
The Architectural Paradigm of Multi-Adapter Inference: A Technical Analysis of LoRAX

The evolution of generative artificial intelligence has moved rapidly from the era of massive, general-purpose foundation models toward a more nuanced landscape of specialized, task-specific intelligence. For the modern AI engineer, the challenge has shifted from simply training a high-performing model to the operational nightmare of serving hundreds or thousands of these models in a production environment. Fine-tuning is no longer a luxury but a requirement for achieving domain-specific accuracy, yet the traditional infrastructure used to serve these models has hit a fundamental scaling wall. This blog provides an exhaustive technical analysis of LoRA Exchange (LoRAX), an open-source inference server designed to disrupt the current serving paradigm by enabling the hosting of thousands of fine-tuned adapters on a single GPU without compromising throughput or latency.
The Infrastructure Bottleneck: The AI Engineer’s Dilemma
At the core of the deployment crisis is the “Dedicated Model Problem.” When an engineer fine-tunes a base model — such as Mistral-7B, Llama-3, or Qwen — using traditional methods, the result is often a full set of new weights that must be loaded into the VRAM of a GPU. A 7-billion parameter model, when served in half-precision (FP16), requires approximately 14 gigabytes of VRAM just to hold the static weights. In a typical enterprise scenario where a SaaS provider might need to offer a custom-tuned model for each of their 1,000 customers, the infrastructure requirements become physically and financially impossible. Providing a dedicated GPU for each customer would necessitate 1,000 instances, leading to millions of dollars in monthly cloud expenditures and massive underutilization, as most models remain idle for significant periods.
The engineering community attempted to solve this using Parameter-Efficient Fine-Tuning (PEFT) techniques, most notably Low-Rank Adaptation (LoRA). LoRA reduces the trainable parameter count by several orders of magnitude, often to less than 1% of the original model size, by freezing the base weights and training only small rank-decomposition matrices. However, even with LoRA, the serving problem persisted. Traditional inference frameworks were not built to handle the dynamic nature of these adapters. Most servers required that the adapter be merged with the base model at deployment time, effectively creating a “new” full-sized model that still required a dedicated GPU. This forced engineers into a trade-off: either suffer from high latency while swapping models in and out of VRAM or pay for dedicated resources that were rarely used to their full capacity.
LoRAX was developed to eliminate this trade-off. By treating the base model as a shared, immutable backbone and the adapters as lightweight, dynamic overlays, LoRAX allows the hardware to maximize its utilization. The technical innovation lies in the server’s ability to keep the base model resident in memory while fetching and applying different adapters on a per-request basis. This architecture transforms the GPU from a single-tenant resource into a high-density, multi-tenant execution environment.
The Economic and Operational Utility of Multi-Adapter Serving
The utility of LoRAX is best understood through the lens of infrastructure consolidation and operational flexibility. In a traditional setup, the total cost of ownership (TCO) for a suite of fine-tuned models is a linear function of the number of models. With LoRAX, the TCO becomes a function of the total request volume, regardless of how many unique models those requests are spread across. This shift allows AI startups and large enterprises alike to pursue a “model-per-task” or “model-per-user” strategy that was previously cost-prohibitive.

The table above illustrates the dramatic efficiency gains. By sharing the base weights, LoRAX enables hardware densities that were previously unimaginable. This is particularly useful for applications such as Named Entity Extraction (NER), where different domains (e.g., medical, legal, financial) require specialized vocabulary and context windows. Instead of deploying three separate models, an engineer can deploy one LoRAX server with three adapters, reducing the memory footprint from 45GB to roughly 15GB.
Furthermore, LoRAX provides a critical advantage in the iteration cycle. In a production environment, updating a model usually requires a full redeployment, which can trigger service interruptions or require complex blue-green deployment strategies. With LoRAX, an engineer can “hot-swap” a new adapter simply by changing the adapter_id in the API call. This allows for seamless A/B testing of different fine-tuning checkpoints and immediate evaluation of new models without touching the underlying server infrastructure.
Technical Deep Dive: The Three Pillars of LoRAX Architecture
The ability to serve thousands of adapters on a single GPU is not merely a matter of configuration but the result of a fundamental redesign of the inference lifecycle. LoRAX is built on three core technical pillars: Dynamic Adapter Loading, Tiered Weight Caching, and Continuous Multi-Adapter Batching. Each of these components addresses a specific bottleneck in the standard inference pipeline.
Pillar 1: Dynamic Adapter Loading
In standard inference servers, all weights are loaded during the initialization phase. If an engineer wants to use a new model, the server must be restarted or a new instance must be provisioned. LoRAX flips this model by loading only the base LLM weights at startup. The adapters themselves are loaded “just-in-time” when a request specifies an adapter_id.
This process is handled by an asynchronous loader that manages the fetching of adapter weights from a variety of sources, including the Hugging Face Hub, Predibase, S3, or a local directory. When a request arrives, the server checks its internal registry. If the adapter is already present in VRAM, the request is processed immediately. If the adapter is missing, the request is placed in an isolated queue specifically for that adapter, while the system continues to process other concurrent requests using different adapters. This non-blocking architecture ensures that the “noisy neighbor” problem — where one heavy request slows down the entire system — is minimized.
The time taken to load an adapter is a function of its size. Since LoRA adapters are typically between 10MB and 200MB, the load time is measured in hundreds of milliseconds, compared to the minutes required for a 15GB foundation model. This allows the server to feel responsive even when it is experiencing a “cold start” for a new adapter.
Pillar 2: Tiered Weight Caching

Memory management is the most critical task for a high-density inference server. Even small adapters can eventually fill up VRAM if they are not managed correctly. LoRAX implements a tiered caching strategy that mimics the memory hierarchy of a modern computer, utilizing GPU VRAM, CPU DRAM, and persistent disk storage.
- VRAM Tier (The Hot Cache): This tier holds the active adapters currently being used for inference. The capacity of this tier is limited by the remaining VRAM after the base model and KV (Key-Value) cache are allocated.
- DRAM Tier (The Warm Cache): When the VRAM is full, the server uses a Least Recently Used (LRU) policy to evict adapters. These weights are moved to the system’s host memory (RAM). Moving weights from DRAM back to VRAM is significantly faster than downloading them from the network, allowing “warm starts” to be nearly instantaneous.
- Disk/Remote Tier (The Cold Cache): The final tier resides on a local NVMe drive or remote object storage. This tier can hold thousands of adapters, ensuring that the system can scale to an effectively unlimited number of fine-tuned variants without crashing the server.
This intelligent management prevents Out-of-Memory (OOM) errors, a common failure point in LLM serving. By dynamically balancing the memory budget between the base model, the active adapters, and the KV cache required for long sequences, LoRAX maintains high availability even under extreme multi-tenant pressure.
Pillar 3: Continuous Multi-Adapter Batching
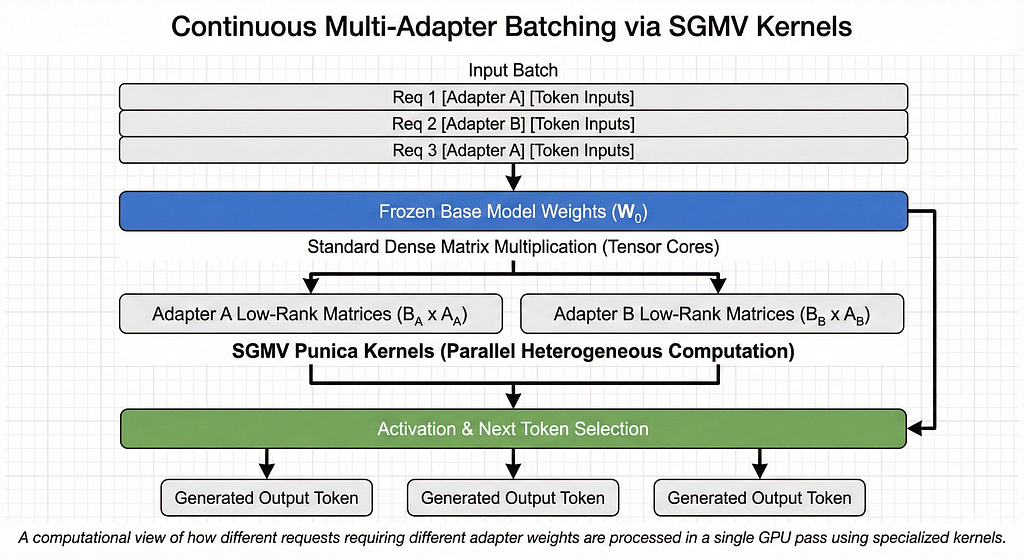
The most significant technical innovation in LoRAX is its ability to batch requests for different adapters together in a single GPU pass. In a standard inference server, batching is only possible when every request in the batch uses the same weights. This is because traditional matrix multiplication kernels expect a single weight matrix for the entire operation.
If a server receives five requests — one for a math adapter, one for a coding adapter, and three for a general assistant adapter — a traditional server would have to process them as two separate batches or sequences. LoRAX uses Heterogeneous Continuous Batching, which extends the popular continuous batching strategy to work across multiple sets of LoRA adapters in parallel.
The system achieves this by using a fair scheduling policy that marks a subset of adapters as “active” at any given time. Requests from these active adapters are drained from their queues and combined into a single batch. A mathematical mask is applied during the computation of activations to ensure that each input sequence is processed by the correct adapter weights. After a configurable time period, the scheduler performs a round-robin rotation, moving a different set of adapters into the active state to ensure that every request is eventually served.
The Mathematical Foundation: SGMV and Punica Kernels
To understand how LoRAX performs multi-adapter batching at the hardware level, one must look at the low-level CUDA kernels that power it. LoRAX incorporates the Segmented Gather Matrix-Vector Multiplication (SGMV) kernel, which was originally developed by the Punica project.
Mathematically, the forward pass of a LoRA-adapted layer can be represented as:

In this equation W0 represents the frozen pre-trained weights of the base model, while and are the low-rank adapter matrices. When processing a batch of inputs X = [x1, x2,…, xn], where each might correspond to a different adapter (Ai, Bi), the computation becomes:

The first part of the operation (XW0) is a standard matrix-matrix multiplication that can be computed extremely efficiently using the GPU’s tensor cores. The challenge lies in the second part — the “LoRA addon” — where each row of the input batch must be multiplied by a different pair of A and B matrices.
A naive implementation would iterate through each request and launch a separate kernel, but this would result in massive overhead and poor GPU utilization. The SGMV kernel solves this by parallelizing the feature-weight multiplication of different requests and grouping those that correspond to the same adapter to increase operational intensity.
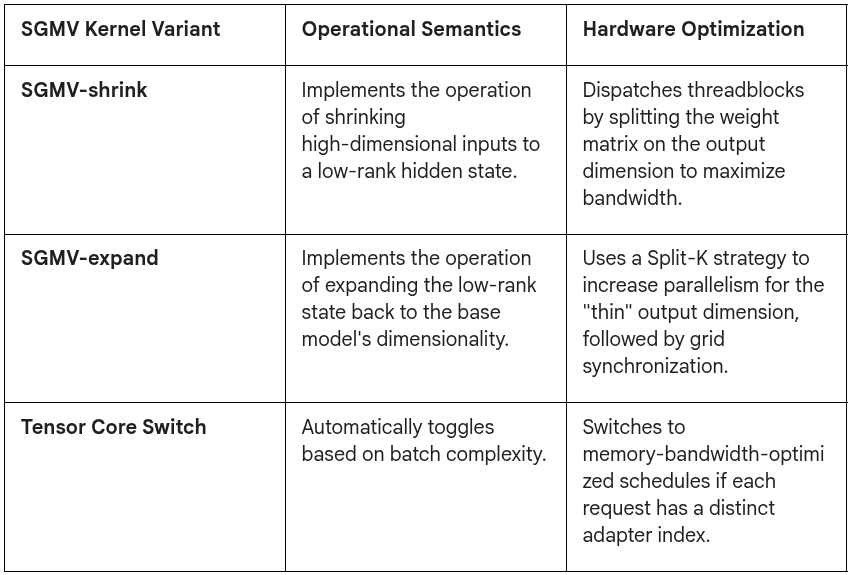
By utilizing these specialized kernels, LoRAX ensures that the cost of serving multiple adapters is nearly identical to the cost of serving a single base model. Benchmarks have shown that Punica-powered systems can achieve up to 12x higher throughput compared to state-of-the-art serving systems while adding only 2ms of latency per token.
Advanced Features for Production AI Systems
LoRAX is more than just a multi-adapter server; it includes several “quality of life” features for AI engineers that solve common problems in the LLM production lifecycle. Two of the most important are Structured Generation (JSON Mode) and Lookahead LoRA for speculative decoding.
Structured Generation: The Outlines Integration
A persistent problem for developers is the tendency of LLMs to produce malformed output. When an application needs to consume LLM data programmatically — for example, to populate a database or trigger an API — the output must adhere strictly to a JSON schema. While fine-tuning can teach a model to prefer JSON, it cannot provide a 100% guarantee of structural integrity.
LoRAX solves this by natively integrating the Outlines library, enabling a feature known as structured generation or constrained decoding. As of version 0.8, LoRAX allows engineers to specify an Outlines-compatible JSON schema in their request. The inference engine then modifies the token probability distribution at each step of the generation process to ensure that only valid characters (according to the schema) can be selected.
This creates a powerful “best of both worlds” scenario:
- The LoRA Adapter is fine-tuned to extract the correct content (e.g., finding the “Name” and “Amount” in an invoice).
- The JSON Mode ensures that the content is formatted correctly in the final payload.
Research has shown that while an adapter alone can improve content accuracy similarity scores from 0.50 to 0.71, the combination of an adapter and structured generation raises that score to over 0.80 while achieving 99.9% structural validity.13
Lookahead LoRA: Native Speculative Decoding

Inference latency is often the primary bottleneck for real-time applications. Speculative decoding is a popular technique for reducing latency by using a smaller “draft” model to predict multiple tokens ahead, which are then verified in parallel by the larger “target” model. However, deploying a separate draft model adds infrastructure complexity.
LoRAX introduces Lookahead LoRA, which embeds the speculative decoding logic directly into the adapter. The adapter is trained not only to produce the next token but also to predict the subsequent few tokens. This allows the system to generate multiple tokens per step without requiring a second model. Demonstrations have shown that Lookahead LoRA can improve throughput by 2–3x compared to standard LoRA adapters, making it an essential tool for latency-sensitive applications like code completion or real-time chat.
Implementation Guide: Serving 1000 Models in Practice
For an AI engineer, the transition from local testing to a production LoRAX deployment is straightforward, thanks to its Docker-centric architecture and OpenAI-compatible API.
Step 1: Launching the LoRAX Server
LoRAX is best run using its official Docker image, which contains all necessary CUDA kernels and dependencies. The minimum requirement is an NVIDIA GPU of the Ampere generation or newer (e.g., A10, A100, H100) and CUDA 11.8+ drivers.
# Set the base model ID
MODEL="mistralai/Mistral-7B-Instruct-v0.1"
# Run the Docker container
docker run - gpus all - shm-size 1g -p 8080:80
-v $PWD/data:/data
ghcr.io/predibase/lorax:main
- model-id $MODEL
This command loads the shared base model into VRAM and opens a REST API on port 8080.
Step 2: Prompting with Adapters
Once the server is running, prompting a specific adapter is as simple as adding the adapter_id to the request payload. LoRAX supports both a dedicated REST API and a Python client.
Using the Python client:
from lorax import Client
client = Client("http://127.0.0.1:8080")
# Prompt the base model
print(client.generate("Tell me a joke.").generated_text)
# Prompt a specific LoRA adapter
adapter_id = "vineetsharma/qlora-adapter-Mistral-7B-Instruct-v0.1-gsm8k"
print(client.generate("Solve for X: 2x + 5 = 13", adapter_id=adapter_id).generated_text)
For engineers using existing OpenAI-compatible libraries, LoRAX supports the Chat Completions API. The model parameter in the OpenAI request is used to specify the adapter_id.
from openai import OpenAI
client = OpenAI(api_key="EMPTY", base_url="http://127.0.0.1:8080/v1")
response = client.chat.completions.create(
model="alignment-handbook/zephyr-7b-dpo-lora",
messages=[{"role": "user", "content": "How do I build a ship?"}]
)
Step 3: Production Deployment with Kubernetes
For large-scale applications, LoRAX can be deployed on Kubernetes using provided Helm charts. This enables high availability and auto-scaling based on request volume. Engineers should configure max_loras and max_lora_rank in their values.yaml to optimize VRAM allocation for their specific set of adapters.
Comparative Performance: LoRAX vs. vLLM and TGI
When selecting an inference framework, AI engineers often compare LoRAX with other popular options like vLLM and Hugging Face’s Text Generation Inference (TGI). While vLLM is renowned for its raw throughput in single-model scenarios, LoRAX is the undisputed leader in multi-adapter, multi-tenant environments.

The core difference lies in the kernel design. vLLM’s BGMV kernels are highly efficient during the decoding phase, but LoRAX’s use of SGMV provides superior performance during the prefill phase, especially for long-context prompts. For engineers building applications where the initial prompt processing is the bottleneck (such as document summarization or RAG-based systems), LoRAX offers a clear throughput advantage.
Furthermore, LoRAX’s native support for “Lookahead LoRA” and “Structured Generation” removes the need for additional post-processing layers, simplifying the overall software stack and reducing the “token waste” associated with retrying failed JSON requests.
Conclusion: The Future of High-Density LLM Serving
The emergence of LoRAX marks a significant milestone in the maturation of the AI engineering stack. By solving the multi-model serving problem, it has democratized access to specialized intelligence, allowing even small teams to deploy a sophisticated ecosystem of task-specific models for a fraction of the previous cost.
The transition from “One Model per GPU” to “1000 Adapters per GPU” is more than just a hardware optimization; it is a fundamental shift in how we architect AI systems. It encourages a modular, expert-driven approach to model design, where general knowledge is shared and specific expertise is added as a lightweight layer. As we move toward more agentic and complex AI workflows, the ability to dynamically swap and combine these experts in real-time will be the defining characteristic of successful production systems.
For the AI engineer, the message is clear: the era of monolithic deployments is over. Frameworks like LoRAX provide the tools necessary to build scalable, cost-effective, and highly specialized AI products that can grow with the needs of the business without being constrained by the limits of GPU memory. The path to serving the next 1,000 models is not through more hardware, but through smarter software.
References
- https://loraexchange.ai/
- https://github.com/predibase/lorax
- https://vast.ai/article/efficiently-serving-multiple-ml-models-with-lorax-vllm-vast-ai
- https://arxiv.org/pdf/2310.18547
- https://www.rubrik.com/blog/ai/23/lorax-the-open-source-framework-for-serving-100s-of-fine-tuned-llms-in
- https://medium.com/@saimudhiganti/lorax-serve-1000-fine-tuned-models-on-one-gpu-heres-how-62336a64de4b
- https://www.truefoundry.com/blog/scaling-up-serving-of-fine-tuned-lora-models
The Architectural Paradigm of Multi-Adapter Inference: A Technical Analysis of LoRAX was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.