
The Hard Limit of Prompting — and Why AI Agents Need Tools
The Hard Limit of Prompting — and Why AI Agents Need Tools
Part 1 of a 3-part series on tools for agentic AI systems

People often believe that better prompts will eventually make AI agents reliable.
They won’t.
You can instruct a language model to “double-check its work,” “reason step by step,” or “be precise” — but none of those instructions give it access to reality. At some point, prompting stops helping, not because the model is weak, but because the task requires action, not language.
This article explains where that boundary is — and why tools are not an optimization, but a prerequisite for agentic systems.
This article is the first part of a three-part series focused on tools for agentic AI systems.
The goal of this first part is conceptual. It explains why tools are a necessary foundation for AI agents and why prompting alone cannot substitute for them, regardless of model quality or prompt sophistication. The focus is not on frameworks or implementations, but on the underlying limits of language models and the role tools play in overcoming those limits.
In Part 2, we will move from concepts to practice and show, step by step, how Python functions are turned into tools and how those tools are used inside agents built with LangChain and LangGraph.
In Part 3, we will focus on a concrete application: using built-in LangChain tools — especially Pandas agents — to perform real data analysis with large language models.
From Guessing to Acting: The Limits of LLMs Alone
Large language models operate by predicting the next token in a sequence. This makes them extremely effective at producing fluent explanations, plans, and justifications. It does not make them capable of interacting with the external world.
A language model has no direct access to reality. It cannot query live systems, retrieve private information, execute deterministic computations, or maintain persistent state beyond what fits into its context window. Everything it produces is generated within the closed loop of text prediction.
As a result, a model operating without tools can only describe actions, not perform them. It can explain how to check a database, how to calculate a value, or how to trigger a workflow — but it cannot do any of those things itself.
When early agent prototypes fail, a common reaction is to refine prompts. Developers add rules, enforce step-by-step reasoning, or instruct the model to double-check its answers. These techniques often improve the appearance of reasoning, but they do not expand the model’s capabilities.
There are hard limits that prompting cannot overcome:
- No prompt can grant access to live or private data.
- No prompt can make numerical computation deterministic.
- No prompt can persist state across executions.
- No prompt can trigger external side effects.
Prompting operates entirely within the model’s text-generation boundary. As long as the interaction remains confined to that boundary, the model is forced to rely on approximation and inference rather than observation.
This is where tools become essential. Tools allow the system surrounding the model to supply real inputs, execute precise operations, and return observable results. With tools, the model can stop guessing and begin grounding its reasoning in outcomes produced by external systems.
This shift — from producing plausible answers to acting on real information — is the point at which a language model can begin to function as part of an agentic system.
How Tools Let Models See and Act
Tools extend language models by giving them access to capabilities that cannot be learned through text prediction alone. Instead of relying purely on internal representations, the model can interact with external systems and incorporate their outputs into its reasoning.
In practice, tools address several fundamental limitations of language models.
They allow access to information beyond the training data. With retrieval systems, search APIs, or database queries, an LLM can work with up-to-date, private, or domain-specific information that would otherwise be unavailable.
They introduce determinism where approximation is not acceptable. Numerical computation, data transformations, and structured parsing are tasks where probabilistic reasoning often produces subtle errors. By delegating these operations to external tools — calculators, code execution environments, or data-processing libraries — the system can rely on exact results.
They provide a mechanism for memory and state. Language models have no inherent persistence beyond their context window. Tools make it possible to store and retrieve information explicitly, enabling continuity across steps, sessions, or workflows.
They enable interaction with external systems. APIs, messaging services, and workflow engines allow an agent not just to reason about actions, but to carry them out.
Once tools are available, the interaction between the user, the model, and the system follows a clear sequence:
- The user asks a question
- The LLM decides which tool is appropriate
- The system executes that tool
- The result is returned to the LLM
- The model uses the observed result to produce the next step or final answer
This loop — observe → think → act — is what turns a static language model into a system capable of grounding its reasoning in reality. Most agent frameworks are simply different implementations of this same loop.
Tool Calling: How LLMs Select and Use Tools
Tool calling is the mechanism that allows a language model to request actions from external systems. Despite the name, an LLM does not execute tools itself. It generates structured text that represents an intention to invoke a tool with specific parameters.
When tool calling is enabled, the model is provided with a set of available tools, each defined by a name, a description, and an input schema. Based on the user’s request, the model decides whether a tool is needed and produces a structured request specifying:
- which tool to call,
- and which arguments to supply.
An external system interprets this request, executes the tool, and returns the result to the model. The model then incorporates that result into its next reasoning step or final response.
A typical interaction follows this sequence:
- The user asks a question that requires external information or action.
- The model selects an appropriate tool and outputs a structured tool call.
- The surrounding system executes the tool and returns the result.
- The model uses the observed output to continue reasoning or produce an answer.
For example, when asked for the current price of Bitcoin, a model may output a request such as:
{ "tool": "crypto_price_lookup", "symbol": "BTC" }
The application retrieves the live price using corresponding tool and returns it to the model, which then generates a grounded response.
Throughout this process, the model remains a text generator. What changes is that some of the text it produces is interpreted as action requests rather than user-facing answers. Tool calling therefore establishes a clear separation: the model decides what should be done, while the surrounding system determines how it is done.
This separation is what allows probabilistic reasoning to be combined with deterministic execution in agentic systems.
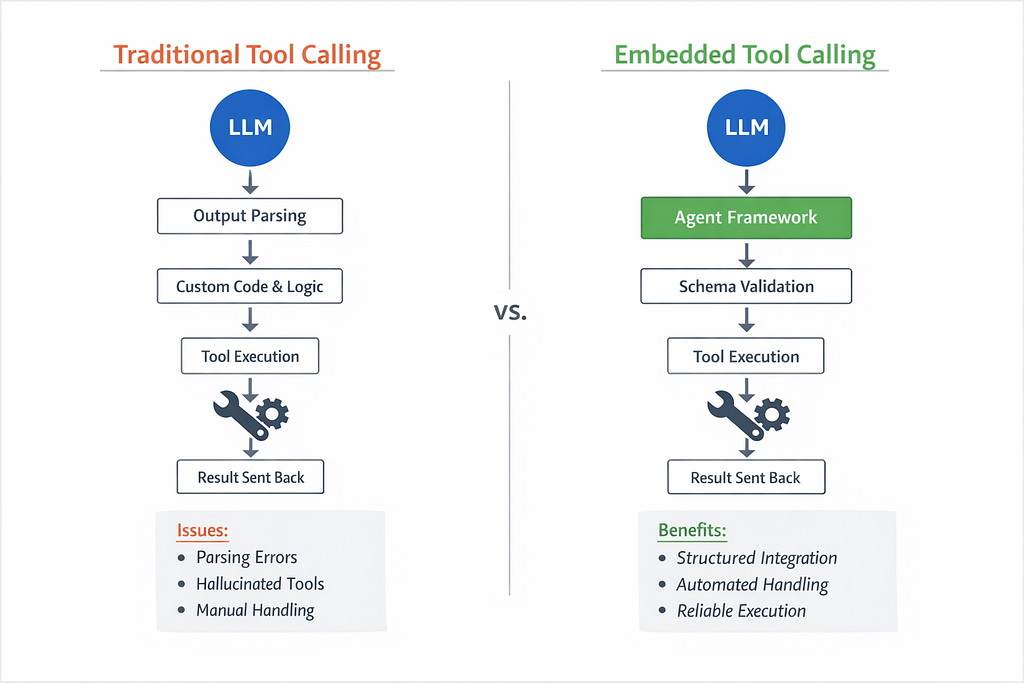
Traditional Tool Calling vs. Embedded Tool Calling
In a traditional setup, tool calling is handled manually by the application. The language model suggests a tool to use, the application parses the model’s output, executes the tool, and then feeds the result back to the model.
This approach works, but it is fragile. The model may hallucinate tool names, generate malformed parameters, or produce outputs that are difficult to parse reliably. Error handling, retries, and validation must all be implemented explicitly, often through additional prompting and custom glue code.
Embedded tool calling addresses these issues by placing a framework or library between the model and the tools. Instead of treating tool calls as loosely structured text, the framework:
- attaches tool definitions and schemas directly to the model’s context,
- interprets structured tool-call outputs,
- executes tools safely,
- and handles validation and retries automatically.
The key difference is not convenience, but correctness. By enforcing schemas and execution boundaries, embedded tool calling reduces ambiguity and makes tool usage predictable. This is why modern agent systems rely on embedded tool calling rather than ad hoc parsing of model outputs.
Why Some Tools Work — and Others Confuse Models
Exposing a function to a language model does not automatically make it usable. For an LLM, a tool is effective only if its interface minimizes ambiguity during selection, invocation, and interpretation of results.
In practice, effective tools share a small set of properties:
- Clear intent
A tool should have a single responsibility and a name that clearly signals when it should be used. Ambiguous or overloaded tools are difficult for models to select correctly. - Purpose-driven descriptions
Tool descriptions are decision aids for the model, not documentation for humans. Good descriptions explain when the tool should be used, not just what it does. - Structured inputs
Clearly defined arguments reduce malformed calls and make tool invocation more reliable, especially when multiple tools are available. - Predictable outputs
Consistent output formats allow the model to incorporate results into subsequent reasoning steps without guesswork. - Concrete examples
Examples help the model map natural language requests to tool usage more reliably than abstract descriptions alone.
Tools that satisfy these criteria reduce uncertainty at every step of the agent loop. As a result, agents built on top of them behave consistently rather than opportunistically.
Example: Why Tool Descriptions Matter
Consider a simple function that extracts a date from text.
A minimal implementation might look like this:
def extract_date(text: str) -> str:
"""Extracts a date from text."""
...
For a human reader, this description may seem sufficient. For a language model, it provides almost no guidance. The model has no indication of when the tool should be used, what formats are supported, or what the output represents.
Now compare this with a tool-ready description:
def extract_date(text: str) -> str:
"""
Extracts a single date from natural-language text when the date is written
in ISO format (YYYY-MM-DD).
Parameters:
- text (str): A user message that may contain a date.
Returns:
- dict: {"date": <string or null>}
If a date is found, return the extracted date string.
If no date is found, returns null.
Example Input:
"Schedule a meeting on 2025-03-18."
Example Output:
{"date": "2025-03-18"}
"""
...
Conclusion
Language models are powerful reasoning engines, but they operate within a closed loop of text generation. No amount of prompting can grant them access to external information, deterministic computation, or real-world side effects. Tools are the mechanism that bridge this gap.
In this article, we focused on why tools are essential for agentic systems and what properties make a tool usable by a language model. We intentionally avoided implementation details, frameworks, and code. Those choices were deliberate. Without a clear conceptual foundation, tool-based agents tend to be fragile, opaque, and difficult to reason about.
In Part 2, we will move from principles to mechanics. We will build tools step by step, expose them to agents, and examine how different agent architectures use them in practice. The goal will be to translate the design principles discussed here into concrete, working systems.
The Hard Limit of Prompting — and Why AI Agents Need Tools was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.