While large language models and other foundation models are well represented, traditional Amazon interests such as bandit problems and new topics such as AI for automated reasoning also get their due.
The 2024 Conference on Neural Information Processing Systems (NeurIPS) the premier conference in the field of AI begins today, and the Amazon papers accepted there display the breadth of the companys AI research.
Large language models (LLMs) and other foundation models have dominated the field for the past few years, and Amazons papers reflect that trend, covering topics such as retrieval-augmented generation, the use of LLMs for code generation, commonsense reasoning, and multimodal models. Training methodology also emerges as an area of focus, with papers on memory-efficient training, reinforcement learning with human feedback, classification with rejection, and convergence rates in transformer models.
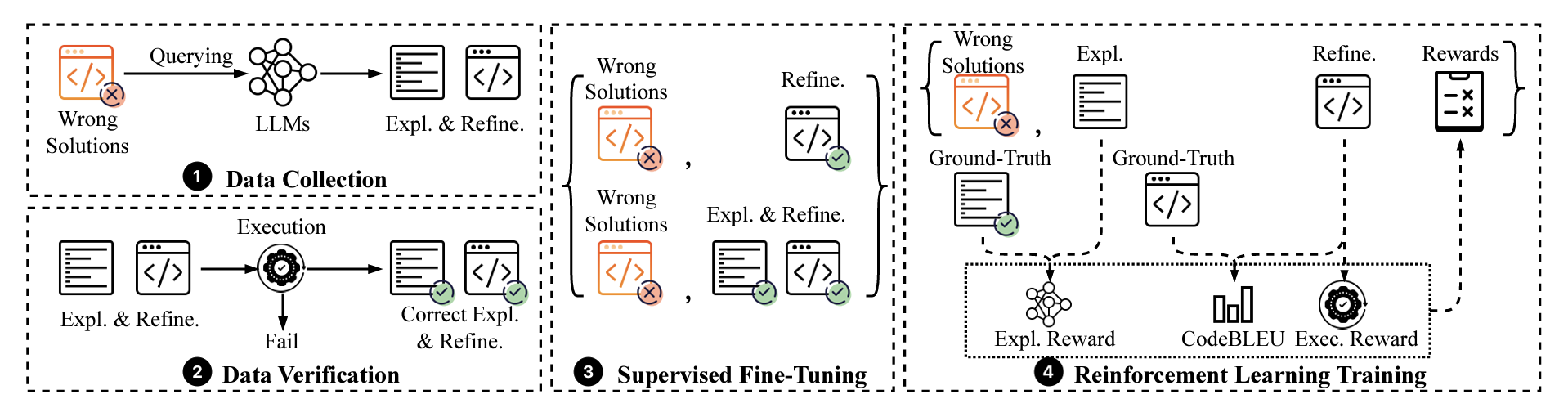
The data collection and model-training framework proposed in “<a href=”https://www.amazon.science/publications/training-llms-to-better-self-debug-and-explain-code” data-cms-id=”00000192-fd24-d1ad-a9f2-fded30910000″ data-cms-href=”https://www.amazon.science/publications/training-llms-to-better-self-debug-and-explain-code” link-data=”{"cms.site.owner":{"_ref":"0000016e-17e7-d263-a5fe-fff724f30000","_type":"ae3387cc-b875-31b7-b82d-63fd8d758c20"},"cms.content.publishDate":1733775131704,"cms.content.publishUser":{"_ref":"0000017f-b709-d2ad-a97f-f7fd25e30000","_type":"6aa69ae1-35be-30dc-87e9-410da9e1cdcc"},"cms.content.updateDate":1733775131704,"cms.content.updateUser":{"_ref":"0000017f-b709-d2ad-a97f-f7fd25e30000","_type":"6aa69ae1-35be-30dc-87e9-410da9e1cdcc"},"rekognitionVideo.timeFrameMetadata":[],"link":{"rekognitionVideo.timeFrameMetadata":[],"attributes":[],"item":{"_ref":"00000192-fd24-d1ad-a9f2-fded30910000","_type":"91d74bfc-4a20-30f0-8926-e52f02f15c04"},"_id":"00000193-ad0c-db73-adf3-ff1df3cc0001","_type":"c3f0009d-3dd9-3762-acac-88c3a292c6b2"},"linkText":"Training LLMs to better self-debug and explain code","theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs.enhancementAlignment":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs.overlayText":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs._template":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs.enhancementAlignment":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs.overlayText":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs._template":null,"_id":"00000193-ad0c-db73-adf3-ff1df3cc0000","_type":"809caec9-30e2-3666-8b71-b32ddbffc288"}”>Training LLMs to better self-debug and explain code</a>”.
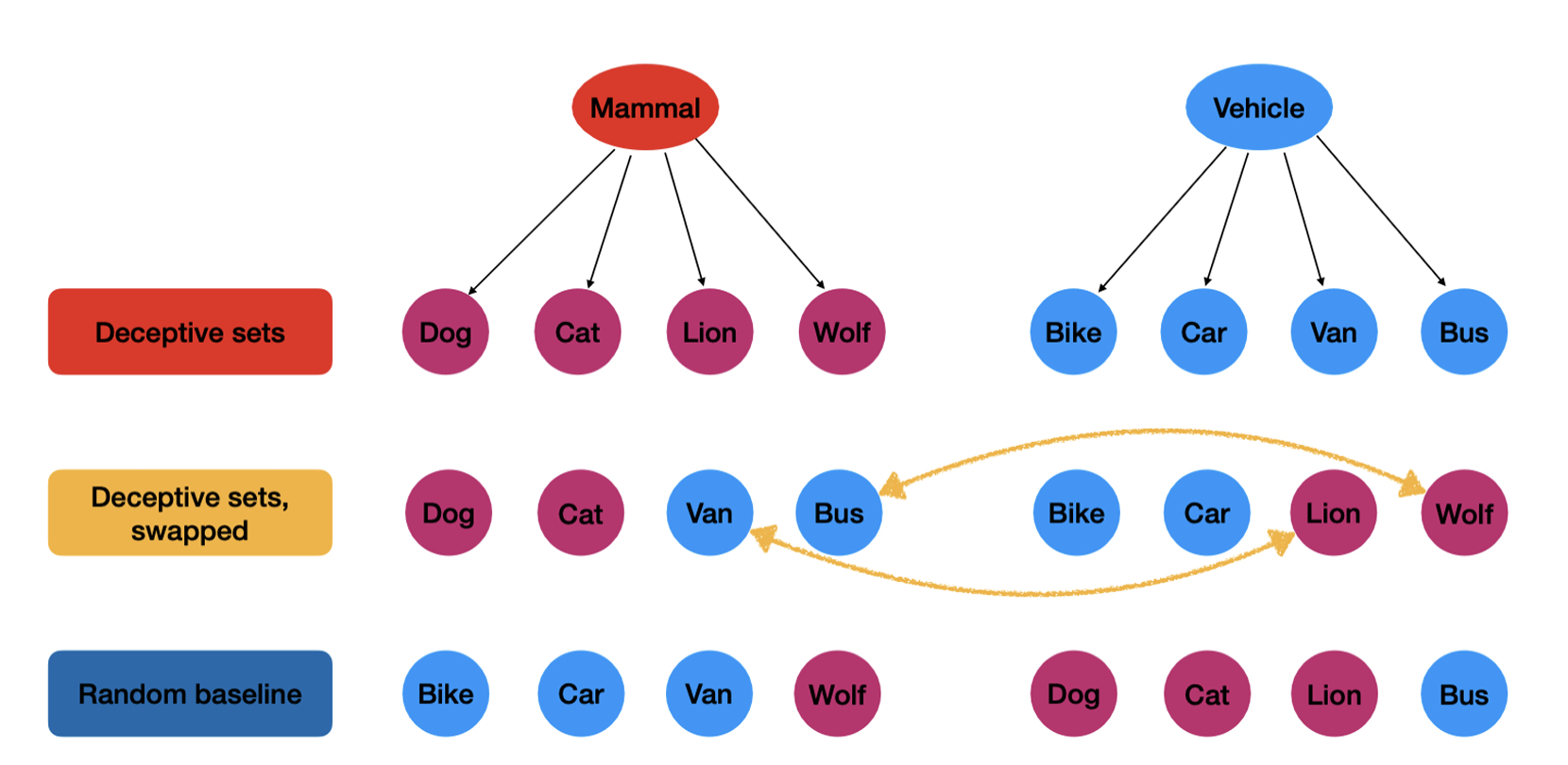
To evaluate LLMs’ robustness to semantic variation in set members, Amazon researchers and their colleagues created deceptive sets by sampling pairs of hypernyms (e.g., mammal and vehicle) and, from them, extracting hyponyms under three different conditions: (1) with the hyponyms as sampled; (2) with half of the set members swapped; and (3) with random sampling. LLMs exhibit a unique failure mode under the second condition (swapped), and the mean and variance in accuracy of the first condition (not swapped) are better than in the random baseline. This figure can be found in “<a href=”https://www.amazon.science/publications/setlexsem-challenge-using-set-operations-to-evaluate-the-lexical-and-semantic-robustness-of-language-models” data-cms-id=”00000192-f929-d0ee-a7d3-f92bb9390000″ data-cms-href=”https://www.amazon.science/publications/setlexsem-challenge-using-set-operations-to-evaluate-the-lexical-and-semantic-robustness-of-language-models” link-data=”{"cms.site.owner":{"_ref":"0000016e-17e7-d263-a5fe-fff724f30000","_type":"ae3387cc-b875-31b7-b82d-63fd8d758c20"},"cms.content.publishDate":1733775295811,"cms.content.publishUser":{"_ref":"0000017f-b709-d2ad-a97f-f7fd25e30000","_type":"6aa69ae1-35be-30dc-87e9-410da9e1cdcc"},"cms.content.updateDate":1733775295811,"cms.content.updateUser":{"_ref":"0000017f-b709-d2ad-a97f-f7fd25e30000","_type":"6aa69ae1-35be-30dc-87e9-410da9e1cdcc"},"rekognitionVideo.timeFrameMetadata":[],"link":{"rekognitionVideo.timeFrameMetadata":[],"attributes":[],"item":{"_ref":"00000192-f929-d0ee-a7d3-f92bb9390000","_type":"91d74bfc-4a20-30f0-8926-e52f02f15c04"},"_id":"00000193-ad0f-db73-adf3-ff1f72de0001","_type":"c3f0009d-3dd9-3762-acac-88c3a292c6b2"},"linkText":"SetLexSem Challenge: Using set operations to evaluate the lexical and semantic robustness of language models","theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs.enhancementAlignment":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs.overlayText":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs._template":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs.enhancementAlignment":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs.overlayText":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs._template":null,"_id":"00000193-ad0f-db73-adf3-ff1f72de0000","_type":"809caec9-30e2-3666-8b71-b32ddbffc288"}”>SetLexSem Challenge: Using set operations to evaluate the lexical and semantic robustness of language models</a>”.
Yen-Ju Lu, Jing Liu, Thomas Thebaud, Laureano Moro-Velazquez, Ariya Rastrow, Najim Dehak, Jesus Villalba
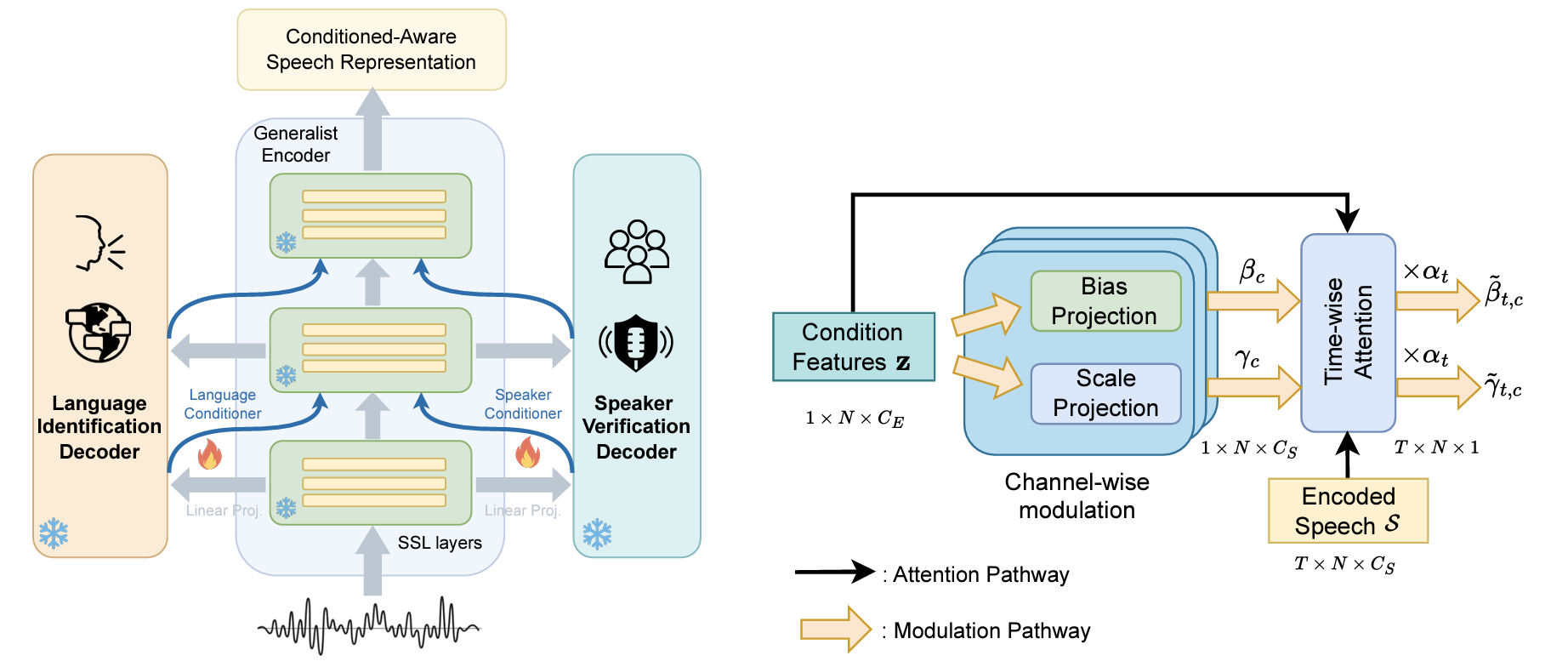
The CA-SSLR scheme and its time-channel attention conditioner, as proposed in “<a href=”https://www.amazon.science/publications/ca-sslr-condition-aware-self-supervised-learning-representation-for-generalized-speech-processing” data-cms-id=”00000192-f91b-d0ee-a7d3-f91b3aa10000″ data-cms-href=”https://www.amazon.science/publications/ca-sslr-condition-aware-self-supervised-learning-representation-for-generalized-speech-processing” link-data=”{"cms.site.owner":{"_ref":"0000016e-17e7-d263-a5fe-fff724f30000","_type":"ae3387cc-b875-31b7-b82d-63fd8d758c20"},"cms.content.publishDate":1733775862919,"cms.content.publishUser":{"_ref":"0000017f-b709-d2ad-a97f-f7fd25e30000","_type":"6aa69ae1-35be-30dc-87e9-410da9e1cdcc"},"cms.content.updateDate":1733775862919,"cms.content.updateUser":{"_ref":"0000017f-b709-d2ad-a97f-f7fd25e30000","_type":"6aa69ae1-35be-30dc-87e9-410da9e1cdcc"},"rekognitionVideo.timeFrameMetadata":[],"link":{"rekognitionVideo.timeFrameMetadata":[],"attributes":[],"item":{"_ref":"00000192-f91b-d0ee-a7d3-f91b3aa10000","_type":"91d74bfc-4a20-30f0-8926-e52f02f15c04"},"_id":"00000193-ad17-db73-adf3-ff17f8460001","_type":"c3f0009d-3dd9-3762-acac-88c3a292c6b2"},"linkText":"CA-SSLR: Condition-aware self-supervised learning representation for generalized speech processing","theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs.enhancementAlignment":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs.overlayText":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs._template":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs.enhancementAlignment":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs.overlayText":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs._template":null,"_id":"00000193-ad17-db73-adf3-ff17f8460000","_type":"809caec9-30e2-3666-8b71-b32ddbffc288"}”>CA-SSLR: Condition-aware self-supervised learning representation for generalized speech processing</a>”. Only the conditioner and linear projections for the decoders are trainable; all other parameters are frozen during adaptation. CA-SSLR improves SSL features by integrating intermediate LID/SV conditions, keeping pretrained parameters frozen <i>(left)</i>. The trainable time-channel attention conditioner integrates language and speaker prediction <i>(right)</i>.
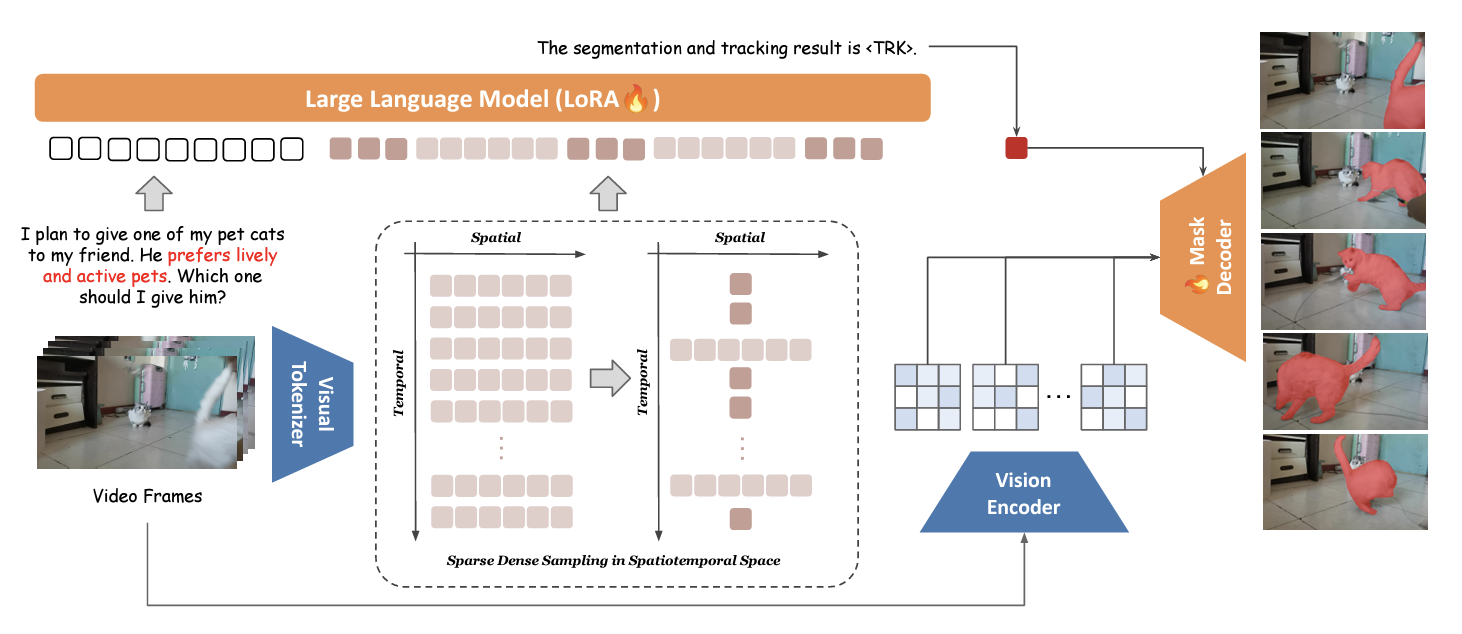
The video object segmentation framework proposed in “<a href=”https://www.amazon.science/publications/one-token-to-seg-them-all-language-instructed-reasoning-segmentation-in-videos” data-cms-id=”00000193-974d-d1ea-a597-976dbb0d0000″ data-cms-href=”https://www.amazon.science/publications/one-token-to-seg-them-all-language-instructed-reasoning-segmentation-in-videos” link-data=”{"cms.site.owner":{"_ref":"0000016e-17e7-d263-a5fe-fff724f30000","_type":"ae3387cc-b875-31b7-b82d-63fd8d758c20"},"cms.content.publishDate":1733778225820,"cms.content.publishUser":{"_ref":"0000017f-b709-d2ad-a97f-f7fd25e30000","_type":"6aa69ae1-35be-30dc-87e9-410da9e1cdcc"},"cms.content.updateDate":1733778225820,"cms.content.updateUser":{"_ref":"0000017f-b709-d2ad-a97f-f7fd25e30000","_type":"6aa69ae1-35be-30dc-87e9-410da9e1cdcc"},"rekognitionVideo.timeFrameMetadata":[],"link":{"rekognitionVideo.timeFrameMetadata":[],"attributes":[],"item":{"_ref":"00000193-974d-d1ea-a597-976dbb0d0000","_type":"91d74bfc-4a20-30f0-8926-e52f02f15c04"},"_id":"00000193-ad3c-db73-adf3-ff3d1b330001","_type":"c3f0009d-3dd9-3762-acac-88c3a292c6b2"},"linkText":"One token to seg them all: Language instructed reasoning segmentation in videos","theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs.enhancementAlignment":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs.overlayText":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs._template":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs.enhancementAlignment":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs.overlayText":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs._template":null,"_id":"00000193-ad3c-db73-adf3-ff3d1b330000","_type":"809caec9-30e2-3666-8b71-b32ddbffc288"}”>One token to seg them all: Language instructed reasoning segmentation in videos</a>”.