TurboSparse-LLM Performance: Outperforming Mixtral and Gemma with Extreme Sparsity
Table of Links
-
Analysis
-
Experiments Results
-
Practical Inference Speedup Evaluation
A. Appendix / supplemental material
6 Experiments Results
6.1 Downstream Tasks Performance
We measure our sparsified models’ performance on tasks included in OpenLLM Leaderboard which include 25-shot Arc-Challenge [13], 10-shot Hellaswag [65], 5-shot MMLU [22], 0-shot TruthfulQA [35], 5-shot Winogrande [51] and 8-shot GSM8K [14]. In addition, we also follow Llama 2’s evaluation task included commonsense reasoning tasks. We report the average of PIQA [8], SCIQ [26], ARC easy [13], OpenBookQA [41]. We compare our models to several external open-source LLMs, including Gemma-2B [58], Mistral-7B [24] and Mixtral-47B [25].
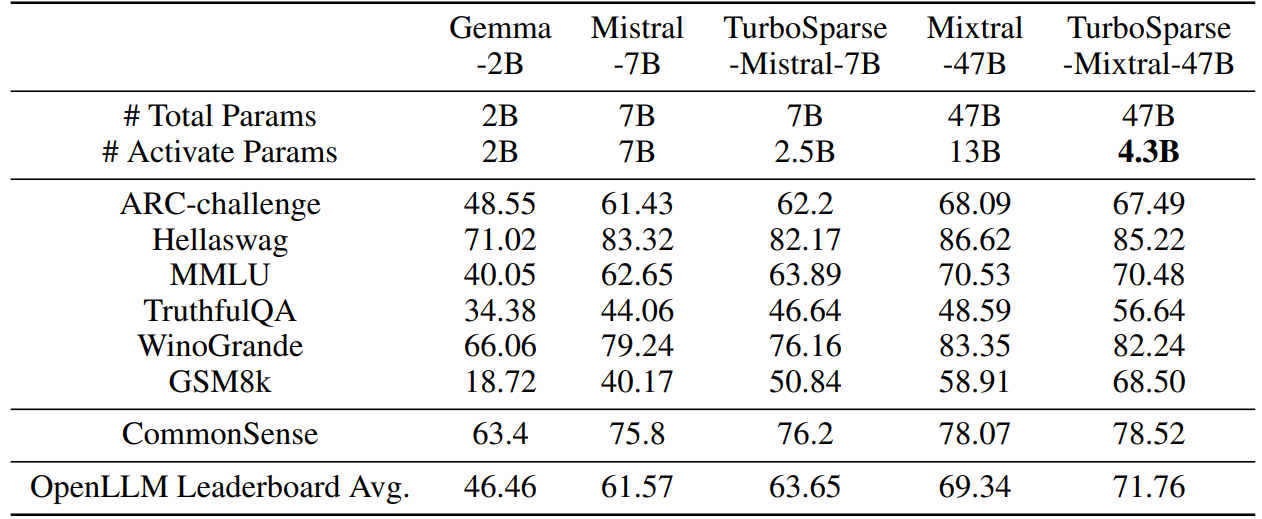
Table 6 shows the results from different models. TurboSparse-Mistral-7B outperforms Gemma-2B by far, while only activating 3B parameters. TurboSparse-Mixtral-47B outperforms the original Mixtral-47B with only 4.5B parameters activated. The results demonstrate that LLMs with ReLU based intrinsic activation sparsity can keep the same or better performance while hold the significant FLOPs reduction.
:::info
Authors:
(1) Yixin Song, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(2) Haotong Xie, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(3) Zhengyan Zhang, Department of Computer Science and Technology, Tsinghua University;
(4) Bo Wen, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(5) Li Ma, Shanghai Artificial Intelligence Laboratory;
(6) Zeyu Mi, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University Mi yzmizeyu@sjtu.edu.cn);
(7) Haibo Chen, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University.
:::
:::info
This paper is available on arxiv under CC BY 4.0 license.
:::