layer normalization better preserve DINOv2’s foundational knowledge and enable training with larger batch sizes, making weight-sharing NAS more effective. The final model with weight-sharing NAS improves over LW-DETR by 2% without increasing latency.

The impact of using different backbone architectures for RF-DETR is shown below. DINOv2 achieves the highest performance, outperforming CAEv2 by 2.4%. All models are pre-trained with 60 epochs of Objects-365 and the “Gentler Hyper-parameters” setting.

The Pareto optimal RF-DETR and RF-DETR-Seg configurations are presented in the following tables.


The sampling grid for training and inference are shown below. Decoder layers and queries are removed only during inference. During training, configurations are uniformly sampled. During inference a grid search over all configurations is performed to identify Pareto optimal model configurations.
The total training time is roughly 2–4 times longer than that of a non-NAS baseline, depending on the target dataset. However, RF-DETR can generate all size configurations from this single training run, whereas non-NAS baselines must be re-trained for each new model size. During architecture search, 6,468 network configurations (11 resolutions * 7 patch sizes
* 7 decoder layers * 3 windows * 4 query settings) are evaluated. This search required approximately 10,000 GPU Hours (200 T4 GPUs * 48 hours).

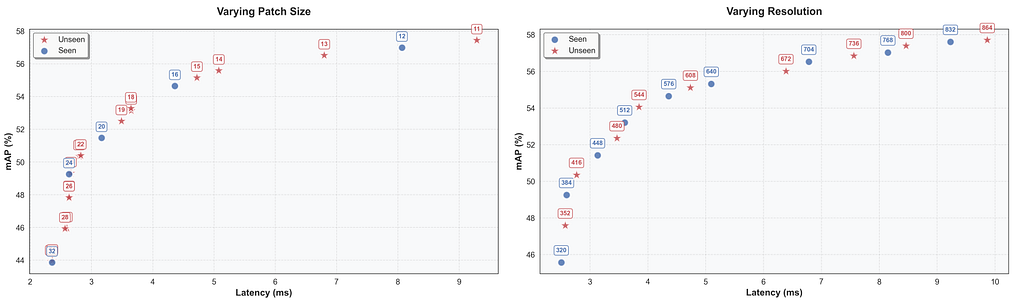
The impact of varying resolution and patch size is illustrated in the following figure. RF-DETR can interpolate between seen configurations (blue circles) and unseen configurations (red stars) during inference. The performance of unseen configurations closely follows the trend established by seen configurations, demonstrating that RF-DETR generalizes beyond the model configurations encountered during training.
Fine-tuning after NAS offers limited gains on the COCO dataset, as shown in the table below. Moreover, the NAS-based architecture augmentation serves as a strong regularizer and additional training without this regularization can degrade performance [1].
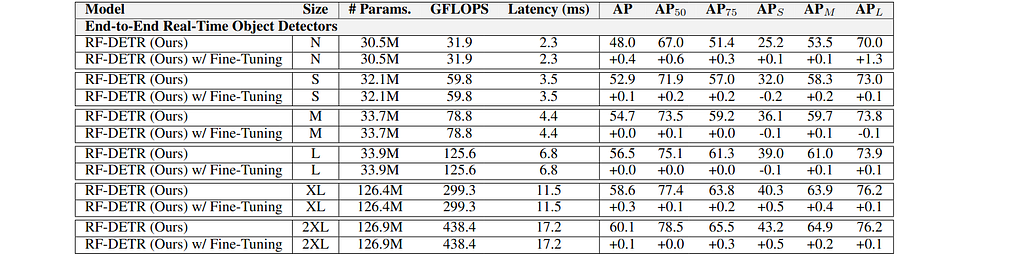
Models trained on RF100-VL benefit more from fine-tuning, because convergence requires more than 100 epochs. In such cases, performance can be improved by either reducing the total number of NAS configurations during training or extending training beyond 100 epochs with weight-sharing NAS [1].
The impact of transferring a NAS architecture optimized for COCO to RF100-VL is illustrated in the following figure. Although the fixed architecture was not tuned for RF100-VL, it performs remarkably well without further dataset-specific NAS, outperforming LW-DETR.
However, applying dataset-specific NAS (yellow line) yields significant improvements over the fixed architecture. Additional fine-tuning (purple line) provides consistent gains across all model sizes, with particularly strong improvements for smaller models.

Additional experimental results are available in the RF-DETR paper [1].
Main Contributions
The main contributions of RF-DETR paper are summarized below.
- A family of scheduler-free, NAS-based, real-time detection and segmentation models.
- Outperforms prior state-of-the-art, real-time methods (with latencies ≤ 40 ms) on COCO and on the Roboflow100-VL benchmark [1]. RF-DETR is the first real-time detector to exceed 60 mAP on COCO [1].
- Utilizes end-to-end weight-sharing neural architecture search (NAS) to
improve accuracy-latency tradeoffs (evaluates thousands of network configurations without retraining). - Leverages internet-scale pre-training and effectively transfers to small datasets (DINOv2 backbone and “tunable knobs” for weight-sharing NAS).
- Revisits current benchmarking protocols for measuring latency and propose a simple standardized procedure to improve reproducibility.
Additional Contributions
Some additional contributions of RF-DETR paper are highlighted below.
- Utilizes DINOv2 backbone with lower learning rate to preserve pre-trained knowledge.
- Enhances DETR-based model latency and generalization using NAS.
- Employs gradient accumulation by using layer normalization instead of batch normalization to facilitate training on GPUs with limited memory.
- Detection and segmentation losses are applied at every decoder layer, providing deep supervision during training and enabling decoder layer dropout at inference time.
- Avoid incorporating multi-scale features in segmentation head to minimize latency.
- Pre-train models on Objects-365 benchmark. Generate pseudo-labels (instance segmentation masks) with SAM2.
- Limit data augmentations to avoid bias the model toward dataset certain characteristics.
- Resize images at batch level to minimize padded pixels per batch.
- NMS-free object detector (similar to DETR).
Additional Thoughts
Some speculations introduced in RF-DETR paper are summarized below.
- Although fine-tuned VLMs outperform real-time object detectors, they are prohibitively slow models for real-time applications.
- Real-time object detectors are over-optimized for COCO. They generalize poorly to real-world datasets and often require careful hyper-parameter tuning to achieve competitive performance.
- Training schedulers and augmentations bias model performance.
- VLMs struggle to generalize to out-of-distribution classes, tasks and imaging modalities not seen during pre-training and require further fine-tuning to achieve optimal performance on downstream tasks.
- Benchmarking protocols for measuring latency lack reproducibility due to GPU power throttling (caused by GPU overheating) during inference and unfair evaluation between models (omitting non-maximum-suppression (NMS), reporting latency using lower precision settings, etc.).
Conclusion
To sum up, RF-DETR represents a remarkable breakthrough in computer vision, pushing the limits of real-time object detection and segmentation. The combination of high accuracy and low latency makes it a powerful tool for real-world applications.
Discover more of my AI projects online
If you enjoyed this post and want to explore more of my projects, you can find me online: Website, LinkedIn, Linktree.
References
[1] RF-DETR: Neural Architecture Search for Real-Time Detection Transformers
[2] YOLO26: Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection
[3] D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement
[4] DETRs Beat YOLOs on Real-time Object Detection (RT-DETR)
[5] LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection
[6] Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
[7] YOLO-World: Real-Time Open-Vocabulary Object Detection
[8] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
[9] Mask R-CNN
[10] SSD: Single Shot MultiBox Detector
[11] You Only Look Once: Unified, Real-Time Object Detection (YOLO)
[12] Learning non-maximum suppression (NMS)
[13] End-to-End Object Detection with Transformers (DETR)
[14] YOLOv12: Attention-Centric Real-Time Object Detectors
[15] Neural Architecture Search with Reinforcement Learning
[16] Learning Transferable Architectures for Scalable Image Recognition (NASNet)
[17] Efficient Neural Architecture Search via Parameter Sharing (ENAS)
[18] Once-for-All: Train One Network and Specialize it for Efficient Deployment (OFA)
[19] CAEv2: Context Autoencoder with CLIP Target
[20] DINOv2: Learning Robust Visual Features without Supervision
[21] An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale
[22] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
[23] Deformable DETR: Deformable Transformers for End-to-End Object Detection
[24] Explore Ultralytics YOLOv8
[25] Group DETR: Fast DETR Training with Group-Wise One-to-Many Assignment
[26] DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
[27] SAM 2: Segment Anything in Images and Videos
Additional References (Code-Benchmarks-Blogs)
- RF-DETR Github Repo
- RF-DETR Documentation
- Coco benchmark
- Roboflow100-VL benchmark
- Objects-365 benchmark
- RF-DETR by Roboflow: Speed Meets Accuracy in Object Detection
- RF-DETR Under the Hood: The Insights of a Real-Time Transformer Detection
Demystifying RF-DETR [ICLR 2026]: A Real-Time Transformer Pushing the Limits of Object Detection was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.