
I Spent Months Tuning Multi-Agent Systems in Production. Most of the Advice Out There Is Wrong.
Everyone’s debating architecture. Nobody’s talking about what actually matters once you ship it.
I need to get something off my chest.
I’ve been building a multi-agent orchestration platform — processing real insurance workflows, real claims, real policy renewals — and every week I see another article explaining the difference between single-agent and multi-agent systems. Another tutorial on setting up your first LangChain orchestrator. Another hot take about whether agents are “ready for production.”
That ship has sailed. At least for me.
The questions I’m dealing with now look nothing like the ones in those tutorials. I’m debugging why my Claims Officer agent handles straightforward claims fine but falls apart on multi-party cases. I’m trying to figure out why token costs spike when the orchestrator misroutes a request. I’m looking at traces and wondering why a perfectly good agent decided to hallucinate an API call instead of admitting it didn’t have the data.
These are optimization problems. And honestly, I had to learn most of this the hard way because nobody writes about it.
So here’s what I’ve actually learned — the stuff that moved the needle, the stuff that didn’t, and a few things I got completely wrong before figuring them out.
The Pattern That Works (and Why You Already Know It)
Let me get the architecture out of the way quickly, because this part genuinely isn’t controversial anymore.
Small specialized agents — three to five tools each — coordinated by a lightweight orchestrator. That’s it. Google’s Cloud Architecture Center documents this. Microsoft’s Azure AI patterns recommend it. NVIDIA demonstrated it empirically with their ToolOrchestra framework, where an 8-billion-parameter orchestrator model outperformed GPT-5 on the Humanity’s Last Exam benchmark (37.1% vs 35.1% accuracy while being roughly 2.5x more efficient), and on the τ²-Bench and FRAMES benchmarks while using approximately 30% of the cost.
The evidence is overwhelming. The pattern works.
But here’s what nobody tells you: knowing this pattern and running it well are completely different things. I knew the pattern for weeks before my system actually worked properly. The gap between “functioning multi-agent system” and “one that doesn’t hemorrhage money or drop accuracy under load” — that’s where I’ve spent most of my time.
Insight 1: Tool Count Is Your Single Biggest Accuracy Lever (and I Learned This the Painful Way)
Before I understood this, I built what I now call my “fat agent.” One agent, one massive context window, handling employee lookup, leave management, balance checking, approvals, and policy queries — all running on Sonnet. It worked. Sort of.
The accuracy was inconsistent in ways that drove me crazy. Some days it nailed everything. Other days it’d pick the wrong tool for a leave balance check and cascade into a series of failed API calls. I spent two weeks convinced the issue was my prompt engineering. I rewrote the system prompt probably fifteen times. I added examples, constraints, explicit tool selection logic.
None of it helped much.
Then I came across research that quantified what I’d been experiencing. Multiple studies — including a December 2025 paper benchmarking tool retrieval across LLMs at different context scales — show a clear pattern: tool selection accuracy degrades non-linearly as the number of available tools increases. One study using Gemini 2.0 Flash showed a 10-percentage-point accuracy drop going from 10 to just 100 tools. Others, like the RAG-MCP research, found that at enterprise scale (hundreds of tools), selection accuracy can collapse to below 15% without retrieval-based filtering. It’s not a gentle slope. At some point, the model just starts guessing.
The fix wasn’t in the prompt. It was in the architecture. I broke the system into specialized micro-agents — a Leave Balance Checker, a Leave Request Approver, an Employee Lookup agent — each with two to four tools. An orchestrator routes between them based on intent.
The accuracy improvement was immediate. Not because the underlying model got smarter, but because each agent’s decision space got dramatically smaller.
Insight 2: The Best Orchestrator Move Is Often Doing Nothing
This one surprised me. Here’s a real trace from my system:
User: "I need to approve the pending leave request from John Smith"
|
v
manager-orchestrator (Sonnet)
|
|-- query_Employee (FirstName=John, LastName=Smith)
| Result: not found (11ms)
|
|-- query_LeaveRequest (Status=Pending)
| Result: none (3ms)
|
|-- list_LeaveRequest
| Result: [] empty (1,603ms)
|
| Decision: No requests found. Inform user.
| Did NOT delegate. Nothing to approve.
|
v
User sees: "No leave requests found. Please verify
John Smith has submitted one."
Look at what happened: the orchestrator used its own lightweight read tools first — cheap, fast lookups — and when it found nothing, it stopped. It didn’t spin up a specialist agent to try to “approve” something that doesn’t exist.
In my old fat-agent architecture, this exact scenario would burn through the full tool set. The agent would try the approval tool, get an error, retry with different parameters, maybe hallucinate a leave request ID, and eventually give up after wasting several thousand tokens. I saw this happen repeatedly in my traces before I understood the pattern.
When there actually is data to act on, the flow changes:
manager-orchestrator (Sonnet)
|
|-- query_LeaveRequest --> finds request "abc-123"
|
|-- delegate_to --> leave-request-approver (Haiku)
| |-- update_LeaveRequest (add comments)
| |-- transition_LeaveRequest (trigger: "approve")
| |-- returns "Request abc-123 approved"
|
User sees: "John Smith's leave request has been approved."
The orchestrator does the lookup on Sonnet. The actual approval — the write operation — runs on Haiku. A cheaper, faster model handling the execution while the smarter model handles routing.
This read-then-decide pattern isn’t something I designed upfront. I discovered it by reading my own traces and noticing that the most expensive failures were delegation decisions made without enough context. Once I gave the orchestrator lightweight read access, it started making much better routing decisions. And sometimes the best decision is to not route at all.
Insight 3: The 10x Cost Difference Is Real — Here’s My Actual Data

I pulled these numbers from actual production traces. They’re not averages or projections — they’re from specific test runs I instrumented:
What Ran | Model | Input Tokens | Cost
------------------------------|--------|--------------|----------
employee-orchestrator | Sonnet | 7,440 | ~$0.022
leave-balance-checker | Haiku | ~3,000 | ~$0.003
manager-orchestrator | Sonnet | 13,587 | ~$0.041
(no delegation needed) | -- | -- | $0
The number that matters most: the actual leave balance check costs roughly $0.003 on Haiku. In my old architecture, this same operation ran entirely on Sonnet for about $0.03. That’s approximately 10x more for the task execution portion.
At a few transactions a day, who cares. At thousands of daily transactions across an insurance operation? The savings compound fast.
But the cost story goes deeper than model pricing. Look at the second trace: the manager-orchestrator spent $0.041 on routing and lookup, then spent zero on delegation because it determined nothing needed to happen. In the old architecture, the fat agent would have burned through its full tool repertoire trying to “approve” something that didn’t exist.
The orchestrator’s ability to say “there’s nothing to do here” is itself a cost optimization. That’s something I didn’t appreciate until I saw the numbers.
Insight 4: Match Your Model Tier to the Job, Not the Prestige

Here’s the model strategy that works in my system:
The orchestrator runs on Sonnet — smart enough for correct routing decisions, understanding nuanced requests, and knowing when not to delegate. The micro-agents run on Haiku — fast, cheap, and reliable for bounded execution tasks like approving a request, updating a record, or calculating a balance.
This works because the orchestrator’s job is to make one good decision per request. Route or don’t route. That’s a classification task, and you want the best model you can afford for it because misrouting is expensive. The execution, though, is bounded — “approve this leave request” doesn’t require deep reasoning, it requires reliably calling two API endpoints in sequence.
NVIDIA validated this pattern at scale. Their Orchestrator-8B (an 8-billion-parameter model fine-tuned with reinforcement learning) consistently outperformed much larger monolithic models by strategically delegating to the right specialist at the right time. On the HLE benchmark, this tiny orchestrator beat GPT-5. Not because it was smarter — but because it was better at knowing when to use smarter tools.
One caveat I learned the hard way: this tiering breaks down when execution tasks require judgment, not just procedure. If a micro-agent needs to interpret ambiguous policy language or handle an edge case that requires reasoning about context, Haiku isn’t enough. I’ve had to selectively upgrade certain micro-agents to Sonnet for complex claims processing paths. The tier isn’t set in stone — it’s a dial you tune per agent based on the actual error rate you observe.
Insight 5: Semantic Similarity Between Tools Is the Silent Killer
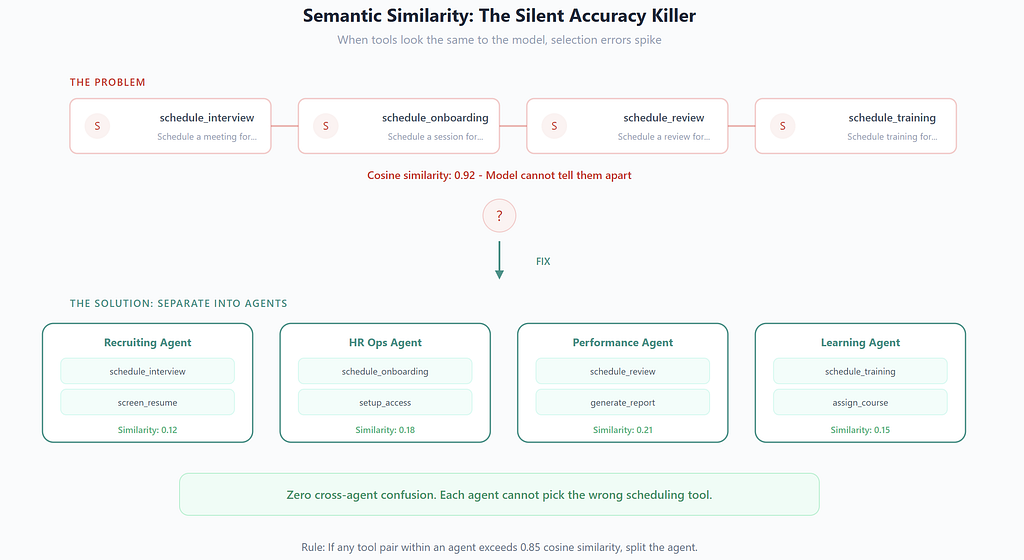
Here’s something that took me a while to internalize. The primary driver of tool selection errors isn’t raw tool count — it’s how similar the tools look to the model.
Consider an HR system with these tools:
- schedule_interview (recruiting)
- schedule_onboarding (HR ops)
- schedule_review (performance)
- schedule_training (L&D)
To a human, the differences are obvious. To an LLM selecting from tool descriptions, the word “schedule” dominates the semantic space. The distinguishing context — recruiting vs. onboarding vs. performance — is subtle and often buried in the description.
This is where the multi-agent pattern provides its biggest win, and it’s not the reason most people think. It’s not just about reducing tool count. It’s about eliminating semantic overlap within each agent’s tool set.
When the Recruiting Agent only has schedule_interview, screen_resume, and send_offer, there’s zero confusion. The agent literally cannot select the wrong scheduling tool because the others don’t exist in its context. The orchestrator handles the higher-level distinction — ”Is this a recruiting request or an onboarding request?” — where the intent signal is typically stronger and more explicit.
I’ve started measuring this by computing cosine similarity between tool description embeddings within each agent’s tool set. When any pair of tools exceeds a similarity threshold (I use 0.85), I know I’m going to see selection errors in that agent. Either I rename the tools with more distinct descriptions, or I split the agent. This has been more predictive of accuracy than raw tool count.
Insight 6: What the Industry Is Actually Shipping Right Now
Let me ground this with what’s in production — not press releases, not “coming soon,” but systems handling real transactions.
Insurance: Allianz’s Project Nemo. Launched in Australia in July 2025, Nemo uses seven specialized AI agents to automate food spoilage claims — from coverage verification to weather validation to fraud detection. A human makes the final payout decision. They built it in under 100 days and reported an 80% reduction in processing time. For claims under AUD$500, what used to take days now resolves in hours. The modular architecture is now being adapted for travel delays, auto claims, and property damage across geographies.
Insurance: AXA Switzerland with Shift Technology. AXA adopted Shift Claims, an agentic AI platform that assesses claim complexity, classifies and prioritizes cases, automates routine tasks, and assists human handlers on complex ones. Shift’s approach — using specialized AI agents trained on insurance-specific processes — mirrors the pattern: different agents for different tasks, humans in the loop where judgment matters.
HR: IBM’s AskHR. This one’s been running for years and the numbers are hard to argue with. AskHR automates approximately 80 tasks with a 94% containment rate. Support tickets dropped 75% since 2016, and operational costs fell 40% over four years. In 2024 alone, the system handled 11.5 million employee interactions across 52 languages. IBM’s CHRO described the approach: start with high-volume, low-complexity requests (letters, PTO, payroll access), then expand to more complex manager workflows under governance. Not one mega-bot — a progressively expanding set of capabilities.
The common thread across all of these? Specialized agents with clear boundaries, human oversight at critical decision points, and modular architectures that allow expansion without rebuilding.
The Optimization Framework I Actually Use
After months of tuning, here’s where I’ve landed. This isn’t theoretical — it’s the actual sequence I follow when a new agent or workflow isn’t performing.
Step 1: Measure your baseline. I track four numbers per agent: tool selection accuracy (did the agent pick the right tool?), routing accuracy (did the orchestrator send the request to the right specialist?), token cost per successful transaction (not per call — per completed task), and error cascade rate (when one agent fails, how often does it cause downstream failures?). Most teams skip this step. Without numbers, you’re optimizing vibes.
Step 2: Reduce tool count per agent to five or fewer. If any agent has more than five tools, split it. This consistently produces larger accuracy improvements than any prompt engineering technique I’ve tried. It’s the highest-ROI optimization available to you.
Step 3: Eliminate semantic overlap within agents. Run similarity scoring on tool descriptions. If two tools in the same agent have overlapping verbs or domain terms, either rename them for distinctness or move one to a different agent.
Step 4: Right-size your model tiers. Notice I’m not saying “downgrade your orchestrator.” I used to think the orchestrator should be cheap. I was wrong — I tried running the orchestrator on Haiku and routing accuracy dropped enough that the cost savings were wiped out by misrouting waste. The orchestrator needs to be smart enough for the routing complexity you have. But your execution agents can almost always be smaller. Test downgrading those first.
Step 5: Invest in routing quality. Better few-shot examples in the orchestrator prompt. Explicit routing rules for known edge cases. Confidence thresholds that trigger clarification requests instead of guessing. This is where marginal effort yields outsized cost savings, because every misroute wastes the cost of an entire agent invocation.
Step 6: Address latency. This is something I underestimated initially. Multi-agent systems introduce sequential latency — orchestrator reasoning, then lookup, then delegation, then execution, then return. In my system, end-to-end response times can hit 3–5 seconds for delegated operations. I’ve started parallelizing independent lookups in the orchestrator phase, which shaved about 30% off total latency. If your users are waiting on agent responses, this matters more than cost.
Step 7: Build error recovery. Agents fail. Tools return errors. External APIs timeout. The question isn’t whether this happens but how your system handles it. I’ve implemented retry with exponential backoff for transient failures, fallback routing to alternative agents for persistent failures, and a circuit breaker pattern that stops sending requests to a failing downstream service. None of this was in my v1 architecture. All of it was necessary in production.
Step 8: Measure again. Compare to your baseline. Focus on cost per successful transaction — the metric that captures both accuracy and efficiency in a single number.
The Security Argument Nobody Makes (But Should)
Cost and accuracy dominate this conversation. But there’s a third reason this architecture wins that matters enormously for enterprise deployment: security through separation of concerns.
When a single agent has access to customer data AND payment systems AND fraud detection, a single prompt injection or hallucination can cascade across trust boundaries. I’ve seen this in testing — a cleverly constructed input that tricks the model into treating fraud-flagged data as approved. With a monolithic agent, that’s a potential breach.
With specialized agents operating under least-privilege access, the blast radius shrinks:
The Coverage Agent can read policy data but can’t trigger payments. The Payment Agent can execute transfers but can’t modify policy terms. The Fraud Agent can flag anomalies but can’t access raw customer PII. Each agent only has credentials for the tools it needs.
This maps directly to least-privilege access control — the same principle that’s governed enterprise security architecture for decades, now applied to AI agents. It’s also the architecture that Allianz chose for Project Nemo, where the Cyber Agent specifically enforces data security protocols and policy guardrails as part of the seven-agent workflow.
For my own system, I implemented this through MCP server-level permissions. Each micro-agent connects to a constrained set of MCP tool endpoints. Even if the model hallucinates a tool call that doesn’t exist in its tool set, the MCP layer rejects it. Defense in depth, applied to agent systems.
The Protocol Stack for 2026
For those building this today, the protocol landscape has matured faster than most people realize:
MCP (Model Context Protocol) — Originally Anthropic’s protocol, now governed by the Agentic AI Foundation (AAIF), a directed fund under the Linux Foundation co-founded by Anthropic, Block, and OpenAI, with support from Google, Microsoft, AWS, and others. MCP handles the vertical connection: agent to tools and data sources. It hit 97 million monthly SDK downloads in its first year. Each specialized agent in my system connects to its bounded tool set via MCP.
A2A (Agent-to-Agent Protocol) — Google’s open protocol for horizontal communication between agents. When your Claims Agent needs to coordinate with your Fraud Agent, A2A provides the standard. It handles things like capability discovery and task delegation between independently running agents.
AP2 (Agent Payments Protocol) — Also from Google, announced September 2025, with over 60 collaborating organizations including Mastercard, PayPal, American Express, and Coinbase. When agent systems need to execute financial transactions, AP2 provides cryptographic proof of user intent through tamper-proof “mandates.” This is specifically designed for the scenario where an agent — not a human clicking a button — initiates a payment.
The stack: MCP for tools. A2A for coordination. AP2 for transactions. This is the production stack that’s emerging for 2026. What’s still missing? Standard observability and tracing across agent boundaries. Right now, I’m rolling my own instrumentation. I expect this to be the next protocol-level gap that gets filled.
What I Still Get Wrong
I want to be honest about what I haven’t solved.
My system still struggles with ambiguous requests that could reasonably be routed to multiple agents. “Help me with the Smith case” — is that a claims question, a policy question, or a customer service question? My orchestrator guesses, and it guesses wrong about 15% of the time on these ambiguous inputs. I’ve tried confidence thresholds and clarification prompts, but users hate being asked to clarify. This is an open problem for me.
I also don’t have a great answer for long-running workflows that span multiple agent interactions over time. A claims process that takes three days and involves seven touchpoints doesn’t fit neatly into the “request → route → execute → return” pattern. I’m experimenting with persistent workflow state that agents can read and write to, but it’s messy.
And my evaluation methodology is still too manual. I review traces, I spot-check outputs, I track aggregate metrics. But I don’t have automated evaluation pipelines that can tell me, with confidence, whether a new prompt change improved or degraded accuracy across the full distribution of real-world requests. Building that is next on my list.
What’s Next
The industry is converging fast. The architecture debate is settled. What separates production systems from demos is the tuning — cost optimization, accuracy engineering, routing intelligence, error recovery, and the thousand small decisions that make an agent system reliable at scale.
I’m continuing to refine my system’s routing accuracy, cost per transaction, and error cascade rates. I’ll share more specific numbers and benchmarks as I collect more production data.
If you’re building multi-agent systems and you’re past the “should I use multiple agents?” stage, I’d genuinely like to compare notes. The optimization problems at this level are fascinating, underexplored, and hard to solve alone.
I build multi-agent orchestration systems for enterprise automation — currently focused on insurance workflows, claims processing, and policy management. The work involves a lot of staring at traces, arguing with token budgets, and occasionally being surprised by what a well-designed small model can do.
https://www.linkedin.com/in/thamilvendhan
Tags: #ArtificialIntelligence #AgenticAI #MultiAgentSystems #CostOptimization #MCP #A2A #Insurance #EnterpriseAI #AIEngineering #ProductionAI
I Spent Months Tuning Multi-Agent Systems in Production. Most of the Advice Out There Is Wrong. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.