
How to Build Reliable Incremental Models in dbt for Large Datasets: Production Lessons at Scale

Why Incremental Models Become Critical at Scale
Large datasets change the economics and reliability profile of dbt transformations. Full-refresh models become slow, expensive and operationally risky at high data volumes. Incremental models are a primary strategy for keeping runtimes predictable at scale. Incremental design is not only a performance optimisation but a reliability requirement. Poor incremental logic can silently introduce duplicates, gaps and metric drift.
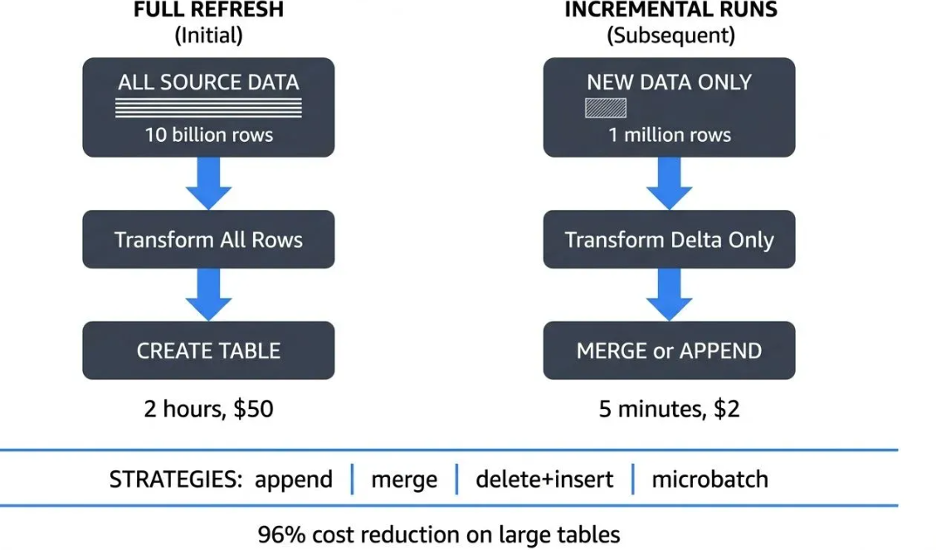
Figure 1: dbt Incremental Models
Many common dbt examples are not safe for large and fast-changing datasets. Reliable incremental models require deterministic keys and controlled load windows. They also require explicit handling of late-arriving and corrected records. Teams should treat incremental modelling as an engineering discipline, not a shortcut pattern. Standardised incremental design practices reduce incident risk across projects.
Enterprise Context and Data Scale Constraints
Reliable incremental models are most critical when working with multi-terabyte fact tables. Append-heavy event datasets grow quickly and stress full-refresh transformations. Many large datasets require daily or hourly incremental processing cycles. Downstream dashboards and reports often operate under strict delivery SLAs. Transformation runtimes must stay within fixed execution windows.

Figure 2: Enterprise data architecture
Compute resources on SQL warehouses or Spark clusters are budget constrained. Inefficient incremental logic can create disproportionate compute costs. Workloads often combine scheduled batch loads with near-real-time feeds. Mixed workload patterns increase the risk of overlap and duplicate processing. Predictable runtimes are treated as a non-negotiable design requirement. Controlled compute spend is a core acceptance criterion for incremental strategies. Outputs must remain reproducible even when incremental windows are adjusted.
Why Naïve Incremental Models Fail in Production
Many incremental model examples rely on simple timestamp filters for new data selection. Timestamp-only filters often miss late-arriving or corrected records. Late data creates silent gaps that are not detected by basic freshness checks. Unstable or non-unique keys frequently lead to duplicate rows in incremental tables. Derived keys based on mutable fields increase duplication risk. Schema drift can break incremental logic without obvious runtime errors. Column additions or type changes can invalidate merge conditions.
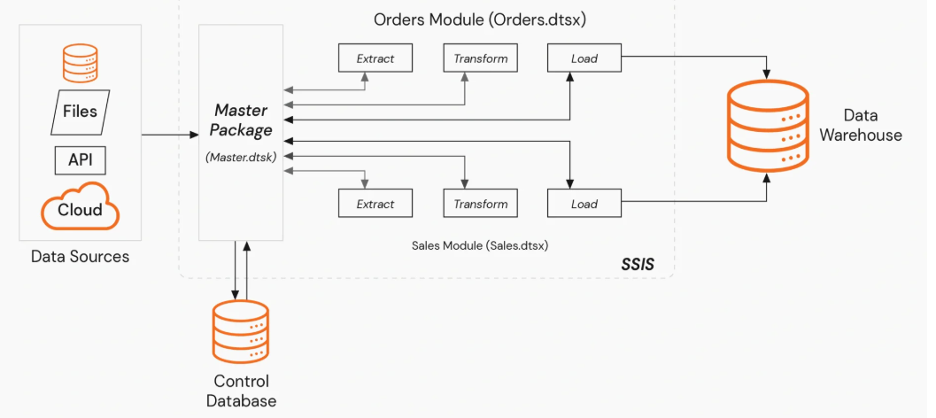
Figure 3: Modular data pipeline architecture
Uncontrolled backfills can overwrite or corrupt incremental history. Incremental logic often assumes consistent upstream record ordering. Out-of-order ingestion breaks these hidden assumptions. Most tutorials present simplified patterns that do not handle these edge cases. Production reliability requires defensive incremental design and explicit safeguards.
Design Principles for Reliable Incremental Models
Reliable incremental models start with deterministic and stable unique keys. Convenience keys derived from mutable fields should be avoided. Unique keys must remain consistent across re-runs and source corrections. Transformation logic should be idempotent under repeated execution. Re-running the same incremental window should not change correct results. Late-arriving records must be handled through defined lookback windows. Incremental filters should include controlled reprocessing ranges.
Partition-aware filtering improves both performance and correctness. Partition boundaries should align with event time or load time semantics. Cutoff windows should be explicit rather than based on latest timestamp only. Sliding windows reduce the risk of missing delayed records.
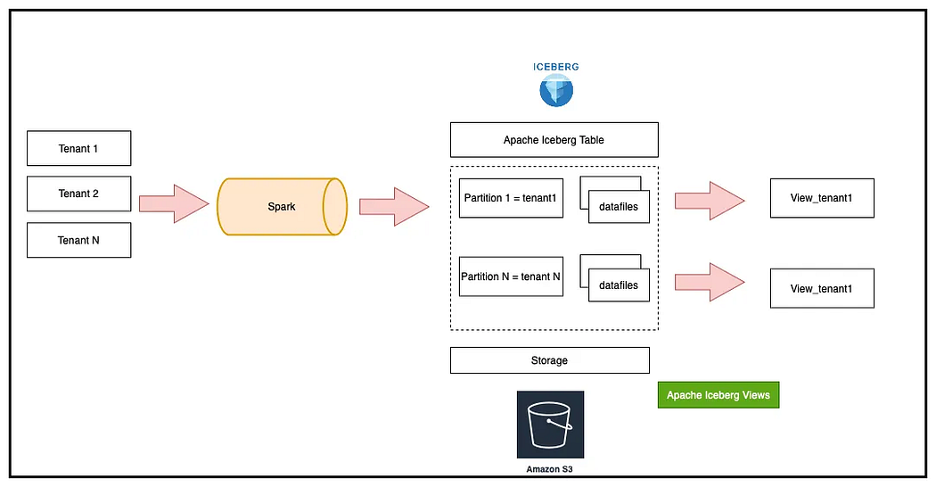
Figure 4: Partition-aware compaction
Backfills should run through controlled and tested rebuild paths. Safe backfill patterns prevent corruption of incremental history. These principles reduce silent data corruption in large datasets. They improve repeatability across runs and environments. Also they lower incident rates and recovery effort in production systems.
Performance and Cost Trade-offs at Large Data Volumes
Partition pruning is essential for keeping incremental queries efficient at scale. Tables should be partitioned on frequently filtered time or event columns. Clustering improves merge and lookup performance on large incremental tables. Poor partition choices can negate the benefits of incremental processing. Incremental window size directly affects both runtime and compute cost. Small windows reduce cost but increase the risk of missing late records. Larger windows improve correctness but increase scan volume.
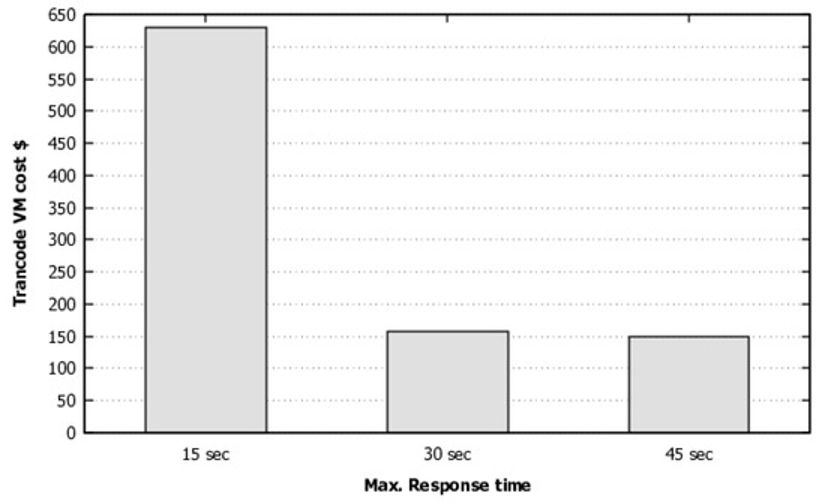
Figure 5: SLA Cost
Merge strategies provide correctness but are more compute intensive. Insert-only strategies are cheaper but require stronger deduplication logic. Warehouse engines and Spark engines optimise incremental workloads differently. Execution engine choice should match data shape and query pattern. Incremental models can become slower than rebuilds when change volume is high. Freshness targets must be balanced against compute spend. Incremental strategy should be selected based on workload behaviour and not defaults.
Testing, Monitoring and Failure Recovery
dbt tests should be treated as enforcement controls but not passive documentation. Test failures should block promotion of incremental models to production. Uniqueness and not-null tests are minimum requirements for incremental tables. Row-count anomaly checks help detect incomplete incremental loads. Freshness checks identify delayed or stalled upstream data feeds. Automated alerts should trigger when incremental drift is detected. Monitoring should compare incremental output against expected change patterns. Table versioning or time travel enables safe rollback after faulty runs. Recovery procedures should be predefined and documented in runbooks. Runbook-driven recovery reduces error during production incidents.
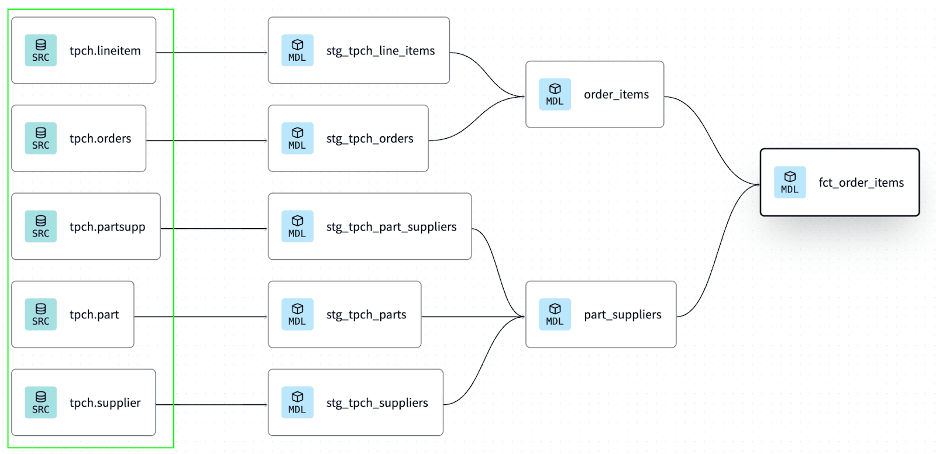
Figure 6: Managing data sources properly
Organisational Impact and Team Enablement
Shared incremental modelling standards improve consistency across dbt projects. Standard patterns reduce variation in incremental logic design. Reusable templates accelerate safe model development. Guardrails prevent common incremental failure modes at scale. Code review checklists make incremental risks visible during peer review. Review criteria include keys, windows and late-data handling. Standard practices reduce incident frequency across teams. Troubleshooting effort decreases with consistent model structure. Analytics engineers onboard faster with approved incremental templates. Team capability improves through shared incremental design guidance.
Conclusion: Incremental Models Are Reliability Engineering
Incremental models are more than performance optimisations; they ensure data reliability. Usually they act as both reliability and cost-control mechanisms in large datasets. Success requires disciplined design and rigorous testing and strong governance as well. Incremental logic should be treated as critical production infrastructure, not optional code. Defensive design protects against late-arriving data, duplicates and schema drift. Standardisation and team-wide guardrails amplify reliability benefits. Investing in incremental discipline reduces incidents and operational overhead. Treating incremental models strategically positions them as core enterprise engineering assets.
References
Stéphane D., 2026. dbt Incremental Models: Efficient Transformations. https://www.conduktor.io/glossary/dbt-incremental-models-efficient-transformations
Howard, 2025. What is Enterprise Data Architecture and Why It Matters. https://www.fanruan.com/en/blog/what-is-enterprise-data-architecture-and-why-it-matters.
Jigar M., 2025. How To Design a Data Pipeline Architecture in Python For Best System Performance? https://www.aqedigital.com/blog/data-pipeline-architecture/
Soumil S., 2025. Safe Strategy for Multi-Tenant Data Lakes with Apache Iceberg #2. https://aws.plainenglish.io/partition-aware-compaction-a-fail-safe-strategy-for-multi-tenant-data-lakes-with-apache-iceberg-2-255f0428249d
Fé, I., Matos, R., Dantas, J., Melo, C., Nguyen, T.A., Min, D., Choi, E., Silva, F.A. and Maciel, P.R.M., 2022. Performance-cost trade-off in auto-scaling mechanisms for cloud computing. Sensors, 22(3), p.1221. https://doi.org/10.3390/s22031221
Matt W., 2025. Building a data quality framework with dbt and dbt Cloud. https://www.getdbt.com/blog/building-a-data-quality-framework-with-dbt-and-dbt-cloud
Follow me on LinkedIn:
How to Build Reliable Incremental Models in dbt for Large Datasets: Production Lessons at Scale was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.