
Crafting the Eyes for Thinking Machines: The “White Box” VLM

“In a voyage to build an open foundation for enthusiasts — to brainstorm and invent, rather than becoming sheep in the herd who call VLMs ‘expensive black boxes’ and settle for whatever crumbs enterprises toss over the wall.”
The Manifesto
- We reject the “Black Box.” We refuse to treat computer vision as a magic API call. We demand to see the gears turning.
- We build to understand. We are not chasing the highest benchmark score on day one; we are chasing the clearest understanding of how a machine aligns a pixel to a concept.
- We value Structure over Statistics. A model shouldn’t just guess that a “dog” is in the image because of texture; it should see the dog, identify its legs, and understand it is standing on the grass.
- We are Architects, not just Users. While the world waits for GPT-5, we are building the eyes that will let the next generation of models see.
Introduction: The Blind Gods of Silicon

We are living through a Cambrian Explosion of intelligence. Large Language Models (LLMs) have moved from research labs to daily utilities. Every hour seems to bring a new breakthrough, a new parameter count, and a new king of the leaderboard. These models can write poetry, refactor code, and pass professional exams. But for all their brilliance, they share a fatal flaw: They are blind.
They live in a void of text. They understand “sunset” only as a statistical probability of tokens appearing near “orange” and “horizon,” not as a visual reality. To bridge the gap to true Artificial General Intelligence (AGI), we don’t just need models that talk better; we need models that see.
This brings us to the Vision-Language Model (VLM). But before I tell you what I am building, I must clarify the murky waters of what a VLM actually is — and what it is not.
The Dreamers: Image Generators
First, there are the “Dreamers” (like Midjourney, Sora, or DALL-E). These are often confused with VLMs, but they are opposites. You give them text, and they hallucinate pixels. They focus on aesthetics, texture, and artistic style. They are creative, but they do not understand reality; they fabricate it.
The Translator: CLIP
Then, there is CLIP (Contrastive Language-Image Pre-training). In the open-source community, CLIP is often treated as the default “vision” tool. But CLIP is not a reasoning engine; it is a translator. It aligns images and text in a mathematical space, allowing a computer to say, “This image is 90% similar to the text ‘a dog’.” It is a retina without a brain. It can match patterns, but it cannot describe a scene or answer complex questions about it.
The Giants: Existing VLMs
Finally, we have the current crop of actual VLMs — models like BLIP, LLaVA, and Microsoft’s Phi-4 Vision. These do reason. They can look at an image and answer questions.
- BLIP was a pioneer in unifying understanding and generation.
- LLaVA popularized the “connector” approach: taking a frozen vision encoder (like CLIP) and gluing it to a frozen LLM (like Vicuna/Llama).
These models are impressive engineering feats. But to the average enthusiast or independent researcher, they remain “Black Boxes.” The architecture is either proprietary, or it is a complex “glue” job where the vision part is treated as a solved problem. We are told that it works, but rarely given the tools to fundamentally experiment with how it sees.
My Mission: The “White Box” Foundation
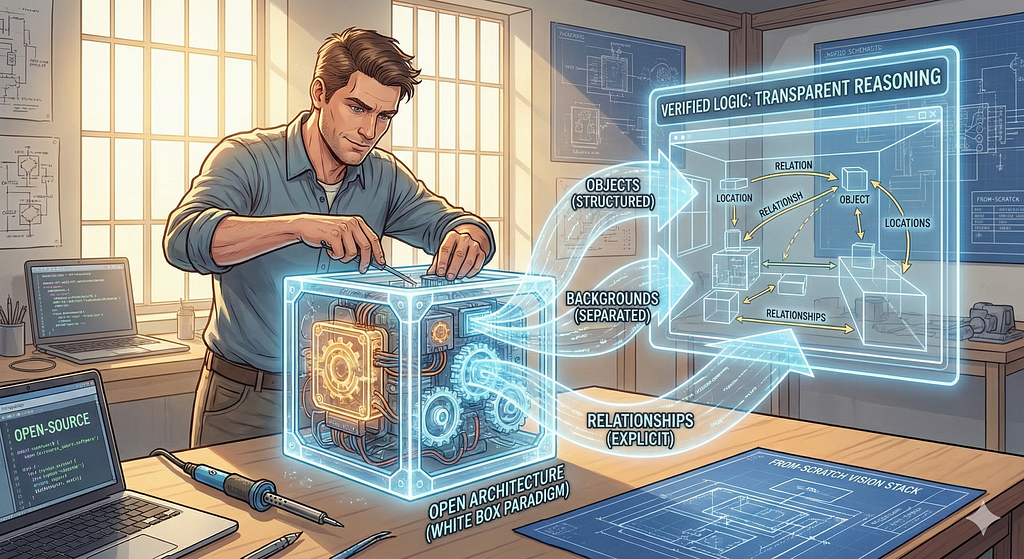
This series is my answer to that opacity. I am not claiming to invent the VLM; enterprises have already done that. I am setting out to democratize it.
I want to build an Open Architecture — a foundation that anyone can inspect, modify, and learn from. I call this the “White Box” Paradigm.
Instead of gluing pre-trained giants together and hoping for the best, I am building the vision stack from scratch. I want to move away from the “bag of patches” approach and move toward Structured Attention — an architecture that explicitly separates “Objects,” “Backgrounds,” and “Relationships.”
My goal is not to beat GPT-4V on a benchmark today. My goal is to provide a transparent, from-scratch implementation that proves we can build our own reasoning engines. I want to verify the logic of vision, not just the output.
This series will document that journey:
- The Intuition: Designing a novel architecture that mimics how humans break down a scene, trained on dense, structured data (Visual Genome) rather than simple captions.
- The Hybrid: Scaling up by plugging these custom, structured “eyes” into a powerful LLM to unlock complex reasoning.
- The Future: Moving toward a fully custom, end-to-end reasoning machine that removes the training wheels entirely.
I am stepping off the treadmill of rapid, shallow development to dig deep. I am crafting the eyes for the next generation of thinking machines.
The Blueprint: Seeing Before Thinking
So, how do we begin? To build a machine that can reason about the world (“Why is the man running?”), we must first build a machine that can accurately describe it (“A man is running on the track”).
We cannot run before we walk. Before I can plug my architecture into a massive LLM to handle complex logic, I need to verify that my “White Box” approach works at the fundamental level. I need to prove that splitting visual input into separate “Object” and “Scene” streams actually results in a model that can see.
Therefore, the first step of this journey is to build a Structured Captioning Model. This will be our unit test. If this model can describe an image using our novel architecture, we will have the green light to scale up to full reasoning. But to teach a model to see structure, we need the right textbook.
The Data Strategy: Teaching Structure, Not Just Speech.
If our goal is to build a “White Box” that understands the structure of a scene, we cannot use standard data. Most VLM tutorials rely on MS-COCO (Microsoft Common Objects in Context). While COCO is excellent for detecting objects, its captions are often flat and simplistic: “A dog on the grass.”
If I train on COCO, my model might learn to associate green pixels with the word “grass,” but it won’t necessarily understand the structure of the scene. It won’t explicitly learn that the Dog is the Subject, Standing On is the Relationship, and Grass is the Object. It learns probability, not geometry.
This is why I chose Visual Genome (VG).
Visual Genome is not just a collection of images; it is a massive database of Scene Graphs. It doesn’t just give you a sentence; it maps the reality of the image:
- Object: Dog
- Attribute: Brown
- Relationship: standing_on ->Grass
Why this matters for the White Box:
My architecture relies on Structured Cross-Attention. I intend to have one attention head looking exclusively at “Objects” and another looking at “Scene Context.” Visual Genome provides the ground truth to force this behavior. It allows me to physically feed the “Dog” bounding box into the Object Stream and the rest of the image into the Scene Stream. I cannot do that with COCO.
The price of this structure is chaos. Visual Genome is dense, messy, and huge. A single image might have 50 different regions described, overlapping boxes, and thousands of unique relationships. To keep this project feasible (and to save my sanity), I am using a pre-processed version of Visual Genome where regions and boxes are aligned. This allows me to focus entirely on the architecture — the logic of the eyes — rather than spending weeks writing data-cleaning scripts.
Taming the Chaos: The Preprocessing Logic
Choosing Visual Genome is one thing; actually feeding it into a neural network is another. The raw dataset is a sprawling web of JSON files, deeply nested dictionaries, and variable-length lists. If I tried to load this raw data during training, the TPU would starve to death waiting for the CPU to parse strings.
To solve this, I wrote a custom preprocessing pipeline that converts this chaos into a streamlined, binary format. Here are the three critical engineering decisions I made to prepare the data for our “White Box.”
1. The Atomic Unit: Regions, Not Images
In standard captioning (like COCO), the atomic unit of training is the Image. You feed the model a picture, and it learns the caption.
But Visual Genome is different. A single image might contain 50 distinct regions, each with its own description (e.g., “cat on the bed,” “lamp on the table,” “window in the back”).
If I simply treated the image as the sample, the model would be overwhelmed. So, I changed the atomic unit. In my preprocessing script, one training sample equals one region.
- Input: The full image + The specific bounding box of the region.
- Target: The description of that specific region.
This means a single image in my dataset spawns multiple training samples. This allows the model to learn fine-grained details. It learns that this specific patch of pixels corresponds to “lamp,” not just that the image generally contains furniture.
2. Preserving the “Context” (The 4D Arrays)
This is the most critical part of the “White Box” preparation. A standard VLM just looks at pixels. My VLM needs to look at Objects.
To support the StructuredCrossAttention mechanism I’ll build later, I need to feed the model more than just the image. I need to feed it the location of every other object in the scene so it understands context.
In the script, I extract and normalize these object coordinates:
# From CorrectedPreprocessor: Normalizing coordinates to 0-1 range
x1 = max(0, min(1, x / img_w))
y1 = max(0, min(1, y / img_h))
# ...
I then pack these into a dense tensor structure. For every single sample, I save:
- The Image: [3, 384, 384] (The visual pixels)
- The Region Box: [4] (The specific “where” we are describing)
- The Context Boxes: [50, 4] (The coordinates of up to 50 other objects in the room)
- The Mask: [50] (A boolean flag telling the model which boxes are real and which are padding)
This bbox_mask is essential. Since not every image has 50 objects, we pad the arrays with zeros. The mask ensures the attention mechanism ignores the empty space, keeping the “reasoning” clean.
3. The Artifact: PyTorch Shards for Speed
Finally, there is the storage format. Reading thousands of small JSON and JPG files is the enemy of high-performance computing. To minimize I/O latency, my script compiles everything into streamlined PyTorch (.pt) shard files.
# The efficient storage container
torch.save({
'images': images_tensor.half(), # float16 compression
'bboxes': bboxes_tensor.half(),
# ...
}, shard_path)
By compressing the data into float16 and storing it in binary shards, I reduce the file size significantly and ensure that when the “RAM Hack” (loading data into memory) happens later, it happens instantly.
We have now moved from abstract philosophy to a concrete, binary artifact. The data is structured, the objects are isolated, and the tensors are packed. The chaotic Visual Genome has been tamed.
Feeding the Beast (TPU v5e)
With the data strategy set, I had to face the hardware reality. I am not a research lab with an infinite budget; I am an enthusiast with a free Kaggle account.
This means my weapon of choice is the TPU v5e-8.
1. The Hardware Reality: A Ferrari on a Dirt Road
The TPU (Tensor Processing Unit) is an absolute beast for matrix multiplication. It uses XLA (Accelerated Linear Algebra) to compile your PyTorch code into a static computation graph, fusing operations and running them at blazing speeds. It offers 16GB of HBM (High Bandwidth Memory) per core, which is fantastic for large batches.
But the TPU has a fatal flaw: It hates waiting.
If the TPU has to wait for the CPU to load a file from the disk, or if it has to wait for Python to resize an image, the compute utilization drops to zero. Standard PyTorch DataLoader logic—reading images one by one from disk—is like driving a Ferrari on a dirt road. You spend more time waiting for data than actually training.
To make matters worse, XLA requires static shapes. If your batch size changes or your sequence length varies, the TPU triggers a “recompilation,” which stops everything for minutes.
I needed a data pipeline that was fast, static, and kept the TPU fed 100% of the time.
2. The Solution: The “RAM Hack” (VGPreloadedDataset)
This is where I leaned into the specific architecture of the Kaggle environment. While the TPU has limited HBM (16GB), the Host VM has a massive ~300GB of CPU RAM.
Most developers ignore this RAM, streaming data from the disk instead. I decided to abuse it.
Instead of reading files during training, I built a custom dataset class, VGPreloadedDataset, that acts as a RAM-resident cache. At the start of the session, I load every single preprocessed shard (.pt file) from the disk and concatenate them into massive, contiguous CPU tensors.
Here is the logic from my code:
# The "RAM Hack" in VGPreloadedDataset
class VGPreloadedDataset(Dataset):
def __init__(self, ...):
# 1. Load all .pt shards from disk lists
# 2. Concatenate them into massive contiguous CPU tensors
self.images = torch.cat(images_list, dim=0) # [Total_Samples, 3, 384, 384]
self.captions = torch.cat(captions_list, dim=0) # [Total_Samples, Seq_Len]
self.bboxes = torch.cat(bboxes_list, dim=0) # [Total_Samples, Max_Obj, 4]
By using torch.cat, I create a single block of memory.
- The Result: __getitem__ is no longer an I/O operation. It is a simple pointer offset. It becomes an O(1) memory lookup.
- The Payoff: The data pipeline is now instant. The TPU never starves. This simple “hack” transformed the training loop from an I/O-bound crawl to a compute-bound sprint.
3. The Collator: Handling 4D Structure
Standard text datasets are easy: you just pad sentences to the same length. But my “White Box” data is 4D. A single batch contains:
- Images: [Batch, 3, H, W]
- Objects: [Batch, Max_Objects, 4] (Bounding boxes)
- Masks: [Batch, Max_Objects] (Which boxes are real vs. padding)
If Image A has 5 objects and Image B has 50, standard collators choke. They can’t stack tensors of different sizes.
I wrote a custom VGCollator (Block 2) to act as the traffic controller. Since my preprocessing step already padded objects to a fixed size (e.g., 50), the collator’s job is to stack them efficiently and ensure the masks are correct.
# VGCollator: Stacking structural data
bbox_masks = torch.stack([sample["bbox_mask"] for sample in batch], dim=0)
bboxes = torch.stack([sample["bboxes"] for sample in batch], dim=0).float()
This bbox_mask is the secret sauce. Later, inside the model, my Structured Cross-Attention mechanism will use this boolean mask to mathematically “ignore” the padding, ensuring the model only attends to real objects, not empty zeros.
4. The Class Imbalance Solution
Finally, there was the issue of the data itself. Visual Genome is a “long-tail” dataset.
- Common concepts (e.g., “man,” “wearing,” “shirt”) appear millions of times.
- Rare concepts (e.g., “fedora,” “strumming,” “banjo”) appear only a few times.
If I trained with a standard Cross-Entropy loss, the model would become lazy. It would learn to just guess “man wearing shirt” for everything and achieve 90% accuracy while failing to actually see.
To fix this, I implemented a Class Weighting strategy in Block 1, based on the “Effective Number of Samples” paper.
# Block 1: Computing effective weights
effective_num = (1.0 - beta**count) / (1.0 - beta)
class_weights[token_id] = 1.0 / effective_num
Instead of weighting by simple frequency (which can be unstable), this formula (1 — beta^n) captures the diminishing returns of adding more samples for common classes. It punishes the model heavily for missing a rare word like “banjo,” but gives it little credit for correctly guessing “the.”
This forces the model to stop guessing and start looking.
The Foundation for “THE FOUNDATION” is Set.
We have now moved from abstract philosophy to concrete engineering.
I started this article with a manifesto: rejecting the “Black Box” and demanding a VLM that truly understands structure. I selected Visual Genome to provide that structure, and I engineered a RAM-resident pipeline to ensure my TPU never starves while processing it.
The data is loaded. The tensors are packed. The hardware is humming.
But we still have a critical problem: We don’t have a brain.
We have a massive amount of structured data — objects, coordinates, and relationships — streaming into our system at breakneck speed, but we have no neural network capable of consuming it. A standard Vision Transformer (ViT) would just mash all these carefully separated streams back into a single messy sequence, defeating the whole purpose.
We need something different. We need an encoder that respects boundaries — one that can look at an object, look at the background, and look at the scene context simultaneously but separately.
In the next article, I will unveil the ViTStructEncoder and the Structured Cross-Attention mechanism. We will stop prepping and start building the actual eyes of the machine.
See you in the next article.
Crafting the Eyes for Thinking Machines: The “White Box” VLM was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.