
Why the Transformer Changed AI Forever

In Article 2 of the GenAI series, we explore the Transformer at a high level, the breakthrough that replaced RNNs and powers modern AI.
In the previous article, we established what Generative AI is. We saw how it learns patterns from vast amounts of data and uses those patterns to create something entirely new, whether that is text, images, code, or audio.
We also mentioned something in passing: that almost every modern generative AI system, ChatGPT, Claude, Gemini, and the rest are built on something called a Transformer. That single sentence deserves much more than a passing mention. If Generative AI is a car then the Transformer is the engine that makes it move.
So in this article, we go inside the engine. Not deep inside, not yet. We are going to get the big picture first. Where it came from, what problem it solved, how it thinks, and what shapes it comes in today.
Think of this as reading the map before starting the journey.
But Why Did We Need The Transformer? Was There Any Problem With What Came Before It?
Invention does not happen randomly. Every transformative system in history has been born either out of curiosity or necessity. The Transformer was no different. To understand why the Transformer was such a breakthrough, you need to understand what researchers were struggling with before it arrived. The dominant approach for processing language before 2017 was a type of model called a Recurrent Neural Network, or RNN. The idea behind it was intuitive: read text the same way a human reads, one word at a time, from left to right, carrying a memory of what came before.
Imagine reading a book by looking at one word, remembering it, then moving to the next word, updating your memory, and continuing. That is roughly how an RNN worked. For short sentences, this was fine. But for anything longer, it started to break down very badly.
Picture someone who can only hold one thought in their head at a time. By the time they reach the end of a long paragraph, they have almost completely forgotten how it began.
That is the RNN’s core problem.
The further back a word was, the harder it was for the model to remember it. This made understanding long documents, complex questions, or anything requiring context from far back in a text extremely difficult.
There was a second problem too: speed. Because RNNs processed words one at a time in sequence, you could not process word ten until you had finished word nine. Training on large datasets was painfully slow. Scaling up was almost impossible.
Then in 2017, a team of researchers at Google published a paper titled “Attention Is All You Need.”
It introduced a radically different idea.
The Transformer.
The Transformer removed recurrence entirely. It did not process words one at a time. It looked at all words at once simultaneously and figured out how they related to each other in a single step. That is the idea that changed everything.
The Core Idea: Attention
At the heart of the Transformer is a mechanism called Attention. We will explore it in full detail in a later article, but here is the intuition.
When you read a sentence, you do not treat every word equally. Some words are more important than others. If someone says “The car could not fit 7 people because it was a sedan,” you know what “it” is referring to in this sentence. Your brain will automatically connect “it” to the car not to the people. You paid more attention to some words than others. You made connections across distance without reading word by word. Attention gives the Transformer the same ability. Every word in a sentence can look at every other word directly regardless of how far apart they are and decide how relevant each one is. There is no sequential bottleneck. No fading memory. All the connections happen in parallel, all at once.
The idea where every part of the input talks directly to every other part is called Attention and this is what makes the transformer so powerful and different from what came before it.
We will not go deeper than this right now. Just hold onto the core idea: full, parallel, direct attention across the entire input.
The Architecture Blocks: Encoder and Decoder
When the Transformer was first introduced, it was designed to solve a specific task: translation. Translating a sentence from English to Japanese, for example.
For this task, the architecture had two distinct parts working together:
- The Encoder — the reader
The Encoder reads the input sentence and builds a rich internal representation of its meaning, capturing how the words relate to each other. Think of it as a careful reader who truly understands the passage before moving on.
- The Decoder — the writer
The Decoder takes that internal representation and generates the output sentence one token at a time. Think of it as a careful writer who uses the reader’s understanding to produce a clear and accurate response.
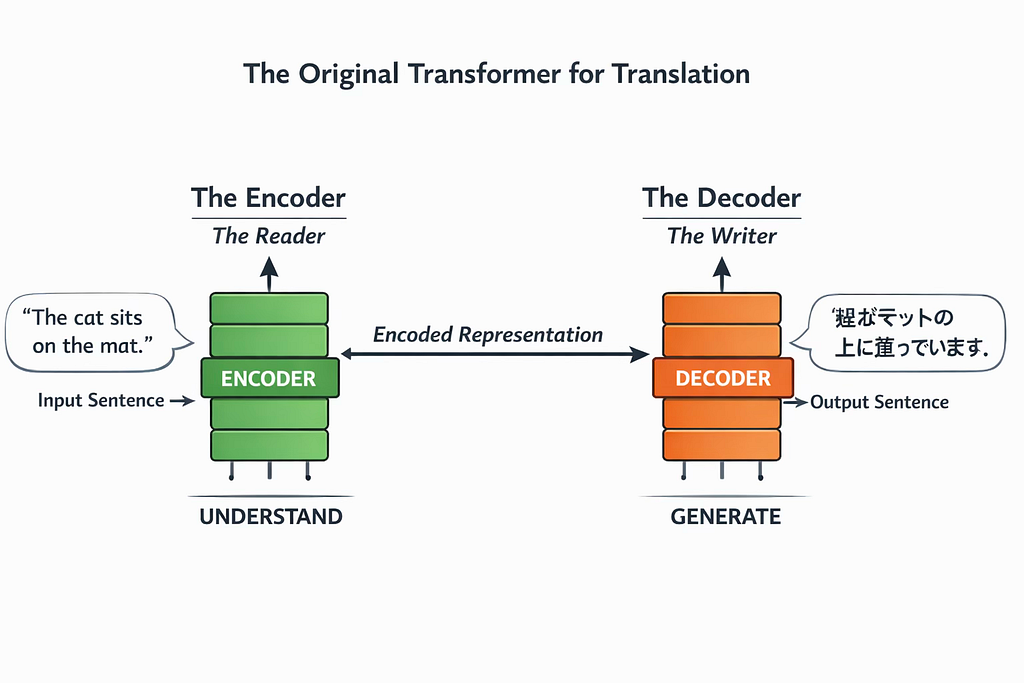
Together, they form a complete pipeline: understand the input, generate the output. This original design was built for translation, but it planted the seed for everything that followed.
Three Ways Transformers Are Used Today
As researchers explored the Transformer, they discovered something important: not every task needs both an Encoder and a Decoder. Depending on what you want the model to do, you might only need one or you might use both in a new way.
Today, almost every major AI model fits into one of three patterns.
- Encoder-Only (Understanding models)
If your goal is to understand something, you use an encoder-only model. They are excellent at reading and understanding text but do not generate new content. These models read input and produce a decision, a label, or a score. For example, detecting fraud in a transaction, classifying an email as spam, or determining the sentiment of a customer review. Nothing new is being written here, the system is simply making a judgment. The most well-known example is BERT, developed by Google.
- Decoder-Only (Generation models)
If your goal is to generate something new, you use a decoder-only model. These models create text one word at a time. Chatbots, writing assistants, and code generators fall into this category. They are not just analyzing input, they are producing new content.
This is the architecture behind every large language model you interact with today.
ChatGPT, Claude, Gemini, and LLaMA, all of these are Decoder-only models. When you type a question and receive a response, a Decoder is generating every single word of that answer in sequence.
- Encoder–Decoder (Transformation models)
These models use both components, just as the original Transformer did. They are ideal for tasks where you need to understand one thing and produce something different from it.
Translation is the classic example: understand English (Encoder), generate French (Decoder). Summarization is another: understand a long document (Encoder), generate a short summary (Decoder). T5 and BART are well-known examples of this pattern.
A simple way to remember the three: Encoder-only models read. Decoder-only models write. Encoder–Decoder models read and then write.
Two Terms Worth Understanding Now
Before we go any further, two terms will come up constantly as you read about Transformers. It is worth understanding them now at a basic level, even before we get into the details.
- Token
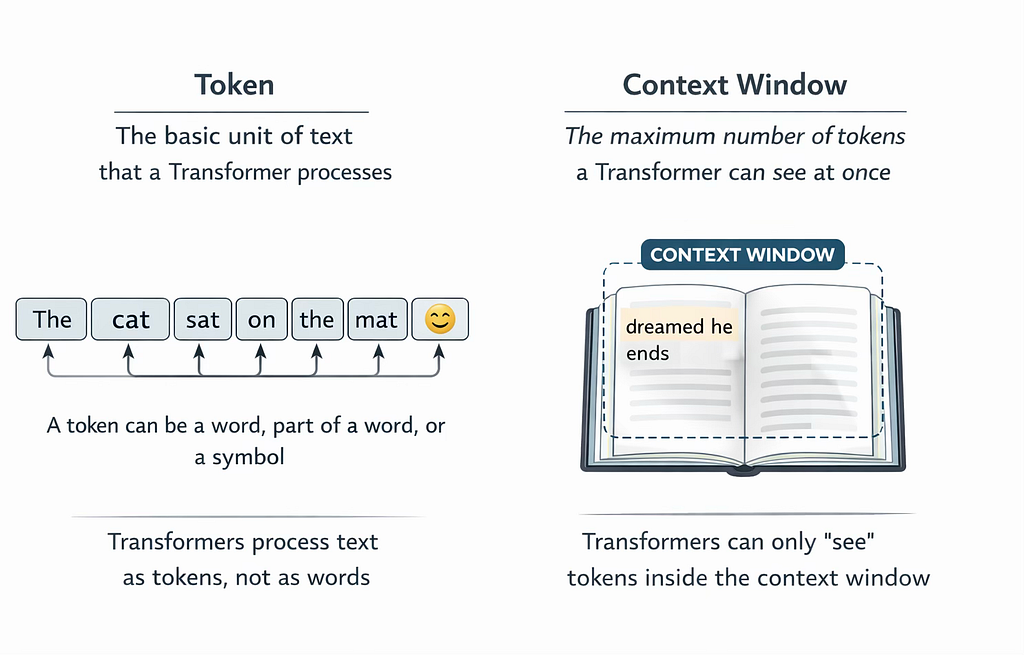
A token is the basic unit of text that a Transformer processes. It is not always a whole word. Sometimes it is a word, sometimes a part of a word, and sometimes a single character or punctuation mark.
The word “unbelievable” might be broken into three tokens “un”, “believ”, and “able”. The word “cat” is likely one token. An emoji might be one token. A space before a word might even be included in its token.
Why does this matter?
Because Transformers do not see words, they see tokens. Everything the model reads, understands, and generates is measured in tokens, not words. We will explore this in full detail in the Embeddings article.
- Context Window
The context window is the maximum number of tokens a Transformer can process at one time. Think of it as the model’s working memory, everything inside the context window is what the model can “see” and reason about. Everything outside it is invisible.
Imagine you are given a very long article to read, but you can only look at a certain number of pages at once. The pages you can see are your context window. Anything beyond those pages is out of reach until you slide the window forward.
Early models had small context windows, a few hundred tokens. Modern models like Claude Opus 4.6 has context windows of up to 1M tokens, allowing it to process entire books, codebases, or long conversations in a single pass. The size of the context window has a direct impact on what a model can do. A model with a small context window cannot answer questions about a long document because it simply cannot hold it all in view at once.
A Glimpse Inside: What Lives in Each Block
We have talked about the Encoder and Decoder as if they are single units. In reality, each one is made up of several distinct layers working in sequence.
We are not going to explain each one now, that is exactly what the next several articles are for. But it is worth knowing their names so they are not unfamiliar when we get there.
Inside every Transformer block whether Encoder or Decoder, you will find:
- Embeddings — the layer that converts tokens into numbers the model can work with.
- Positional Encoding — a signal that tells the model where each token sits in the sequence.
- Attention Layers — the mechanism that lets every token look at every other token and decide what matters.
- Feed-Forward Layers — layers that process each token individually after attention has been applied.
- Residual Connections and Layer Normalization — structural elements that keep the model training stable and allow the model to grow very deep without breaking down.
Each of these will get its own article and will be explained from the ground up with intuition before any technical detail. By the time we are done with the Encoder, you will be able to trace exactly what happens to a single word from the moment it enters the model to the moment it exits as a rich, contextualized representation.
What This Series Will Build
This article was the map. Now we know where we are going. We have seen why the Transformer replaced RNNs, how attention connects every token to every other token, and how the three patterns, encoder-only, decoder-only, and encoder–decoder, are used in practice. We have also named the key components inside each block.
From here, now that we understand the overall architecture, it’s time to zoom in.
In the next article, we will start with the encoder, the half of the Transformer that learns to read. What exactly goes in, what comes out, and how does it transform raw text into structured meaning?
Next, we focus on the Encoder, just the big picture for now.
Why the Transformer Changed AI Forever was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.