: How Tiny Networks With Recursion Beat Large Models on Hard Puzzles")
Tiny Recursion Models (TRM): How Tiny Networks With Recursion Beat Large Models on Hard Puzzles

Paper-explained series 7
TL;DR
The Tiny Recursive Model (TRM) challenges the “bigger is better” dogma by outperforming massive Large Language Models (LLMs) on complex reasoning benchmarks using a fraction of the parameters. By simplifying the Hierarchical Reasoning Model (HRM), TRM utilizes a single “tiny” network (just 2 layers, ~5–7M parameters) that recurses on a latent reasoning state (z) — an internal “scratchpad” that tracks the logical chain-of-thought distinct from the evolving answer (y). This approach achieves state-of-the-art generalization on Sudoku-Extreme (87.4%), Maze-Hard (85.3%), and ARC-AGI tasks, proving that deep supervision and recursion can emulate massive effective depth without the massive parameter count.
Introduction
While Large Language Models (LLMs) display impressive capabilities, they often struggle with hard, logical puzzle tasks due to the brittleness of auto-regressive generation. A single incorrect token in a chain can derail the entire solution, a failure mode often mitigated — but not solved — by expensive Chain-of-Thought (CoT) prompting.
To address this, researchers have proposed that small networks using recursion and deep supervision can emulate the “effective depth” of much larger models. The Hierarchical Reasoning Model (HRM) was a pioneer in this space, but it relied on complex biological justifications and separate networks for different frequencies.
So, the Tiny Recursive Model (TRM). TRM simplifies the architecture significantly by using a single tiny network (often just 2 layers) and back-propagating through the full recursion process rather than relying on approximations. Despite having less than 0.01% of the parameters of models like Deepseek R1 or Gemini 2.5 Pro, TRM achieves significantly higher accuracy on rigorous benchmarks. For instance, on the Sudoku-Extreme dataset, TRM achieves 87.4% accuracy compared to HRM’s 55% and the near-zero performance of many standard LLMs.
Why Reasoning is Hard for Autoregressive LLMs
LLMs generate answers token-by-token. In logic puzzles like Sudoku or Mazes, this is high-risk: one wrong digit or direction renders the final answer invalid. While methods like Chain-of-Thought (CoT) attempt to emulate reasoning by generating intermediate steps, they are computationally expensive, require high-quality reasoning data, and remain brittle if the generated reasoning trace contains errors.
The Hierarchical Reasoning Model (HRM)
The precursor to TRM, the Hierarchical Reasoning Model (HRM), introduced the concept of using two small neural networks recursing at different frequencies:
- fL (Low-level): Updates high-frequency latent features.
- fH (High-level): Updates low-frequency latent features.
HRM employs deep supervision, where the model attempts to improve its answer over Nsup=16 steps, reusing latent features from previous steps as initialization. To manage computational costs, HRM uses Adaptive Computational Time (ACT) to halt processing early for easy examples.
However, HRM relies on the Implicit Function Theorem (IFT) and a 1-step gradient approximation to justify only back-propagating through the last few steps of recursion, assuming the model reaches a fixed point.
To learn about HRMs: https://pub.towardsai.net/hierarchical-reasoning-models-when-27m-parameters-outperform-chain-of-thought-5c2f46cd0467
Empirical Gaps & Design Targets
The authors of TRM identified three key weaknesses in HRM that motivated their new architecture:
- Questionable IFT usage: HRM assumes latent features converge to a fixed point to justify its gradient approximation. Empirical analysis shows residuals often remain high, suggesting no fixed point is actually reached.
- Inefficient ACT: The halting mechanism in HRM requires a “continue loss” that demands an extra forward pass, slowing down training.
- Unnecessary Complexity: HRM uses complex biological arguments to justify its two-network, hierarchical structure, which may not be necessary for artificial neural networks.
TRM at a Glance
The intuition behind TRM is simple: instead of complex hierarchies, the model maintains a current answer (y) and a latent “chain-of-thought” (z). It recursively refines the reasoning z and then updates the answer y based on the improved reasoning.
Key Differences vs. HRM:
- Single Network: TRM merges the low-level and high-level networks into one, halving the parameter count.
- Full Recursion: Instead of approximating gradients, TRM back-propagates through the entire recursion chain (typically n=6 steps), removing the need for fixed-point assumptions.
- Tiny Architecture: TRM finds that a 2-layer network generalizes better than deeper ones for these tasks, likely due to reduced overfitting on small datasets.
- Flexible Core: It can swap Self-Attention for MLPs (similar to MLP-Mixer) for tasks with small, fixed contexts like Sudoku.
Method
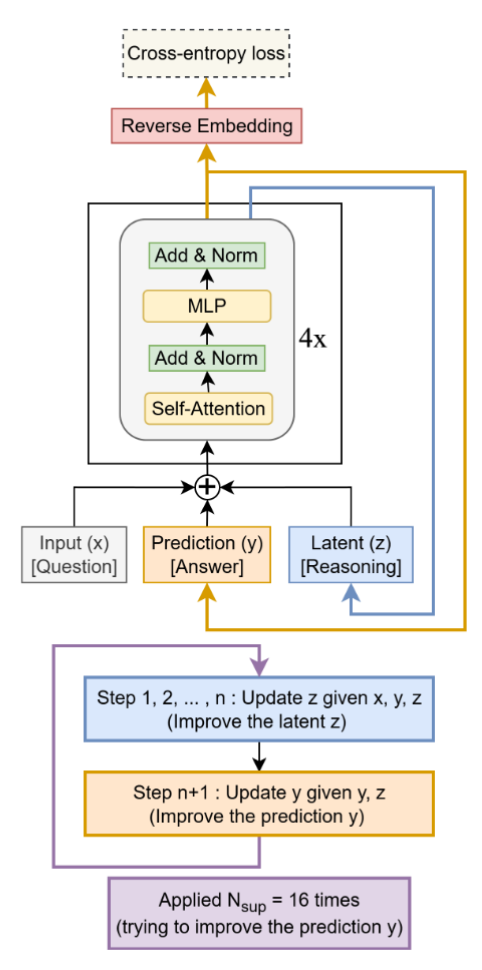
Notation & Setup
The model operates on an input x and produces an output prediction y.
- x: Input question embedding.
- y: Current predicted answer (initialized, then refined).
- z: Latent reasoning feature.
All 3 tensors generally have shape [B,L,D], where B is batch size, L is sequence length, and D is embedding dimension.
The Algorithm: “Think n Times, Write Once”
TRM employs a recursive process where the network refines its state multiple times before outputting a prediction. Unlike Chain-of-Thought, it does not append tokens; it updates the vectors in place.
The logic follows a strict “Think, then Write” cadence :
- Latent Recursion: It runs n steps (e.g., 6) where it updates only the reasoning state (z). It uses the current answer (y) as context but does not modify it yet. Only after the n thoughts are finished does it update the answer (y) once.
def latent_recursion(x, y, z, n=6):
for i in range(n): # latent reasoning
z = net(x, y, z) # Update ONLY reasoning state
y = net(y, z) # refine output answer ONCE
return y, z
- Deep Recursion: This middle loop stacks the thinking units to build “effective depth” without using extra memory. It runs the thinking/writing unit T−1 times (e.g., 2 times) without calculating gradients (torch.no_grad) . Then, it runs the process one final time with gradients enabled so the model can learn from its mistakes.
def deep_recursion(x, y, z, n=6, T=3):
# recursing T-1 times to improve y and z (no gradients needed)
with torch.no_grad():
for j in range(T-1):
y, z = latent_recursion(x, y, z, n)
# recursing once to improve y and z with gradients
y, z = latent_recursion(x, y, z, n)
return (y.detach(), z.detach()), output_head(y), Q_head(y)
- Grading Phase (Deep Supervision): This entire block is repeated Nsup times (e.g., 16 times). During training, the model calculates the error on y at every single one of these steps, forcing it to learn how to produce a valid answer as early as possible .
# Main Deep Supervision Training Loop
for x_input, y_true in train_dataloader:
y, z = y_init, z_init
for step in range(N_supervision):
x = input_embedding(x_input)
(y, z), y_hat, q_hat = deep_recursion(x, y, z)
# Grading Phase
loss = softmax_cross_entropy(y_hat, y_true)
loss += binary_cross_entropy(q_hat, (y_hat == y_true))
loss.backward()
opt.step()
opt.zero_grad()
if q_hat > 0: # early-stopping
break
During testing, the model no longer has access to ground truth; instead, it repeatedly applies the same learned recursive refinement function to progressively improve its current prediction. Because deep supervision trained it to move closer to the correct solution at every step, inference becomes an iterative self-correction process that converges toward a valid answer without external feedback.
To understand how TRM processes information, compare it to how a human solves a difficult Sudoku puzzle. You rarely write a number into a cell immediately. Instead, you engage in a hidden mental process: “If I place a 5 here, then the 3 must go there, but that conflicts with the top row…”
TRM mimics this dual process by explicitly separating the Answer State (y) from the Reasoning State (z):
- The Answer State (y) corresponds to the physical Sudoku grid. It is the “visible” solution — the numbers written in the boxes. At the start, this grid may be empty or contain tentative, incorrect guesses. By the end, it must be the perfect solution.
- The Reasoning State (z) acts as the “mental scratchpad.” Unlike the grid, this state is invisible to the observer. It is a high-dimensional vector that holds the intermediate logic, constraints, and “what-if” scenarios. If you were to visualize z, it would look like abstract noise rather than numbers, because it encodes the logical relationships required to solve the puzzle, not the solution itself.
Architectural Choices
1. The Goldilocks Depth: Why 2 Layers Beats 4
In deep learning, the standard assumption is that deeper networks are smarter. TRM proves the opposite for reasoning tasks on small datasets: a “dumber” network that thinks longer actually performs better.
- The Trap of “Big Brains”: When training on scarce data like Sudoku-Extreme (only 1,000 examples), a larger network (even just 4 layers) has enough capacity to “memorize” the training puzzles instead of learning the logic . This leads to overfitting, where the model fails on new puzzles it hasn’t seen before, dropping accuracy to 79.5%.
- The “Tiny” Advantage: A 2-layer network is too small to memorize the answers. It is effectively forced to learn the general rules of Sudoku to solve the problem at all.
- Scaling Thought, Not Size: To compensate for its lack of physical depth, TRM increases its “thinking time” (recursion steps, n=6). This allows a tiny 2-layer model to emulate the reasoning power of a massive 42-layer network without the parameter bloat, boosting generalization to 87.4%.
2. Hard-Wiring vs. Scanning: Why MLP beats Attention on Sudoku
In modern AI, Self-Attention is the gold standard because it allows a model to “scan” a sequence and dynamically decide which parts are important. However, TRM reveals that for puzzles like Sudoku, this flexibility is actually a weakness.
- The Logic (L≪D): A Sudoku grid always has 81 cells (L=81). This is much smaller than the model’s internal embedding size (D=512) .
- The Switch: Instead of using Self-Attention to constantly rediscover that “cell 1 is in the same row as cell 2,” TRM replaces it with a Multi-Layer Perceptron (MLP) that mixes information across the sequence.
- The Result: This effectively “hard-wires” the grid structure into the model. Since the rules of Sudoku geometry never change, the model doesn’t need to look around; it just needs to process. This change alone boosted accuracy from 74.7% to 87.4% on Sudoku-Extreme.
- Note: This trick has a limit. On larger, variable tasks like Mazes (where the grid is 30×30, or 900 tokens), the “hard-wired” MLP approach fails, and the dynamic “scanning” of Self-Attention becomes superior again.
3. The Context Switch: One Network to Rule Them All
Previous models (like HRM) used two separate neural networks — one specialized for “thinking” and another for “answering.” TRM combines them into a single tiny network, halving the parameter count while surprisingly improving performance.
- How it works: The model uses the inputs themselves as the instruction for what to do.
- “Thinking Mode”: When the model sees the Question (x) combined with the Answer (y) and Reasoning (z), it knows to analyze the logic. It outputs a new Reasoning state (z).
- “Writing Mode”: When the input x is removed, leaving only the Answer (y) and Reasoning (z), the model switches gears. It uses its internal thoughts to update the visible solution (y).
- The Result: By forcing one network to handle both logic and writing, the model learns a more robust representation of the problem, improving generalization on Sudoku-Extreme from 82.4% to 87.4%.
Training Regime
- Deep Supervision: The model is trained to predict the correct output at every supervision step, not just the end.
- Exponential Moving Average (EMA): Instead of using the raw weights, TRM maintains a “shadow” copy of the weights that updates very slowly. It uses a decay rate of 0.999. This means the final model is effectively an average of the weights over the last several thousand steps, smoothing out the noise. This acts like a shock absorber. It prevents the model from memorizing specific puzzles too quickly and forces it to learn the general rules, boosting accuracy from 79.9% to 87.4%.
- Simplified ACT: The halting mechanism is trained using a simple Binary Cross Entropy loss on whether the answer is correct, removing the need for a second forward pass.
- Optimization: AdamW optimizer with cosine annealing and warm-up is used.
Datasets & Experimental Setup
The authors evaluated TRM on benchmarks designed to be easy for humans but hard for AI:
- Sudoku-Extreme: 9×9 grids. 1,000 training examples, tested on 423k examples. Heavily augmented with 1,000 valid shuffles per sample.
- Maze-Hard: 30×30 mazes with path lengths >110. Augmented with 8 dihedral transformations.
- ARC-AGI-1 & ARC-AGI-2: Geometric reasoning puzzles. Augmented 1,000 times (colors, rotations, flips). Test score is based on voting from augmentations.
Compute: Experiments were run on L40S and H100 GPUs, taking 24–72 hours depending on the dataset.
Results
TRM significantly outperforms HRM and massive LLMs on reasoning tasks, despite its tiny size.


(Note: TRM-MLP excels at small contexts like Sudoku but fails on larger grids like Mazes, where TRM-Att is required.)
Ablations
The authors conducted extensive ablations to justify their design choices
- Layer Count: Reducing from 4 layers to 2 layers increased accuracy from 79.5% to 87.4%, supporting the “less is more” hypothesis regarding overfitting.
- Single vs. Separate Nets: Merging fL and fH into one net improved accuracy from 82.4% to 87.4% while halving parameters.
- Recursion: Using full recursion backprop (TRM) vs. 1-step gradient (HRM style) improved accuracy from 56.5% to 87.4%.
Limits of TRM
While efficient, TRM has limitations. The need to back-propagate through the full recursion chain (n steps) increases memory usage linearly. If n is too large, training can hit Out Of Memory (OOM) errors. Additionally, the MLP variant is strictly limited to small, fixed contexts and fails on larger spatial tasks like Mazes.
Congratulations to Alexia Jolicoeur-Martineau and the team at Samsung SAIL Montréal on this remarkable achievement! Your work proves that elegant, efficient architectures can solve the industry’s toughest reasoning puzzles while bypassing the excessive compute and parameter bloat of modern frontier models. This “Less is More” approach is a massive step forward for sustainable and accessible AI.
Until next time folks…
El Psy Congroo

Tiny Recursion Models (TRM): How Tiny Networks With Recursion Beat Large Models on Hard Puzzles was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.