
Build Advanced RAG with LangGraph
Bringing together Self-reflection, Corrective, and Adaptive systems
We all know and love Retrieval-Augmented Generation (RAG). The simplest implementation of Retrieval-Augmented Generation (RAG) is a vector store with documents connected to a Large Language Model to generate a response from a query. This is known as a Single Step Approach. For simple queries this strategy is quite effective, especially if the documents have the answer the user is looking for.
However, LangGraph introduced architecture that can enhance the RAG system for advanced capabilities:
- Self-reflective Retrieval Augmented Generation is when the system checks and critiques its own answers and/or the retrieved evidence, and then uses that reflection to decide whether to retrieve more information, revise the answer, or stop. Inspired from the paper: Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
- Corrective Retrieval Augmented Generation is designed to detect when retrieved documents are wrong or insufficient and then correct the retrieval before answering. Inspired from the paper:
Corrective Retrieval Augmented Generation - Adaptive Retrieval Augmented Generation is an approach where the system dynamically decides whether, when, and how much to retrieve external information based on the question, instead of always retrieving from the vector store. inspired from the paper: Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity
In this article I will take you through the steps to combine all these features together into one powerhouse RAG system!
👉Check out the Sources below for more information!
👉Check out the Github repo for all the code!
🚨In order to build this system you will need:
– an API Key for OpenAI
-TAVILY API Key
🤖 Tavily is how we will do our web searches, its a great tool!
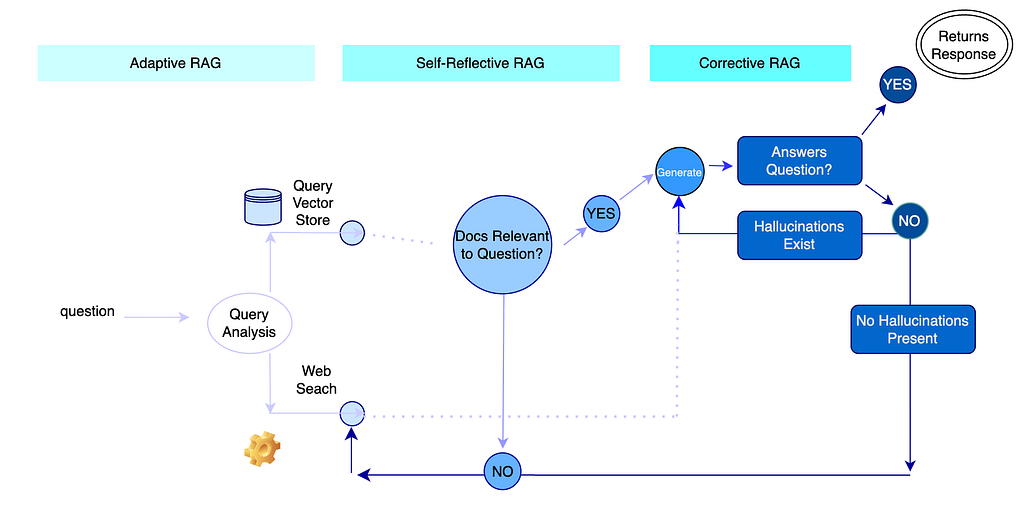
Architecture
And let’s break it down:
- If Vector Store is selected:
1a. If Vector Store has relevant documents
-> Then generate an answer
->> If Answer is relevant to Question
->>> If Hallucinations DO NOT exist
->>>> Return the response.
2a. If Vector Store DOES NOT have relevant documents
-> Then Web search
->> Then generate an answer
->> If Answer is relevant to Question
->>> If Hallucinations DO NOT exist then return the response.
->>>> Return the response.
2. If Web Search is selected:
->> Then generate an answer
->> If Answer is relevant to Question
->>> If Hallucinations DO NOT exist then return the response.
->>>> Return the response.
3. After response is Generated:
3a. If Answer is not relevant to the Question
-> Check for Hallucinations
->>If Hallucinations Exist Generate a new response
->>>Check if Answer is relevant to the Question
->>>>Continue on with logic flow
3b. If Answer is not relevant to the Question
-> Check for Hallucinations
->>If Hallucinations DO NOT Exist go to Web Search
->>>Continue on with logic flow
Files we will be using:
graph/
- chains/
-- answer_grader.py
-- generation.py
-- hallucination_grader.py
-- retrieval_grader.py
-- router.py
- nodes/
-- generate.py
-- grade_documents.py
-- retrieve.py
-- web_search.py
- consts.py
- state.py
ingestion.py
main.py
graphs/chains and graph/nodes mapped out:

LangGraph
LangGraph is a workflow that will create the logic flow for your agent behavior. It has three components:
- State: A shared data structure reflecting the application’s current state.
- Nodes: Functions that encode the logic for your agent and do a computation. The input is the current state and the output is an update to that state.
- Edges: Functions that decide which Node to fire based off the current state. They can be conditional branches or fixed transitions.
Nodes are the workers and edges use the output of the node to make a logical determination of the next path foward.
Ingestion
First step is to create out vector database, for this I used Chroma.
👉Chroma is a developer-friendly local vector database. It’s scalability is. limited, has persistent storage and has great integration with LangChain
Chains
Chains represent linear, sequential flows. Traditional chains are generally acyclic and pass data forward linearly.
We have four:
- generation: Create the LLM that can take in prompts from a web search, returns a RESPONSE
- router: LLM evaluator on if the question should go to the vector store or a web search, returns YES or NO
- answer_grader: Create an LLM evaluator to assess if the response is relevant to the question, returns YES or NO
- hallucination_grader: Create an LLM evaluator to assess if the response is relevant to the question, returns YES or NO
- retrieval_grader: Create an LLM evaluator to assess if the retrieved documents is relevant to the question, returns YES or NO
Nodes
In LangGraph Nodes are functional, independent units of computation (e.g., an LLM call or tool execution) that act on a shared state. Nodes allow for cyclic graphs, complex branching, and stateful, agentic workflows
We have four nodes:
- retrieve: If router has chosen RAG then bind the vector store with the question to retrieve the documents.
- generate: If Vector Store is chose by the router, then generate a response from RAG. Send question and documents the LLM for a response.
- grade_documents: Go through a list of retrieved documents, call the retrieval_grader and evaluate each document. If a document is not relevant then do a web search.
- web_search: If Web Search was chosen, then use Tavily to crawl the web. Select 3 webpages, concat the text into one string and send question and string to the LLM for a response.
Edges
Let’s do another review of our graph, if we recall we had three areas where a binary decision will be made. If we recall, edges are functions that decide which Node to fire based off the current state. We have three:
– route_question: Takes the input question and sends it to router, returns binary response from router (to do websearch or not)
– grade_generation_grounded_in_documents_and_question: Takes the retrieved documents and the generation, and sends it to the hallucination_grader, returns binary response if hallucinations are present
-decide_to_generate: Takes the output from grade_documents and makes the the next code call, returns a binary response if the system can proceed with generation or do a web search.

Graph
The graph in LangGraph simply brings all the pieces together. At this point you should have your nodes and edges defined, along with your state.
First thing to do is add nodes to the graph:
add_node Adds a new node to the StateGraph, need a label for the node, followed by the function name.
RETRIEVE = "retrieve"
GRADE_DOCUMENTS = "grade_documents"
GENERATE = "generate"
WEBSEARCH = "websearch"
workflow = StateGraph(GraphState)
workflow.add_node(RETRIEVE, retrieve)
workflow.add_node(GRADE_DOCUMENTS, grade_documents)
workflow.add_node(GENERATE, generate)
workflow.add_node(WEBSEARCH, web_search)
set_conditional_entry_point Decide which node the graph should start from at runtime, based on the initial input or state, instead of always starting from a fixed node. In our case it calls the route_question edge. The conditional mapping dictionary maps outer output to the graph node name.
workflow.set_conditional_entry_point(
route_question,
{
WEBSEARCH: WEBSEARCH,
RETRIEVE: RETRIEVE,
},
)
Now let’s define a fixed transition in a flow using add_edge. After the RETRIEVE node finishes, the workflow should automatically move to the GRADE_DOCUMENTS node.
workflow.add_edge(RETRIEVE, GRADE_DOCUMENTS)
Now, I think we are getting the hang of it? We just follow the flow in the graph above and keep going along:
workflow.add_conditional_edges(
GRADE_DOCUMENTS,
decide_to_generate,
{
WEBSEARCH: WEBSEARCH,
GENERATE: GENERATE,
},
)
workflow.add_conditional_edges(
GENERATE,
grade_generation_grounded_in_documents_and_question,
{
"not supported": GENERATE,
"useful": END,
"not useful": WEBSEARCH,
},
)
workflow.add_edge(WEBSEARCH, GENERATE)
workflow.add_edge(GENERATE, END)
app = workflow.compile()
Test
Vector Search
Question: What is chain of thought in task Decomposition in an Agent System?
---ROUTE QUESTION---
---ROUTE QUESTION TO RAG---
---RETRIEVE---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: NOT ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, INCLUDE WEB SEARCH---
---WEB SEARCH---
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
Response:
"Chain of thought (CoT) in task decomposition involves breaking down complex tasks into clear,
logical steps to enhance model performance. It transforms big tasks
into manageable ones and provides insight into the model's thinking process.
Tree of Thoughts extends CoT by exploring multiple reasoning possibilities
at each step, creating a tree structure for problem-solving."
Web Search
Question: What is blast used for in bioinformatics?
---ROUTE QUESTION---
---ROUTE QUESTION TO WEB SEARCH---
---WEB SEARCH---
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
Response:
"BLAST is used in bioinformatics to compare DNA, RNA, or protein sequences
against a database to find similar sequences. It is essential in genome
annotation, finding gene mutations linked to diseases, and comparing species
in evolutionary biology. BLAST is a powerful tool for sequence analysis and
is commonly used in clinical diagnostics."
Okay, looking good so far! Let’s ask a question that will cause the system to hallucinate and see how it responds.
Question: Who was the first CEO of Google Brain Labs Europe?
👉This is a notorious question for assessing hallucinations in your architecture because Google Brain Labs Europe does not exist.
---ROUTE QUESTION---
---ROUTE QUESTION TO WEB SEARCH---
---WEB SEARCH---
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---
---GENERATE---
.....
There are a ton of more testing we can do, but I think this exemplifies what the system is capable of!
Wow, what a journey! I hope you liked this tutorial and I hope it inspires you to create your own advanced RAG systems!
Sources:
https://medium.com/media/99e88d73094dbc52bb3f631a89464cea/href
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
https://medium.com/media/869e1710c3e67736574965e832ef1473/href
- Self-Reflective RAG with LangGraph
- langgraph/examples/rag/langgraph_adaptive_rag_cohere.ipynb at main · langchain-ai/langgraph
https://github.com/emarco177/langgraph-course/tree/project/agentic-rag
Build Advanced RAG with LangGraph was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.