
I Built an AI That Fixes Pipeline Failures Before Platform or DevSecOps teams Gets the Slack…
🤖 I Built an AI That Fixes Pipeline Failures Before Platform or DevSecOps teams Gets the Slack Message

📉 The Slack Notification That’s Crushing Your Sprint Velocity
“Hey, the pipeline failed again. Can you check?”
Whether it’s 2 AM production calls or during business hours, your phone buzzes. You squint at Slack — another developer hasn’t even *looked* at the error logs. They just pinged you. Again. Meanwhile, your actual engineering tasks? Delayed. Your sprint commitments? Slipping.
Sound familiar?
If you’re on a Platform, or DevSecOps team, this is your daily reality. Developers don’t read error logs most of the time. They screenshot red X’s and ask, “Can you fix this?” Meanwhile, you’re playing detective through terraform traces, kubectl describes, and npm error dumps.
🤔 “But wait, doesn’t my CI/CD tool have AI features now?
Sure. Many platforms are adding AI capabilities. But here’s the problem:
– ❌ They don’t understand *your* organizational standards and policies
– ❌ You can’t customize them with your company’s best practices
– ❌ They’re generic — trained on public data, not your codebase patterns
– ❌ Vendor lock-in — you’re stuck with whatever they decide to build
– ❌ Can’t inject your known failure patterns and compliance rules
💡 What if you could build something better? A pipeline that truly understands YOUR context and diagnoses itself?
I Got Tired of Being a Human Log Parser
After the 47th “npm test failed, help!” message (where the error literally said `package.json not found`), I’d had enough.
So, I built something different: An AI-powered failure analyzer that tells developers EXACTLY what’s wrong and how to fix it — right in the pipeline output.
No Slack. No tickets. No context switching. Just instant, actionable answers.
Here’s What It Looks Like in Action
Example 1: NPM Test Failure
Before: The Typical Developer Experience
❌ Run Tests Failed
Error: Process completed with exit code 1
npm ERR! code ENOENT
npm ERR! syscall open
npm ERR! path /home/runner/work/project/package.json
npm ERR! errno -2
npm ERR! enoent ENOENT: no such file or directory, open '/home/runner/work/project/package.json'
npm ERR! enoent This is related to npm not being able to find a file.
Developer:” I’ll ask DevOps…” 😕
After: With AI Analysis

Developer:” Oh, I’ll fix that.” ✅
Example 2: Helm Deployment Failure
Before: The Typical Developer Experience
❌ Helm Install Failed
Error: timed out waiting for the condition
Developer:” I’ll ask DevOps…”

Developer:” Got it, fixing now. And I’ll add those kubectl commands to my pipeline for next time.” ✅
Example 3: Terraform Validation Failure
Before: The Typical Developer Experience
❌ Terraform Validate Failed
Error: Error: Unsupported argument
Developer:” I’ll ask DevOps…”
After: With AI Analysis
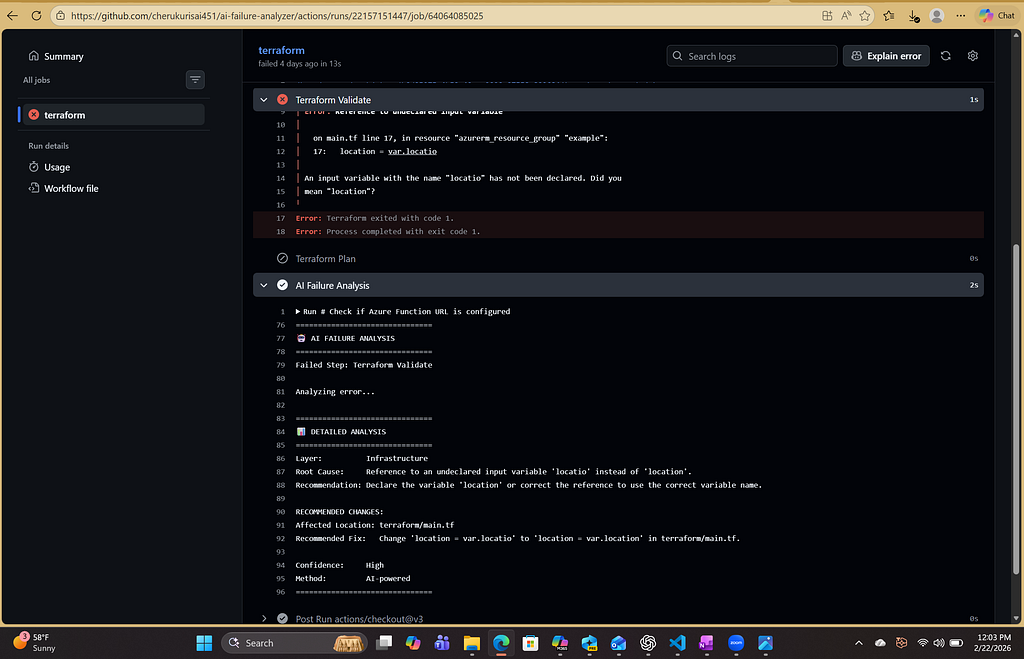
Developer:” Makes sense, changing it.” ✅
Example 4: Git Authentication Failure (Rule-Based)
Before: The Typical Developer Experience
❌ Clone Private Repo Failed
Error: Process completed with exit code 1
Cloning repository...
fatal: could not read Username for 'https://github.com': No such device or address
Permission denied (publickey).
fatal: Could not read from remote repository.
Developer:” I’ll ask DevOps…” 😕
After: With Rule-Based Analysis

Developer:” Ah, permissions issue. Let me check with the Platform team — they manage our tokens.” ✅
🔬 The Secret Sauce: Rule-Based + AI Hybrid Approach
I didn’t want another chatbot. I wanted something that understands *pipeline failures* specifically.
So, I built a hybrid system that combines the best of both worlds:
1. Rule-Based Analysis (Standards & Policies)
Injected our organization’s coding standards and best practices
Pre-configured common failure patterns
Fast, deterministic checks for known issues
Enforces company-specific policies and compliance requirements
2. AI-Powered Deep Analysis (Custom Model)
When rules don’t match, custom AI model takes over
Custom prompts tuned for infrastructure and deployment errors
Understands context across multiple files and configurations
Learns from error patterns we haven’t seen before
3. Smart Context Capture
Not just “npm failed” but the actual error output
Pod descriptions for Kubernetes issues
Terraform validation errors with line numbers
Relevant configuration files (values.yaml, package.json, etc.)
4. Actionable Intelligence
“Change X to Y in file Z”
Not vague suggestions like “check your config”
Includes confidence level so devs know when to escalate
🏗️ System Architecture
Here’s how it all flows together:
┌─────────────────────────────────────┐
│ GitHub Actions Pipeline │
│ (or any CI/CD platform) │◄──── Developer pushes code
└───────────────┬─────────────────────┘
│
│ ❌ Pipeline Failure
▼
┌─────────────────────────────────────┐
│ Error Context Capture │
│ • Build/test logs │
│ • Config files (values.yaml, etc) │
│ • Pod status (Kubernetes) │
│ • Terraform output │
└───────────────┬─────────────────────┘
│
▼
┌─────────────────────────────────────────────────────┐
│ (Serverless) │
│ │
│ ┌───────────────────────────────────────────┐ │
│ │ Rule-Based Analysis Engine │ │
│ │ • Organizational Standards │ │
│ │ • Common Failure Patterns │ │
│ │ • Policy Compliance Checks │ │
│ └───────────────┬───────────────────────────┘ │
│ │ │
│ Known Issue? │ │
│ ✓ │ ✗ Unknown Issue │
│ │ └──────────────┐ │
│ │ ▼ │
│ │ ┌─────────────────────────┐ │
│ │ │ Custom AI Model │ │
│ │ │ • Custom Prompts │ │
│ │ │ • Context Analysis │ │
│ │ │ • Root Cause Detection │ │
│ │ └─────────────────────────┘ │
│ │ │ │
│ └───────────┬───────────┘ │
│ ▼ │
│ ┌─────────────────────────────────────────┐ │
│ │ Response Generation │ │
│ │ • Root Cause Identified │ │
│ │ • Affected File/Location │ │
│ │ • Exact Fix Instructions │ │
│ │ • Confidence Level │ │
│ └─────────────────────────────────────────┘ │
└───────────────┬─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ Pipeline Output (UI) │
│ 🤖 AI FAILURE ANALYSIS │
│ 📊 Root Cause + File Location │
│ 🔧 Step-by-Step Fix │
│ ✅ Confidence: High/Medium/Low │
└───────────────┬─────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ Developer Action │
│ • Reads clear explanation │
│ • Applies fix immediately │
│ • No DevOps interruption needed ✅ │
└─────────────────────────────────────┘
The Flow:
1. Pipeline Fails → Error logs, config files, and context captured
2. Rule Engine → Checks against organizational standards and known patterns
3. AI Analysis → If rules don’t match, custom AI model analyzes with tailored prompts
4. Response → Developer gets exact file location, root cause, and fix steps
5. Resolution → Developer applies fix or auto-fix PR is created
The entire process takes 2–5 seconds from failure to actionable recommendation.
📊 The Impact: Measured in Hours Saved
Before:
– Average resolution time: 45 minutes
– 60% of issues: developers didn’t read logs
– Platform team: interrupt-driven firefighting
After:
– 80% of issues: self-service fixes
– Developers get answers in seconds
– Platform team: focused on actual platform work
🛠️ You Can Build This Too
The architecture is straightforward and cloud-agnostic:
✅ Serverless Function: (Azure Functions, AWS Lambda, or Google Cloud Functions)
✅ AI Model: (Azure OpenAI, AWS Bedrock, or Google Vertex AI — deployed as custom model for this POC)
✅ CI/CD Integration: (Works with GitHub Actions, Harness, GitLab CI, Jenkins, Azure DevOps, or any pipeline)
✅ Multi-Stack Support: (npm, Docker, Kubernetes, Terraform, Helm, and any build/deployment tool)
No vendor lock-in. Choose your cloud provider and AI service. The concept works across all major platforms.
🚀 The Future: Self-Healing Pipelines?
Right now, it *diagnoses*.
Next step? Auto-fix pull requests.
Imagine:
1. Pipeline fails on invalid Kubernetes CPU value
2. AI detects: `cpu: INVALID_VALUE` in values.yaml
3. Bot creates PR: “Fix: Change cpu to 100m”
4. Developer reviews and merges
5. Pipeline passes
From failure to fix in 30 seconds. No human parsing logs.

💥 The Bottom Line: This Changes Everything
Every platform or DevOps team on the planet faces this problem. From startups to Fortune 500 companies, the cycle is the same:
Developer breaks pipeline
DevOps drops everything to read logs
Manual explanation of obvious error
Repeat 50 times a day
**I built this AI agent because I got tired of being a log-reading service.**
This isn’t just another automation script. It’s a **fundamental shift** in how we think about developer independence and platform or DevOps team efficiency.
The Real Impact:
Your platform or DevOps team stops being interrupt-driven
Developers solve their own issues in seconds, not hours
Your organizational knowledge is baked into every analysis
You own the code — no vendor dictating features or pricing
It works across every tool in your stack
**What took me 45 minutes to debug now takes developers 45 seconds to fix themselves. **
That’s not just time saved. That’s your platform engineers building the future instead of explaining the past.
This is what modern platform engineering looks like — **systems that scale knowledge, not just infrastructure. **
💬 Want to stop being your team’s human error parser?
I’ve built the complete architecture — rule engine, custom AI integration, and deployment framework — that’s already saving platform teams hours every week.
**Let’s talk.** Visit my portfolio to get in touch if you’re ready to:
Cut your team’s pipeline debugging time by 80%
Give developers self-service failure diagnosis
Finally focus on building features instead of reading logs
Portfolio: Click Here
The code isn’t open source, but the conversation is. Let’s build something powerful for your team.
*Have a platform engineering or DevOps story? Drop it in the comments — I’d love to hear how other teams are scaling their operations. *
🤖 I Built an AI That Fixes Pipeline Failures Before Platform or DevSecOps teams Gets the Slack… was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.