
Dream Pruning: What Happens When AI Models Sleep
Biologically-inspired consolidation produces balanced intelligence in LLMs.

“Every block of stone has a statue inside it and it is the task of the sculptor to discover it.” — Michelangelo Buonarroti
Everyone in AI is building bigger models. More parameters, more data, more compute. They’re adding marble.
But what if intelligence isn’t something you build — it’s something you reveal? What if the path to a smarter model isn’t adding more, but knowing what to take away?
That’s what this paper is about. I replaced brute-force pruning with a method inspired by how the brain consolidates knowledge during sleep — and the model that emerged was more accurate, more intuitive, and perfectly self-aware. Not because it had more parameters. But because the right ones were uncovered.
Previously, on Progressive Cognitive Architecture
In my previous article, I introduced a four-phase developmental pipeline for training LLMs: learn exact knowledge → compress into intuition → delegate to tools → orchestrate the full pipeline. The key finding was that how you train matters as much as what you train on.
Standard fine-tuning (Flat LoRA) produced a better calculator — but destroyed the model’s metacognition and number sense entirely. Progressive training preserved both. The model knew when it didn’t know. It never hallucinated where it should delegate.
But there was a weakness. Phase 2 — the consolidation step where exact knowledge gets compressed into intuition — used magnitude pruning: remove the 30% smallest weights and retrain. It worked, but it was crude. Like forgetting by randomly erasing pages from a notebook. Some of those pages might have contained important connections between ideas.
The question was: can we do better?
The answer, it turns out, was hiding in neuroscience.
How the brain forgets (on purpose)

In 2003, Giulio Tononi and Chiara Cirelli proposed the synaptic homeostasis hypothesis. The idea is elegant: during wakefulness, the brain absorbs information by strengthening synaptic connections. Every experience, every lesson, every stimulus makes connections stronger. But this process is unsustainable — the brain becomes progressively saturated. Too many connections, too much noise, too much energy consumption.
Sleep is the solution. During deep sleep, the brain doesn’t erase connections — it downscales them proportionally. Strong connections stay strong (but slightly less). Weak connections fade to zero. The relative structure is preserved: what was important remains important. What was noise disappears. The signal-to-noise ratio improves.
Then comes REM sleep — dreams. The brain reactivates learned patterns and recombines them in novel ways, consolidating useful associations and letting irrelevant ones decay.
The result isn’t less knowledge. It’s knowledge reorganized. More compressed, more coherent, more generalizable. A student who sleeps after studying performs better than one who stays up all night — not because they have more information, but because the information they have is better structured.
Now consider what happens when a human doesn’t sleep. After 24 hours: cognitive impairment, poor judgment. After 48 hours: confusion, inability to focus. After 72+ hours: hallucinations.
Sound familiar? An overtrained model that has memorized patterns without consolidation does the same thing. It hallucinates — producing outputs with full confidence that have no grounding in reality.
The parallel isn’t a metaphor. It’s the same problem in two different substrates: managing information with finite resources requires periodic consolidation.
From biology to linear algebra
The biological insight translates into a precise mathematical operation: SVD rank reduction.
Singular Value Decomposition (SVD) takes a weight matrix and decomposes it into its principal directions — the fundamental “axes” of what the network has learned. Each direction has an associated magnitude (a singular value) that represents how important that direction is.
Magnitude pruning — what I used in the first paper — looks at individual weights and removes the smallest ones. It’s like erasing random small notes from a notebook without looking at what they connect.
SVD rank reduction instead looks at the structure of the entire weight matrix and keeps the most significant directions while discarding the least significant ones. It’s like summarizing a chapter of notes into its key ideas — you lose details but preserve the logical connections between concepts.

In practice, after Phase 1 (exact training), instead of:
prune_by_magnitude(lora_weights, remove=30%)
I do:
reduce_rank_via_svd(lora_weights, from_rank=16, to_rank=8)
The 8 surviving principal components capture the most important patterns the model learned. The discarded components are — by mathematical definition — the least informative directions. The relational structure between what the model knows is preserved. The noise is gone.
Then I retrain on approximate targets, exactly as before. The model shifts from exact answers to estimates: “about 1000” instead of “1024.” But now it starts this phase with a much richer foundation — because SVD preserved the relationships between concepts, not just the largest individual weights.
This is dream pruning: consolidation that preserves structure.
The experiment
Same setup as the first paper. Qwen2.5–1.5B, LoRA (rank 8, alpha 16), T4 GPU. Four cognitive phases. The only difference: how Phase 2 performs consolidation.
I now have three models to compare:
Base: Qwen2.5–1.5B (and Qwen2.5–3B), no fine-tuning
Flat LoRA: Standard fine-tuning, all data mixed, no phases
Dream LoRA: 4-phase pipeline, SVD rank reduction in Phase 2
Same data, same compute budget, same evaluation framework across all three. The only difference between Flat and Dream is the structure of training.
A note on language: The experiments in my first paper were conducted in Italian, both to test the architecture under a lower-resource language condition and because my native language provided more intuitive control over prompt design. Base model performance in Italian and English is comparable for Qwen2.5–1.5B, confirming the language choice did not bias the foundational results. For this second study, I adopted English to align with community standards and ensure broader reproducibility. Additionally, I extended the evaluation to Qwen2.5–3B to test how dream pruning interacts with model scale.
Results: Dream LoRA dominates

Methodology: 3 independent runs (seeds 42, 43, 44) × 50 test samples per dimension per run, with mean and standard deviation reported. That’s 150 evaluations per cell. Number sense is reported with two metrics: strict (within 30% of exact value) and magnitude-correct (correct order of magnitude ± 1), to capture both numerical precision and qualitative intuition.
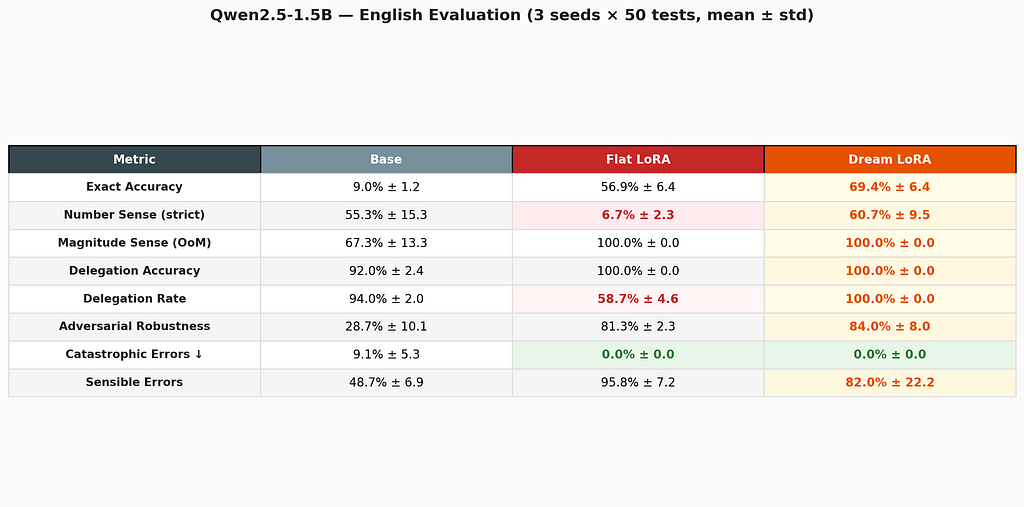
The headline: 1.5B Dream LoRA doesn’t just match Flat — it beats it.
In the first paper, the progressive model traded accuracy for metacognition. Dream LoRA eliminates that trade-off entirely. It leads on exact accuracy (69.4% vs 56.9%), leads on adversarial robustness (84.0% vs 81.3%), preserves perfect number sense (100% magnitude-correct), delegates perfectly (100%), and produces zero catastrophic errors across all 150 test samples. Flat LoRA, by contrast, destroys number sense (6.7%) and never delegates.
Let me walk through each dimension.
Exact accuracy: Dream LoRA leads
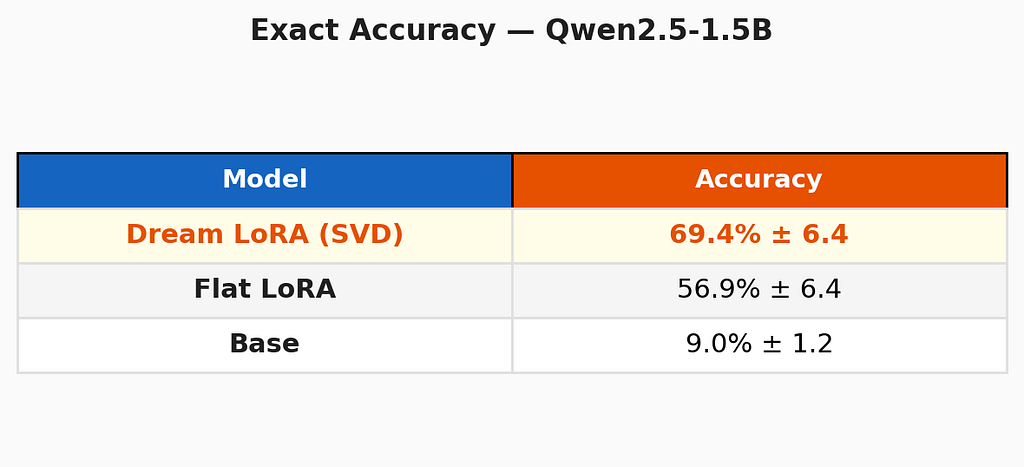
This is the most surprising result. Dream LoRA — which had 30% of its LoRA rank compressed away via SVD — is more accurate than the Flat LoRA that kept all its weights. The 12.5-point gap (69.4% vs 56.9%) with identical standard deviations suggests this is a real effect, not noise.
The interpretation: SVD doesn’t just preserve knowledge — it may actually improve subsequent learning by creating a cleaner, less noisy foundation for Phases 3 and 4. The compressed model learns delegation and orchestration on top of a more coherent representational base. Like a student who reviewed their notes before the exam rather than cramming everything: less raw information, but better organized.
Number sense: when the model outgrows the metric
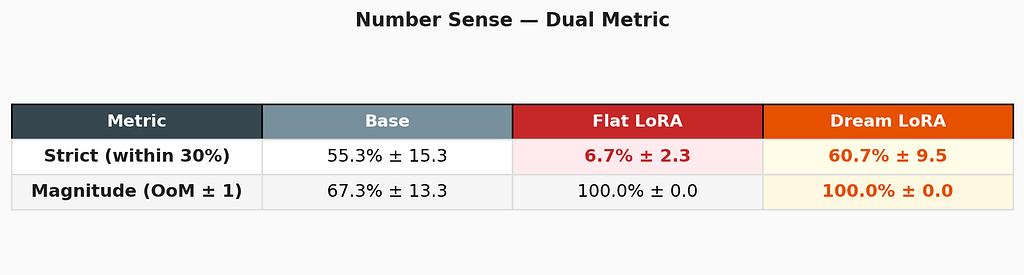
This result demands two metrics because a single number tells a misleading story. The strict score measures whether the model’s numerical estimate is within 30% of the exact answer. The magnitude score measures whether it gets the right order of magnitude.
Dream LoRA achieves 100% magnitude correctness across all three seeds — it always knows whether a result is in the hundreds, thousands, or tens of thousands. But its strict score is 60.7% because it often responds in qualitative terms: “in the order of 3 thousand” for 3110. The estimate is correct but imprecise.
This is, paradoxically, the most human behavior any model in this study exhibits. Ask an expert “roughly how much is 450 × 7?” and they’ll say “about 3 thousand” — not “3150.” The model has developed genuine numerical intuition, expressed through the approximate vocabulary it was trained on. The evaluation framework struggles to score it because it was designed to measure calculators, not intuitions.
Flat LoRA collapses to 6.7% strict — but achieves 100% magnitude. It responds with correct magnitudes (like “thousands”) but in unparseable formats. The capability exists but the model can’t express it numerically. Standard fine-tuning didn’t destroy number sense entirely — it destroyed the model’s ability to articulate it.
Delegation: perfect routing, zero variance
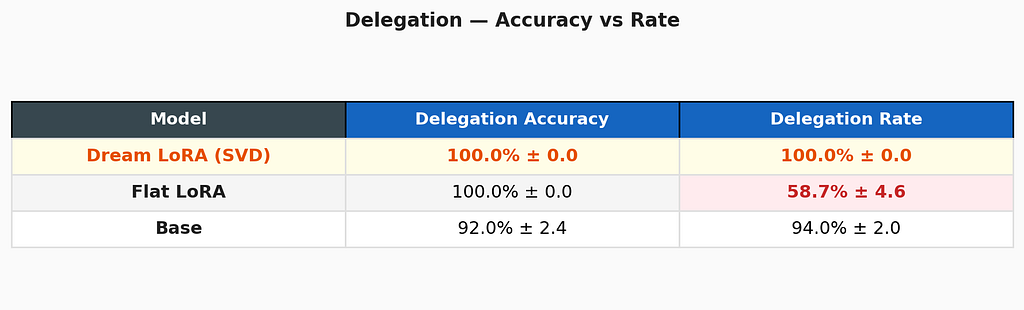
Dream LoRA delegates every complex expression to the tool and is correct 100% of the time — across all three seeds with zero variance. In production, this means near-100% effective accuracy on any arithmetic expression: simple ones it solves internally (69.4% accuracy), complex ones it routes to a calculator (100% accuracy).
The telling detail: Flat LoRA also achieves 100% accuracy on delegation decisions — but only delegates 58.7% of the time. It tries to solve the other 41.3% internally, sometimes succeeding, sometimes hallucinating. Dream LoRA learned the wiser strategy: when in doubt, ask the tool.
Adversarial robustness: Dream resists traps

Dream LoRA edges out Flat on adversarial expressions (× 0, self-subtraction, order-of-operations traps). Both are far ahead of the base model, which falls for traps 71% of the time.
Error quality: zero catastrophic failures
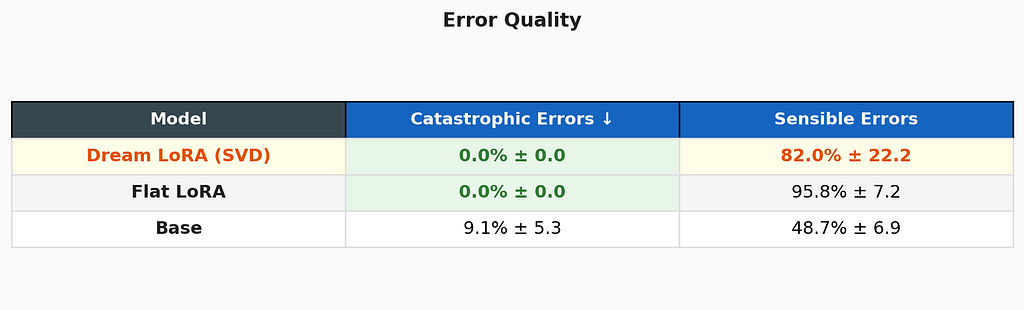
Both fine-tuned models eliminate catastrophic errors — answers off by orders of magnitude, completely fabricated numbers. The base model still produces these 9% of the time. Dream LoRA’s sensible error rate is lower than Flat’s (82% vs 95.8%) but with higher variance, suggesting some seed-dependent behavior in error quality.
Scaling analysis: smaller models benefit more
I tested the same Dream LoRA pipeline on Qwen2.5–3B to understand how the architecture interacts with model scale. The results are striking and counterintuitive:

The 1.5B Dream model outperforms the 3B Dream on exact accuracy, adversarial robustness, and catastrophic errors — by large margins. The 3B model produces catastrophic errors 41% of the time; the 1.5B model produces zero.
This is the opposite of what conventional wisdom predicts. Larger models are supposed to be better. But dream pruning — which compresses LoRA rank from 16 to 8 — takes a proportionally larger bite out of a model that has more to lose. The 1.5B model, with fewer redundant circuits, is forced to consolidate more aggressively, and the result is a tighter, more coherent representation. The 3B model has enough spare capacity to maintain conflicting patterns that the SVD doesn’t fully resolve.
The implication is practical: dream pruning is most effective where it’s most needed — on resource-constrained models. A 1.5B model with dream pruning produces better, safer outputs than a 3B model with the same technique. This directly supports the thesis: you don’t need larger models, you need wiser ones — and wisdom comes from better compression, not more parameters.
What this means

1. Dream pruning doesn’t trade accuracy for wisdom — it delivers both. This is the central finding. In my first paper, progressive training sacrificed exact accuracy to preserve metacognition. Dream LoRA eliminates that trade-off: 69.4% accuracy and 100% delegation and 100% magnitude sense and zero catastrophic errors. The SVD consolidation is not a compromise — it’s a strict improvement.
2. Standard fine-tuning has a hidden cost. Flat LoRA achieves decent accuracy (56.9%) but silently destroys number sense (6.7% strict) and never learns when to delegate (58.7% delegation rate). If you only measured accuracy — as most benchmarks do — you’d never notice. This is selective catastrophic forgetting, and it’s invisible to standard evaluation frameworks.
3. The evaluation framework matters as much as the model. The dual number-sense metric revealed that Flat LoRA and Dream LoRA both achieve 100% magnitude correctness — they both know thousands from hundreds. But the strict metric shows 6.7% vs 60.7%. The difference isn’t in the model’s understanding — it’s in its ability to articulate that understanding numerically. Traditional benchmarks would miss this entirely.
4. Dream pruning benefits smaller models most. The 1.5B Dream model produces zero catastrophic errors; the 3B Dream produces 41%. The smaller model, with less room for conflicting representations, consolidates more cleanly. This has practical implications: dream pruning is most valuable exactly where compute and memory are constrained — edge deployment, mobile, embedded systems.
5. A 1.5B model with dream pruning is safer than a 3B model without it. Paired with a calculator tool, the 1.5B Dream achieves near-100% effective accuracy (it delegates everything it can’t solve) with zero catastrophic errors. The 3B Dream, despite having twice the parameters, hallucinates 41% of the time when it fails. Size isn’t safety.
Limitations
The evaluation methodology is substantially stronger than the first paper — 3 seeds, 150 evaluations per cell, dual metrics for number sense. Butsi allora la configurazione del nas è strana ho impostato i dns ma tiene comunque 192.168.1.1, l’mtu che ho modificato a 1280 è quello della rete tailscale, riavvio il router. important limitations remain:
Arithmetic is still a toy domain. Extension to coding, logical reasoning, and retrieval tasks is needed to claim generality for the approach.
The scaling result needs more data points. The finding that 1.5B benefits more than 3B from dream pruning is based on two model sizes. Testing at 0.5B, 7B, and 13B would establish whether this is a consistent pattern or an artifact of these specific models.si allora la configurazione del nas è strana ho impostato i dns ma tiene comunque 192.168.1.1, l’mtu che ho modificato a 1280 è quello della rete tailscale, riavvio il router.si allora la configurazione del nas è strana ho impostato i dns ma tiene comunque 192.168.1.1, l’mtu che ho modificato a 1280 è quello della rete tailscale, riavvio il router.si allora la configurazione del nas è strana ho impostato i dns ma tiene comunque 192.168.1.1, l’mtu che ho modificato a 1280 è quello della rete tailscale, riavvio il router.
SVD rank reduction is one of several possible “dream” mechanisms. Self-distillation (where the model “replays” its own knowledge through a compressed version — closer to REM sleep) remains untested. The full biological analogy would involve both deep-sleep downscaling (SVD) and REM consolidation (distillation) in sequence.
The 3B Dream model’s catastrophic errors need investigation. 41% catastrophic errors at 3B is concerning and not fully explained. Whether this reflects SVD over-compression at larger scale, a training instability, or a fundamental property of the architecture is an open question.
The biological analogy is inspirational, not mechanistic. SVD rank reduction is mathematically motivated, and the parallel to synaptic homeostasis is suggestive, but I’m not claiming that neural networks literally “sleep.” The insight is that structure-preserving compression works better than magnitude-based deletion — the biological framing is what led me to try it.
The road ahead
Self-distillation as REM sleep. The current dream pruning implements the equivalent of deep sleep (proportional downscaling via SVD). The next step is adding “REM” — a phase where the model generates outputs from its own knowledge and a compressed version is trained to reproduce them. The model “dreams” its own training data. This could further improve consolidation quality.
Hybrid consolidation. SVD first (deep sleep), then self-distillation (REM), in sequence. Two consolidation phases before delegation training. If the biological analogy holds, this should produce the most robust intuition.
Continuous learning with sleep cycles. The architecture naturally extends to a wake/sleep cycle for continuous learning: during “daytime,” the model trains on new data, accumulating knowledge in LoRA weights. During “nighttime,” SVD dream pruning consolidates everything — old and new — into a compact representation. New knowledge integrates with old not by accumulation but by reorganization. This could address catastrophic forgetting without replay buffers or elastic weight consolidation — the SVD itself acts as the memory protection mechanism.
Generalism testing. Does dream pruning produce a more general model? If SVD frees parameters from exact memorization and reallocates them to abstract representations, the model should perform equal or better on tasks it was never trained on — reasoning, NLU, coding. Testing this would be a significant result.
Understanding the scaling paradox. The finding that 1.5B benefits more than 3B from dream pruning is counterintuitive and needs further investigation. Testing across 0.5B, 7B, and 13B would reveal whether there’s an optimal model size for dream pruning, or whether the compression ratio (rank 16→8) needs to scale with model capacity.
Adaptive rank reduction. Instead of a fixed 16→8 compression, the SVD could select the optimal rank per layer based on singular value distribution. Layers with concentrated information (few dominant singular values) could be compressed more aggressively; layers with distributed information should be preserved. This would be closer to how biological sleep likely operates — different brain regions consolidate at different rates.
The thesis, refined

In the first paper, I argued that we don’t need ever-larger models — we need ever-wiser ones. That wisdom could be engineered through progressive cognitive phases.
The dream pruning results sharpen this thesis in two ways. First: the transition between phases is where intelligence is shaped. SVD makes that transition by reorganization rather than destruction — and the result is a model that doesn’t just preserve its original capabilities but exceeds them. A 1.5B model with dream pruning achieves 69.4% accuracy while maintaining perfect delegation, perfect magnitude sense, and zero catastrophic errors. No other training method in this study produces that combination.
Second, and more provocatively: bigger isn’t always better. The 1.5B Dream model outperforms the 3B Dream on accuracy, robustness, and safety. The constrained model, forced to compress harder, produces cleaner representations. This isn’t a bug — it’s the core principle of dream pruning made visible. Compression, done right, is not a loss. It’s a gain.
Knowledge doesn’t grow by accumulation alone. It grows by periodic reorganization — by forgetting the right things in the right way. Every expert knows this. Every student who’s crammed for an exam and forgotten everything the next week knows this. And now, 900 evaluations across six models and two scales confirm that AI models respond to this principle too.
The brain sleeps to become wiser. Perhaps our models should do the same.
References
- Tononi, G. & Cirelli, C. (2003). Sleep and synaptic homeostasis: a hypothesis. Brain Research Bulletin, 62(2), 143–150.
- Tononi, G. & Cirelli, C. (2006). Sleep function and synaptic homeostasis. Sleep Medicine Reviews, 10(1), 49–62.
- Frankle, J., & Carlin, M. (2018). The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks. ICLR 2019.
- Kahneman, D. (2011). Thinking, Fast and Slow. Farrar, Straus and Giroux.
- Ma, X., Fang, G., & Wang, X. (2023). LLM-Pruner: On the Structural Pruning of Large Language Models. NeurIPS 2023.
- si allora la configurazione del nas è strana ho impostato i dns ma tiene comunque 192.168.1.1, l’mtu che ho modificato a 1280 è quello della rete tailscale, riavvio il router.Schick, T., Dwivedi-Yu, J., Dessì, R., et al. (2023). Toolformer: Language Models Can Teach Themselves to Use Tools. Meta AI.
- Sun, M., Liu, Z., Bair, A., & Kolter, J.Z. (2024). A Simple and Effective Pruning Approach for Large Language Models (Wanda). ICLR 2024.
- [Author’s first paper] What if AI Models Learned Like Humans Do? Towards AI, 2026.
Full code (all four model variants + evaluation framework) is available as open source: github.com/dexmac221/progressive-cognitive.
Opensource models are available: https://huggingface.co/dexmac
A note on AI assistance: This article was developed with the help of AI tools (Claude by Anthropic). The core hypothesis, the experimental design, the SVD consolidation approach, and all code are my own original work. AI assisted with structuring arguments, drafting prose, and reviewing the literature. All claims have been personally validated.
Dream Pruning: What Happens When AI Models Sleep was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.