
UV + vLLM + Python-Rust Robyn API + Qdrant: Ultimate AI Engineering Rig
Just a simple yet effective engineering setup for folks into training SLMs for downstream tasks.
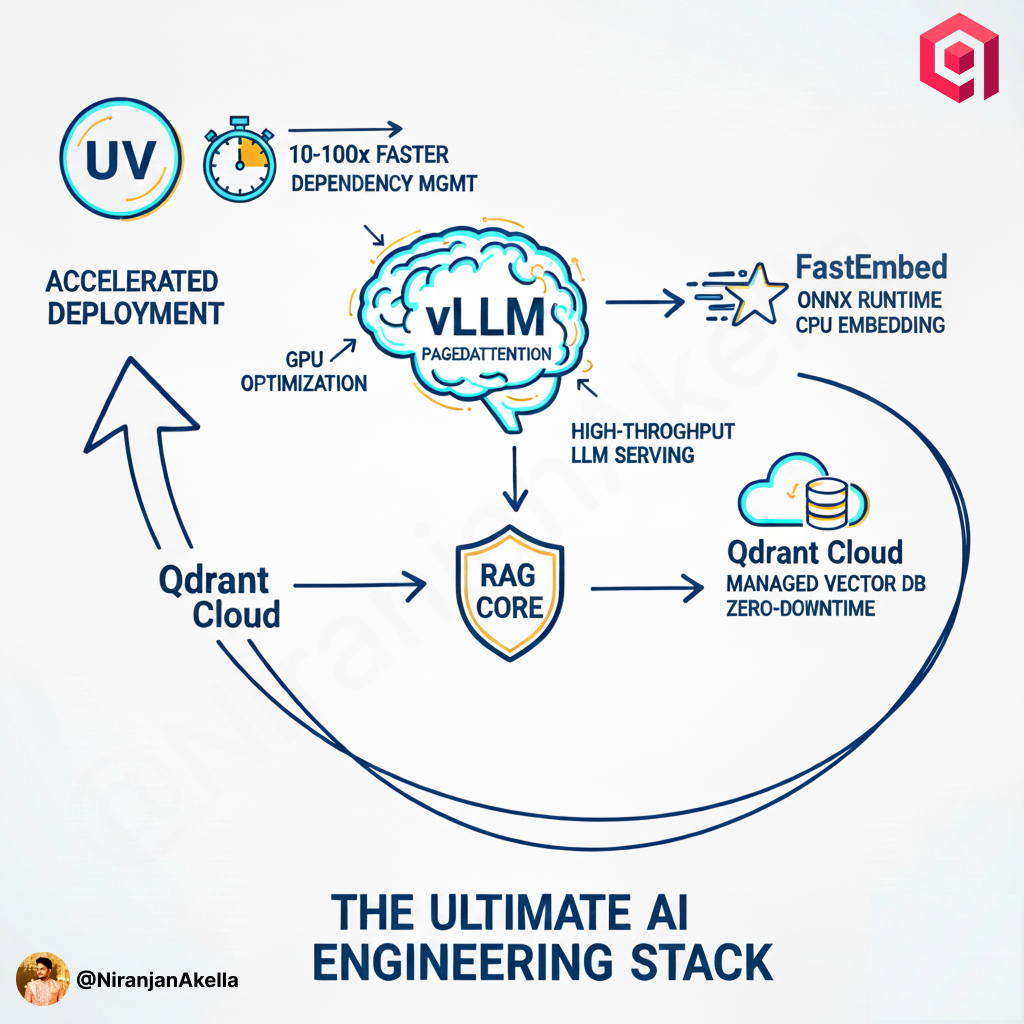
The modern AI engineering landscape demands efficient scalable and performant solutions for deploying machine learning models and handling high-throughput inference workloads.
Here I explore a cutting-edge technology stack that combines UV (ultra-fast Python package manager), vLLM (high-performance LLM serving), Robyn (Rust-powered Python web framework), and Qdrant (developer-friendly Vector DB) to create the best AI engineer’s place of zen during development & testing.
This stack represents the next generation of AI engineering tools, optimised for both Small Language Models (SLMs) and large-scale deployment scenarios. We’ll cover everything from environment setup to advanced workflows with CrewAI integration and Vision Language Models like Pali Gemma.
UV Environment Creation and Setup
UV is a revolutionary Python package manager written in Rust that delivers blazing fast 🚀 package installation and dependency resolution. Unlike traditional tools like pip and conda, UV provides 10–100x faster performance while maintaining full compatibility with the Python ecosystem. Can be installed with just a simple pip install uvat the base python environment level.
I generally setup my project environments in a root folder called envs/ that helps me activate various environments easily and keep a track of all of them in one place. And deleting any environment is as simple as just deleting that env folder from the envs directory.
uv venv test_env --python 3.11
Foundation First: UV’s 100x Speed Advantage
The efficiency of your CI/CD pipeline starts with dependency management. Traditional tools like pip are slow, constrained by the Python Global Interpreter Lock (GIL) and inefficient backtracking algorithms. This is where uv, the Rust-based package manager from Astral, delivers a “transformational” speed increase.
By leveraging a sophisticated SAT solver and Rust’s parallel processing capabilities, uv achieves dependency resolution and package installation speeds 10x to 100x faster than pip.1 For an AI project, shrinking a two-minute environment setup down to mere seconds directly translates into lower cloud compute costs, faster developer feedback loops, and accelerated deployment velocity.1
Zero-Latency LLM Serving: The Power of vLLM
For high-throughput LLM serving, vLLM is the current technical benchmark. Its core innovation, PagedAttention, solves the critical problem of Key-Value (KV) cache memory fragmentation on the GPU.
Conventional systems waste significant GPU memory by allocating large, contiguous blocks for the KV cache. PagedAttention, inspired by operating system virtual memory, manages the KV cache in fixed-size, non-contiguous blocks. This dynamic allocation eliminates external fragmentation and minimizes waste, enabling vLLM to significantly increase the concurrent batch size. The result is a 2x to 4x improvement in throughput compared to state-of-the-art alternatives, all while maintaining the necessary low Time to First Token (TTFT) and consistent Time Per Output Token (TPOT) for a fluid user experience.
The Future-Proof RAG Core: fastEmbed + Robyn
The true future-proofing of the rig lies in marrying ultra-fast retrieval with a non-blocking API gateway.
A. fastEmbed: Blazing-Fast Embedding Retrieval
fastEmbed, maintained by Qdrant, is an on-CPU embedding engine that prioritizes speed and minimal dependencies. By integrating quantized models with the highly efficient ONNX Runtime, fastEmbed delivers superior retrieval performance:
- 50% faster than PyTorch Transformers
- Better performance than traditional Sentence Transformers and OpenAI Ada-002.6
This architecture allows expensive GPU resources to be reserved solely for vLLM’s complex LLM inference, pushing the retrieval phase to cheaper, horizontally scalable CPU compute.
B. Robyn: Eliminating the API Bottleneck
The high-speed output of fastEmbed requires an API gateway capable of massive concurrency. This eliminates the need for traditional Python frameworks like FastAPI/Uvicorn, which rely on the ASGI interface and ultimately hit a ceiling around 250 Requests Per Second (RPS) due to saturation of the Python Event Loop and the GIL.
Robyn, built on a custom Rust runtime, is a drop-in Python framework that completely bypasses the GIL. Load tests demonstrate Robyn’s stability and speed even at 10,000+ RPS, making it the only viable choice for a production-grade AI gateway.
C. The Synergy: Future-Proofing Latency
The fastEmbed + Robyn combination guarantees end-to-end low P99 latency. fastEmbed provides the speed for vector generation, and Robyn provides the necessary concurrency and stability to ensure that high-velocity requests are never bottlenecked at the API layer, securing the system against future scaling challenges.
- Pull the Qdrant client container from the Docker Hub. Then run the container using the following command, which will host the application at `localhost:6333`.
docker pull qdrant/qdrant
docker run -p 6333:6333 -p 6334:6334
-v $(pwd)/qdrant_storage:/qdrant/storage:z
qdrant/qdrant
NOTE: If you are running on Windows, kindly replace $(pwd) with your local path.
Press enter or click to view image in full size

import os
import json
from robyn import Robyn
from fastembed import TextEmbedding
from qdrant_client import QdrantClient
from qdrant_client.http.models import PointStruct, SearchParams, Filter, FieldCondition, MatchValue
app = Robyn(__file__)
embedding_model = TextEmbedding()
QDRANT_URL = os.environ.get("QDRANT_URL", "http://localhost:6333")
QDRANT_COLLECTION = "rag_documents"
qdrant_client = QdrantClient(url=QDRANT_URL)
async def call_vllm_server(prompt: str):
return f"vLLM calling can be done here as you wish wit hthe prompt, {prompt}"
@app.post("/rag_search_and_generate")
async def rag_pipeline(data: dict):
"""
Combining fastEmbed for embedding, Qdrant for retrieval, and a call to vLLM.
"""
query: str = data.get("query", "")
query_vector = list(embedding_model.embed([f"query: {query}"]))[0].tolist()
search_results = qdrant_client.search(
collection_name=QDRANT_COLLECTION,
query_vector=query_vector,
limit=3, # top 3 results
search_params=SearchParams(
hnsw_ef=128,
exact=False
)
)
context = "n---n".join([hit.payload.get('text', '') for hit in search_results])
rag_prompt = f"Context: {context}nnQuestion: {query}"
llm_response = await call_vllm_server(rag_prompt)
return {
"status": 200,
"query": query,
"retrieved_context_count": len(search_results),
"llm_response": llm_response,
}
Scaling the Data Layer: Qdrant Cloud is all you NEED!!
The final piece is a resilient, fully managed vector database. Qdrant Cloud offers managed scalability across AWS, GCP, and Azure, eliminating the operational burden for developers.
Crucially, Qdrant Cloud offers advanced, developer-centric features essential for enterprise-grade RAG:
- Zero-Downtime Upgrades: Ensure continuous service when scaling clusters.
- Resource Efficiency: Compression options dramatically reduce memory usage.
- In-Cluster Inference: Qdrant Cloud allows for the generation of embeddings directly inside the cloud cluster network. This pivotal feature eliminates the external network hop required by separate embedding services, directly and dramatically reducing network latency for the retrieval phase, which is a major win for controlling P99 latency in production.
This complete stack right from package management to API serving, LLM inference, retrieval, and data hosting provides the fastest, most scalable, and most resilient foundation for modern AI applications.
UV + vLLM + Python-Rust Robyn API + Qdrant: Ultimate AI Engineering Rig was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.