
Catalog Audit Pipeline Using XGBoost
What is the business statement?
The goal was to reduce inventory waste — such as excess, damaged, or unsellable goods — while simultaneously ensuring fulfillment centers operate in compliance with environmental, safety, and operational regulations. We wanted to classify amazon inventory into 10 categories like Food, Electronics, Aerosols etc. — so that we can simply dispose those.
Could you clearly list the categories you were trying to have for the inventory?
- Aerosols
Keywords: Deodorants, body sprays, air fresheners, disinfectant sprays. - Hair Care Liquids
Keywords: Shampoos, conditioners, hair serums, hair oils. - Bath & Body Wash
Keywords: Body wash, shower gel, liquid soap. - Creams, Lotions & Moisturizers
Keywords: Face cream, body lotion, ointments, balms. - Bar Soaps & Solid Personal Care
Keywords: Soap bars, solid deodorants, sticks. - Oral Care Products
Keywords: Toothpaste, mouthwash, dental hygiene items. - Household Cleaning Liquids
Keywords: Floor cleaner, surface cleaner, toilet cleaner, dishwash liquid. - Laundry & Detergents
Keywords: Washing powder, liquid detergent, fabric softener. - Paper & Hygiene Consumables
Keywords: Tissues, wipes, napkins, paper towels, sanitary products.
How are you sourcing the data for the algorithm?
We are getting structured data from Redshift clusters. We don’t have a robust labelled dataset so we create labels using item_name for example if the name has deodorant then it goes into Aerosol Bucket and similar rules for other categories. We are using zero shot transfer learning algorithm to get the labels for all instances. The zero shot algorithm gives us confidence for each record to lie in a certain category (for exmple 0.90 for Aerosol). For all the records we filter out on confidence interval to lie in a certain range, also we are looking at rule based algorithm to classify those records into categories.
Could you describe features in your dataset?
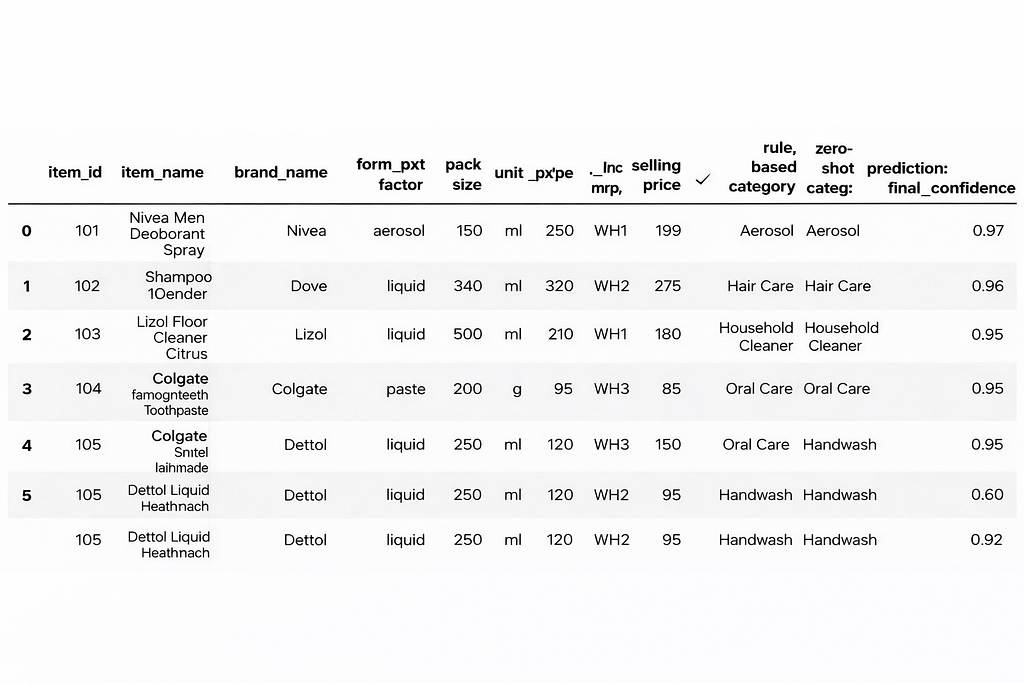
What is the overall approach to solve for this problem ? Give a flow chart.
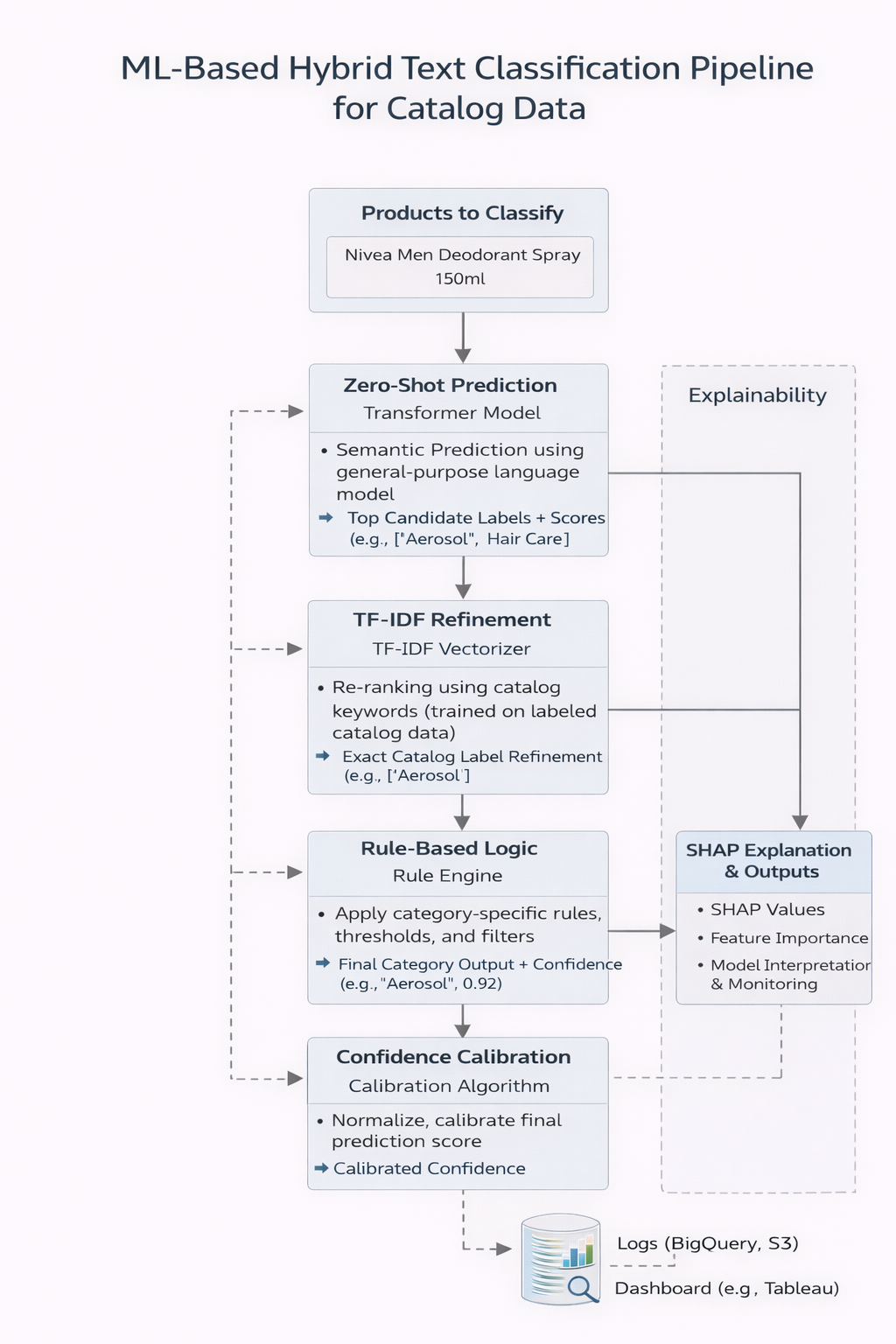
- Zero-shot and TF-IDF act as upstream signal generators → They provide semantic scores, keyword similarities, and candidate labels, but do not finalize the decision.
- XGBoost is the supervised decision layer → It takes all engineered features (zero-shot confidence, TF-IDF similarity, rules, metadata like brand/form/pack size) and learns the optimal boundary from labeled data.
- Therefore, the final category label comes from XGBoost prediction → This ensures the output is data-driven and calibrated to catalog ground truth, not just heuristic.
- Confidence calibration happens after XGBoost → The probability from XGBoost is re-calibrated before being shown in dashboards or downstream systems.
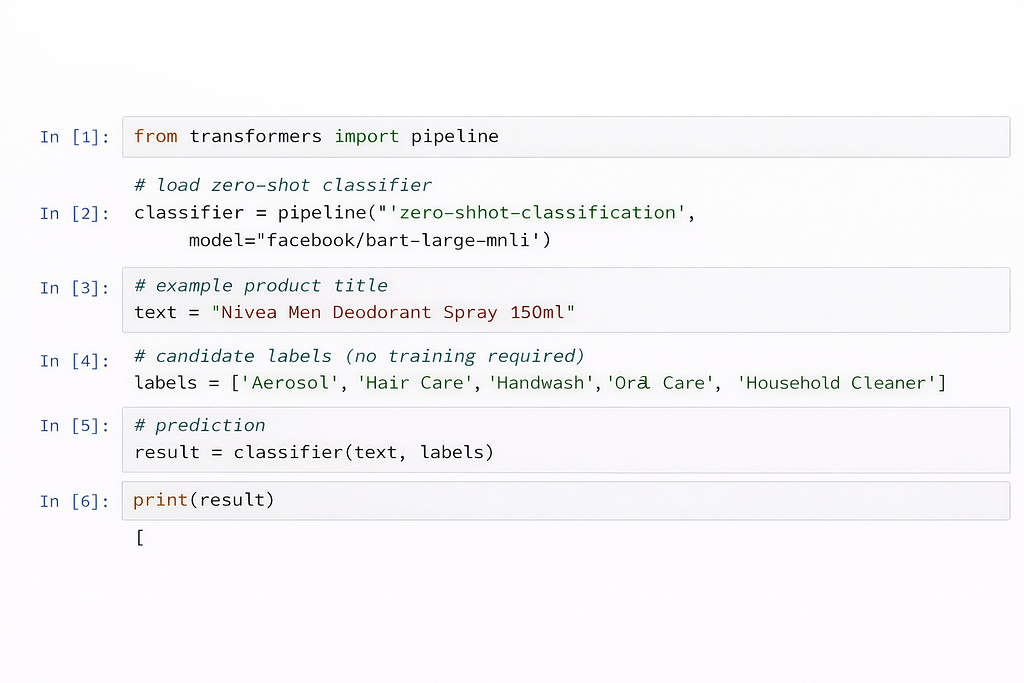
What is zero shot transfer learning algorithm? Could you share code for the same?
Zero-shot learning (ZSL) is a technique where a model can predict classes it has never seen during training. The ZSL algorithm flow would be
a) encoding text to vector
b) encoding labels to vector
c) Computing cosine similarity
sim = (A · B) / (||A|| ||B||)
d) Choosing max similarity and calculating confidenc.
Instead of learning from labeled examples of every class, the model:
- Learns general language or visual representations from large pre-training.
- Uses semantic descriptions or labels at inference time.
- Chooses the label that is most semantically similar to the input.
What is the range you decide for to filter out confidence interval derived from zero shot transfer learning and how did you decide on this range?
- Analyze score distribution first → choose an initial threshold based on where high-confidence and ambiguous zero-shot scores naturally separate in validation data.

- Calibrate with labeled ground truth → pick the cutoff that achieves required precision (e.g., ≥90%) rather than trusting raw model confidence.
- Use tiered bands instead of one threshold → e.g., ≥0.85 auto-accept, 0.60–0.85 review/rules, <0.60 reject or manual label.
Why did you use TF-IDF algorithm?
- Zero-shot gives broad semantic prediction; TF-IDF refines with exact keywords → Zero-shot understands meaning (“deodorant → aerosol”), while TF-IDF captures specific discriminative terms in your catalog vocabulary to improve precision.
- Acts as a precision-boosting secondary filter → After zero-shot proposes top categories, TF-IDF similarity or classifier helps resolve close/conflicting classes and reduce false positives.
- More stable for domain-specific terminology → Zero-shot models are general-purpose, but TF-IDF is trained on your product catalog text, so it adapts better to brand names, abbreviations, and local wording.
- Computationally cheaper for re-ranking at scale → Running transformers on millions of items is expensive; TF-IDF enables fast scoring/re-ranking once zero-shot narrows candidate categories.
- Improves explainability in audit pipelines → TF-IDF shows which keywords drove the final decision, making the hybrid system easier to justify to business or compliance teams.

How did you decide on XG Boost parameters?

Why did you use K-Fold cross validation for this model?
How did you evaluate model performance?
We evaluated the performance of the classification algorithm using confusion matrix. We concluded the model is doing good in all True Positive and True Negative categories, also the model was doing comparable for False Positive(less False Positive).

What are SHAP values?
SHAP values use game-theoretic Shapley principles to fairly quantify each feature’s contribution to an individual machine learning prediction while also enabling global model interpretability.
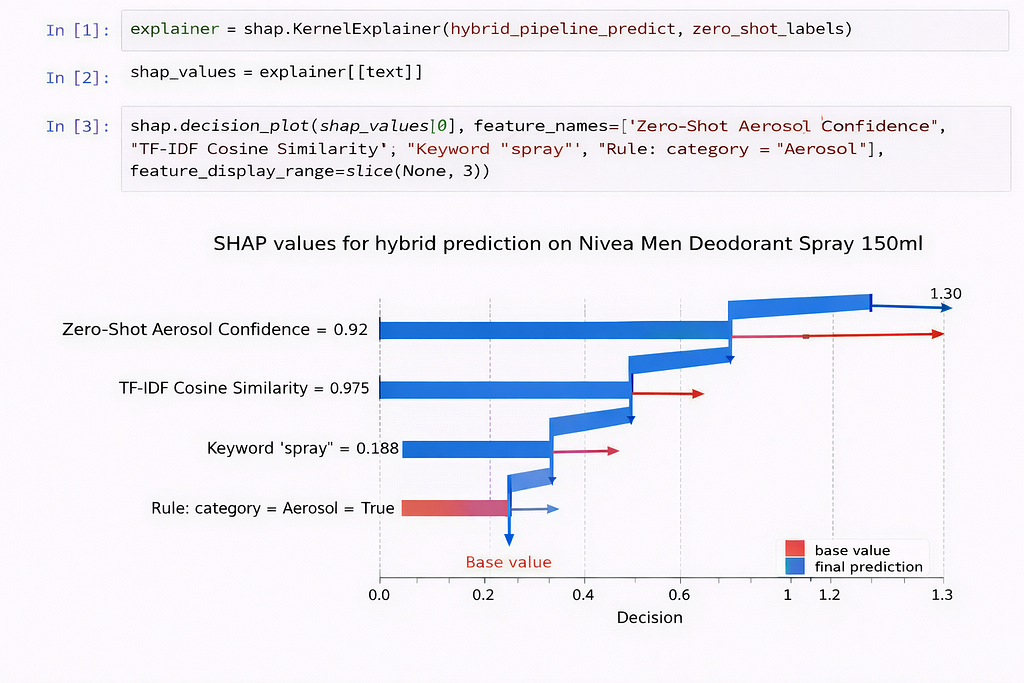
Why did we use SHAP Values?
- Model explainability at prediction level → SHAP shows how each feature contributed to a specific prediction, which is critical when combining zero-shot, TF-IDF, and rules in a hybrid pipeline.
- Builds trust with business and audit teams → Instead of a black-box ML decision, SHAP provides human-interpretable reasoning (e.g., keyword “spray” pushed category toward Aerosol).
- Helps debug model errors and bias → By inspecting SHAP contributions, we can detect spurious correlations, missing features, or rule conflicts, improving model quality.
- Supports feature importance and model validation → Aggregated SHAP values reveal which signals (semantic score, keyword weight, rules) truly drive predictions, ensuring the system behaves logically.
- Enables production monitoring and governance → SHAP explanations can be logged to track decision drift, compliance requirements, and explainability standards, which is important in enterprise ML systems.
Where did you harness the end output?
- Final predictions stored in analytics layer → After zero-shot, TF-IDF, rules, and confidence calibration, the final category, confidence score, and SHAP explanations were written to a data warehouse (e.g., S3/Redshift/BigQuery).
- Connected to BI visualization tool → This curated dataset was then integrated with Amazon QuickSight to enable business-friendly monitoring and exploration.
- Dashboard tracked key quality metrics → Included category distribution, low-confidence items, rule overrides, and model drift indicators, helping stakeholders quickly assess catalog health.
- Enabled audit and explainability views → Users could drill down to individual product predictions with SHAP feature contributions, ensuring transparency for compliance and operations teams.
- Supported continuous improvement loop → Insights from the dashboard guided manual review, rule tuning, and retraining data selection, closing the feedback loop for production ML governance.
How did you decide to improve upon the model?
- Focused on data quality before model complexity → We improved labeling consistency, added missing edge-case categories, and expanded domain-specific training samples, since better data typically gives the largest accuracy gain.
- Targeted reduction of false negatives → Error analysis showed true items being missed by the model, so we rebalanced classes, tuned thresholds, and added rule/keyword signals to improve recall for critical categories.
- Used automated ML for stronger baselines → We leveraged AutoGluon to run model ensembling, feature engineering, and hyperparameter tuning automatically, which improved performance beyond manual models.
Catalog Audit Pipeline Using XGBoost was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.