
NVIDIA Taught LLMs to Forget — And They Got Smarter
A technical deep dive into Dynamic Memory Sparsification: how compressing an LLM’s memory by 8× can improve its reasoning
On January 19, 2026, NVIDIA released a model on HuggingFace called Qwen3-8B-DMS-8x. As of this writing, it has minimal community engagement — a handful of likes and a few hundred downloads.
The model implements a technique from a paper called “Inference-Time Hyper-Scaling with KV Cache Compression” (arXiv:2506.05345), presented at NeurIPS 2025 by researchers at NVIDIA and the University of Edinburgh. The core claim sounds counterintuitive: compress an LLM’s working memory by 8× and it gets better at certain tasks — particularly long-context reasoning and retrieval.
After reading the paper and examining the model card, here’s what the technique actually does, where the results hold up, and where they don’t.
The Problem: LLMs Are Memory-Bound, Not Compute-Bound
When people discuss LLM costs, they talk about parameters. “70 billion parameters needs 140GB of VRAM.” That’s the model weights — the fixed knowledge baked in during training. It’s a real cost, but it’s a static cost. Load the model once, and you’re done.
The cost that gets less attention is the KV cache.
Every time an LLM generates a token, it computes a Key vector and a Value vector for the attention mechanism. These get stored in what’s called the KV cache — the model’s short-term working memory. Without it, the model would need to reprocess the entire conversation history for every single token. With it, generation is 10–20× faster.
The catch: the KV cache grows linearly with sequence length. For every token in the context — both input and generated — the model stores K and V vectors across every layer and every attention head.
Here’s a concrete calculation for Qwen3–8B:
- 36 layers
- 4 KV heads (Grouped Query Attention)
- 128 dimensions per head
- BF16 precision (2 bytes per value)
At the native context length of 32,768 tokens:
KV cache = 2 (K+V) × 36 layers × 4 heads × 128 dim × 32,768 tokens × 2 bytes
≈ 1.2 GB
That might sound manageable for a single user. But in a production setting with dozens or hundreds of concurrent users, these caches stack up. For a larger model like Llama 3.1–70B at 128K context, the KV cache alone consumes roughly 40GB of HBM — more than the entire VRAM of most consumer GPUs.
This matters because LLM inference is memory-bandwidth bound during the decode phase (generating tokens one at a time). The GPU loads the entire KV cache from memory for each token. The arithmetic is trivial — a few matrix-vector multiplications. The data transfer is massive. The GPU sits largely idle, waiting for memory.
So the question becomes: can we make the KV cache smaller without making the model dumber?
What DMS Actually Does
Dynamic Memory Sparsification is NVIDIA’s answer. The paper is by Adrian Łańcucki, Konrad Staniszewski, Piotr Nawrot, and Edoardo Ponti. Here’s how it works, stripped of marketing language.
Prior Approaches and Their Tradeoffs
Before DMS, the main strategies were:
Sliding window attention — only keep the last N tokens in the cache. Simple, but you lose everything before the window. If the answer to a question was 10,000 tokens ago, it’s gone.
Heuristic-based eviction (H2O, TOVA, Quest) — use attention scores or other signals to guess which tokens are “unimportant” and drop them. These work at low compression ratios (2–4×) but degrade significantly at higher ratios. The fundamental problem: attention patterns shift as generation continues, so a token that seemed unimportant at step 100 might be critical at step 10,000. These methods have no way to adapt because they don’t involve any learning.
Dynamic Memory Compression (DMC) — the direct predecessor to DMS, from the same research group (Nawrot et al., ICML 2024). DMC trains the model to merge tokens together via weighted averaging rather than evicting them. It works well up to about 4× compression but requires continued pre-training on a meaningful portion of the original data. At 8× compression, DMC’s accuracy degrades more than DMS.
DMS takes a different path.
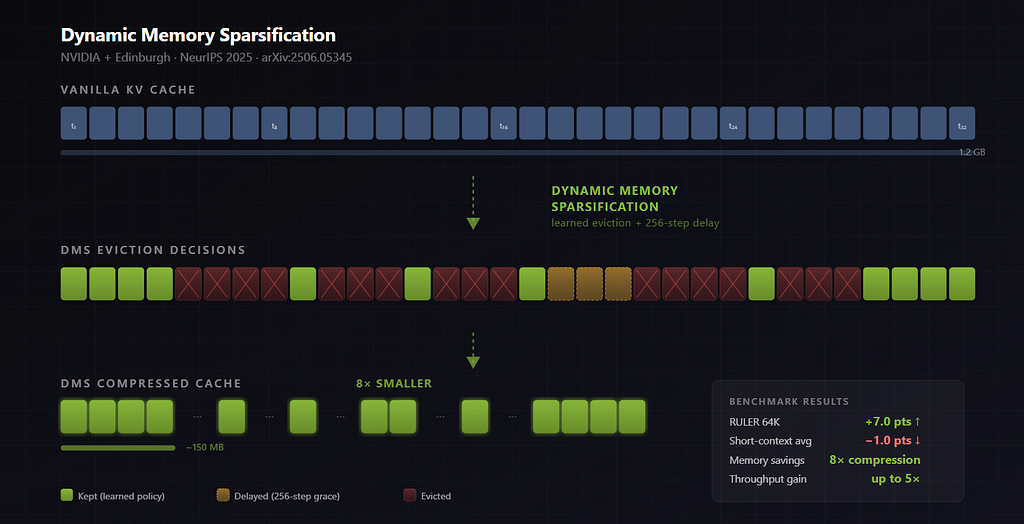
The Core Mechanism: Learned Eviction with Delayed Removal
Instead of guessing which tokens to drop, DMS trains the model itself to make eviction decisions. There are four key components:
1. Repurpose a single neuron per attention head. For each KV head, DMS repurposes one dimension from the key projection to output a binary keep/evict signal. No new parameters are added. The model’s existing architecture is reused. This is what makes the approach lightweight — there are no additional layers or adapters.
2. Make the binary decision differentiable. During training, the hard keep/evict decision is relaxed using Gumbel-sigmoid sampling. This is a standard technique from variational inference that lets you backpropagate through discrete choices by adding noise from a Gumbel distribution and applying a sigmoid instead of a hard threshold. At inference time, the decision reverts to a hard binary.
3. Delayed eviction (the key innovation). When a token is flagged for eviction, it is NOT deleted immediately. It stays in the cache for 256 more generation steps (this is the default setting in the paper). During this grace period, the model can still attend to the doomed token and extract whatever information it needs before the token is actually removed.
The researchers’ ablation studies confirm this is crucial. Removing the delay and doing immediate eviction caused significant accuracy drops, particularly on long-context tasks. The intuition: many tokens are neither clearly “keep forever” nor “useless right now.” They carry transient information that the model needs a few steps to absorb.
4. Logit distillation. The retrofitting uses the original model as a teacher and the DMS-modified model as a student. The student learns to match the teacher’s full output probability distribution over next tokens — not just the correct answers, but the entire logit vector. This is more robust than training on a specific dataset because it preserves the model’s general behavior.
The entire retrofitting process uses a linear schedule: compression ratio ramps from 1× (no compression) to the target (e.g., 8×) over approximately 1,000 training steps. The paper used 36 million tokens from the OpenR1-Math-220k dataset. This is dramatically less data than DMC required, though the paper describes it as “much more sample-efficient” without giving an exact ratio.
What Inference Looks Like
Once retrofitted, the model during inference:
- Each KV head independently decides which tokens to evict using its learned policy
- Evicted tokens are flagged but kept for the 256-step delay window
- After the delay, flagged tokens are overwritten by incoming ones
- The attention mask is updated to exclude evicted tokens
- Standard FlashAttention and PagedAttention CUDA kernels are used — no custom GPU code is needed
A clarification on “custom code”: the model requires trust_remote_code=True on HuggingFace because the Python-level attention masking logic is custom (it implements the eviction and delay mechanism). But the underlying GPU kernels — FlashAttention, PagedAttention — are standard. This is what Nawrot meant when he told VentureBeat that no custom CUDA kernels are required.
The model learns different sparsification patterns per head. Some heads keep nearly everything (full attention). Others aggressively compress to a sliding window of 512 tokens. The paper found that the model naturally preserves more tokens in early sequence positions and compresses more aggressively later — which makes intuitive sense, as early tokens often carry structural information (system prompts, task instructions) while later tokens may be more redundant.
The Results: Honest Assessment
Here are the actual numbers from the HuggingFace model card, comparing vanilla Qwen3–8B against the DMS variant at 8× KV cache compression.
Direct Head-to-Head: Qwen3–8B vs Qwen3–8B-DMS-8x
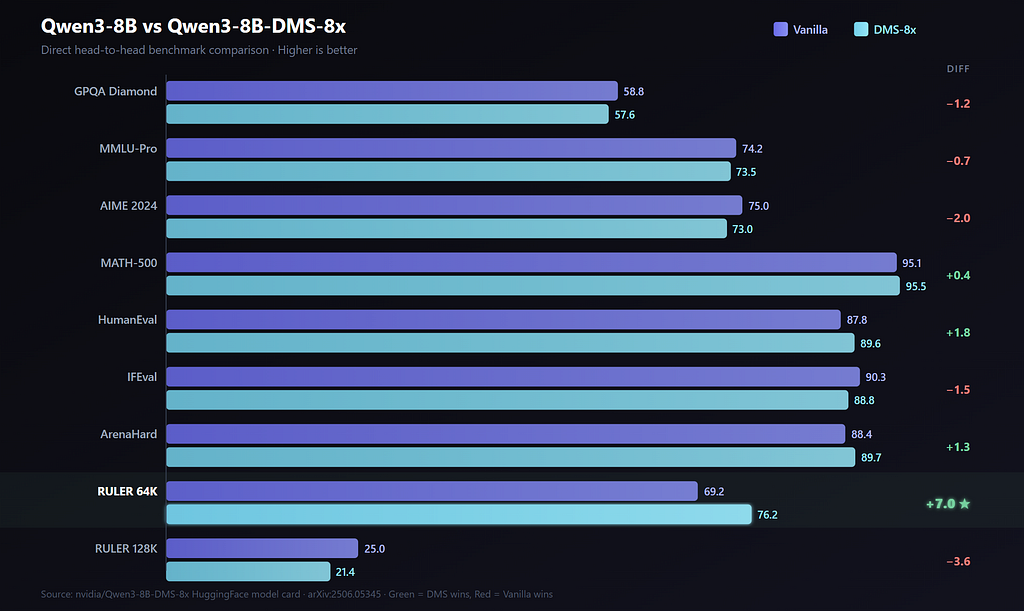
What These Numbers Tell Us (And Don’t Tell Us)
On short-context tasks, DMS is a small net negative. Look at the left side of the table: GPQA (−1.2), MMLU-Pro (−0.7), AIME (−2.0), IFEval (−1.5). These are real drops, not rounding errors. If you’re doing standard chatbot work, short-form Q&A, or single-turn reasoning, DMS trades a few accuracy points for 8× memory compression. Whether that trade is worth it depends entirely on your deployment constraints.
The wins on HumanEval (+1.8) and ArenaHard (+1.3) partially offset this, but the honest summary for short-context tasks is: DMS is not free. It costs you 1–2 points on average.
RULER 64K is the genuine standout: +7.0 points. This is a long-context benchmark that measures retrieval and reasoning over information spread across 64K tokens. The researchers’ explanation: with full attention, the model attends to thousands of irrelevant tokens, essentially drowning in noise. DMS forces it to focus on what its learned policy identified as important. Whether you call this “compression improves quality” or “full attention wastes capacity” is a matter of framing — but the result is real.
RULER 128K drops by 3.6 points. At 128K tokens, 8× compression means the model retains only about 16K tokens worth of KV cache. That’s aggressive. The delay window of 256 tokens means the model has roughly 256 steps to extract information from a token before it’s gone, but at extreme lengths, important context can still get permanently lost.
The strongest case for DMS is the iso-budget comparison. The paper’s Table 3 (on the larger Qwen-R1 32B) shows what happens when you constrain both models to the same memory budget: the DMS model scores +12.0 on AIME 24, +8.6 on GPQA Diamond, and +9.7 on LiveCodeBench compared to vanilla. The mechanism is straightforward: with 8× less memory per reasoning chain, DMS can explore more reasoning paths in parallel (or think longer on a single chain) before hitting the memory ceiling. The vanilla model runs out of room and has to stop.
This is the real argument for DMS: it doesn’t make individual predictions much better or worse. It changes the resource economics of inference-time scaling.
What’s Missing from the Evaluation
A few things I’d want to see that aren’t in the paper or model card:
- Latency per token, not just throughput. The paper reports up to 5× throughput improvement for Qwen3–8B, but throughput and per-request latency can move differently depending on batching.
- Variable compression ratios. What if you use 4× for 128K context and 8× for shorter contexts? The paper trains at fixed ratios.
- Domain-specific tasks. All benchmarks are academic (math, code, science, instruction-following). What about summarization, translation, or retrieval-augmented generation?
- Independent reproduction. All numbers come from the paper authors. The model is public, but nobody outside NVIDIA/Edinburgh has published independent validation yet.
Practical Considerations
How to Use the Model
The model is on HuggingFace. Here’s the minimal code:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-8B")
model = AutoModelForCausalLM.from_pretrained(
"nvidia/Qwen3-8B-DMS-8x",
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True, # CRITICAL: loads DMS attention code
)
The trust_remote_code=True flag loads NVIDIA’s custom attention masking logic. Without it, you get standard Qwen3 attention and zero DMS benefits — the model runs but the eviction policy is inactive. The model card explicitly warns about this.
Hardware Requirements
You need an NVIDIA GPU with at least 24GB VRAM (RTX 3090/4090, A100, or H100). The model is 8.2B parameters in BF16, consuming approximately 16GB for weights alone. CPU inference is not supported because DMS relies on custom PyTorch attention code that hasn’t been ported to CPU-only frameworks like llama.cpp.
License
The model uses the NVIDIA Non-Commercial License. Research and educational use only. You cannot deploy this in production without a separate commercial agreement with NVIDIA.
What DMS Does NOT Help With
Prefill latency is unchanged — DMS doesn’t affect how fast the model processes your input prompt. The speedup is only during the auto-regressive decode phase.
Single-turn, short-context tasks see roughly neutral accuracy (slight net loss). DMS gives you memory savings here, but not quality gains.
Training is unaffected. DMS is purely an inference-time optimization.
CPU/Edge deployment is not currently possible. DMS requires PyTorch + GPU. The custom attention logic can’t be converted to GGUF or run in llama.cpp or Ollama. In theory, the smaller KV cache could help on bandwidth-constrained devices, but the implementation doesn’t support this today.
Real Limitations
Only one public checkpoint exists. NVIDIA released Qwen3–8B-DMS-8x. No Llama variants, no 1.5B or 32B sizes, despite the paper evaluating across multiple model families. If you want DMS on a different model, you need to retrofit it yourself.
Retrofitting requires significant infrastructure. The paper describes retrofitting on “a single DGX H100.” If you want to apply DMS to your own model, you need access to high-end GPU infrastructure and familiarity with NVIDIA’s KVPress library. This is not a pip install.
8× compression is a fixed ratio. You can’t dynamically adjust compression based on context length or task difficulty. The model was trained at 8× and that’s what it does. Lower ratios (4×) would likely preserve more accuracy on 128K contexts, but would need separate training runs.
The delay window is fixed at 256 tokens. The paper mentions 256 as the default but doesn’t extensively ablate other values. It’s possible that longer delay windows could help at extreme context lengths, at the cost of less aggressive compression.
DMS in Context: Why This Matters
DMS is part of a broader shift in how the field thinks about LLM efficiency. The previous era was about making models smaller — quantization, pruning, distillation. The current era is about making the runtime smarter: doing more useful work within the same memory and compute budget.
The specific insight is that the KV cache is not sacred. The standard Transformer stores every token with equal priority, but not all tokens are equally useful. Structural tokens (system prompts, task delimiters) are important throughout generation. Many intermediate tokens are only useful for a few hundred steps. DMS lets the model learn which is which.
Whether DMS specifically becomes the standard approach is unclear. It has competition: KV cache quantization (FP8 or even FP4) is simpler and composable with DMS. Multi-Head Latent Attention (as in DeepSeek-V3) compresses KV representations through low-rank projection at the architecture level. Native Sparse Attention retrieves only relevant chunks rather than compressing globally.
What’s notable about DMS is the cost of adoption: approximately 1,000 training steps to retrofit an existing model with no architectural changes and no new parameters. That’s low enough that it could become a standard post-training optimization step, like quantization is today.
The challenge will be moving from one research checkpoint to broad ecosystem support — integration into vLLM, TensorRT-LLM, and SGLang serving frameworks, GGUF compatibility, and adaptive compression ratios. Until that happens, DMS remains a promising research result, not a production tool.
The paper “Inference-Time Hyper-Scaling with KV Cache Compression” (arXiv:2506.05345) is available on arXiv. The model checkpoint is at nvidia/Qwen3–8B-DMS-8x on HuggingFace. The retrofitting code is in NVIDIA’s KVPress library.
NVIDIA Taught LLMs to Forget — And They Got Smarter was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.