
Sequence Packing and Token Weighting
References
- Molmo 2: State-of-the-art video understanding, pointing, and tracking
- Efficient LLM Pretraining: Packed Sequences and Masked Attention
- From Equal Weights to Smart Weights: OTPO’s Approach to Better LLM Alignment
Background
Training large vision-language models (VLMs) like Molmo2, a next generation multi-modal model poses unique computational and learning challenges. Molmo2 is an open-source model trained for tasks ranging from image captioning, visual question answering and most importantly visual grounding.

Two key techniques that address these challenges are sequence packing and token weighting. These strategies play vital role when dealing with real-world data where inputs vary wildly in length and significance.
Problem with Variable-Length Inputs
In traditional language or vision-language training pipelines, each training example is often padded to match the longest sequence in a batch. For instance, if one sample contains a 500-token prompt and another only 20 tokens, the shorter one gets padded with hundreds of “dummy” tokens. This padding ensures uniform tensor shapes for GPU processing, but it comes at a cost:
- Wasted computation: The model still processes padded tokens, even though they carry no semantic meaning.
- Reduced throughput: GPUs spend cycles on useless operations instead of meaningful learning.
- Memory inefficiency: Padding inflates memory usage, limiting batch size and slowing down training.
This problem is especially acute in multi-modal settings, where inputs combine images, text prompts, and generated responses of highly variable lengths.
Sequence Packing: Smart Batching for High Throughput
Sequence packing solves this by concatenating multiple training samples into a single fixed-length sequence, eliminating the need for per-sample padding.
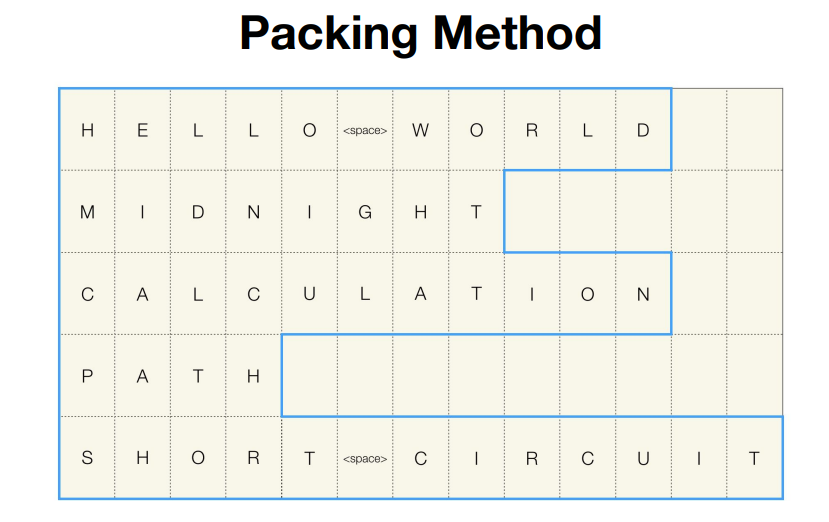
Imagine stitching together three short captions and one long description into one continuous block that exactly fills a 1024-token window. Special separator tokens or attention masks ensure the model knows where one sample ends and the next begins.
Sequence packing is widely used in LLM training like Megatron-LM, but its application in multi-modal models like Molmo2 is particularly impactful. Because vision-language data often includes short queries alongside long explanations.
Not All Tokens are Created Equal
Even after solving the padding problem, another challenge remains: not all tokens contribute equally to learning. In a typical VLM training setup, the loss function averages errors across all output tokens. But consider this:
- A model might generate 100 tokens to describe an image, but only 5 of them convey critical information (e.g., “pedestrian crossing road” vs. filler words like “the” or “there is”).
- In instruction-following tasks, early tokens (“Sure!”) matter less than later ones that contain the actual answer.
- Some tasks (e.g., OCR or fine-grained object detection) demand high precision on specific tokens, while others (e.g., sentiment analysis) are more forgiving.

If every token contributes equally to the loss, the model may under-learn from high-stakes predictions and over-fit to low-information ones.
Token Weighting
Token weighting addresses this by assigning different loss weights to different tokens during training. In Molmo2, this could mean:
- Down-weighting common stop words or repetitive phrases.
- Up-weighting tokens that correspond to rare objects, safety-critical concepts, or task-specific keywords.
- Dynamically adjusting weights based on task type (e.g., giving higher weight to answer tokens in QA vs. descriptive tokens in captioning).

While self-attention helps the model focus internally. Token weighting directly shapes what the model learns from. It’s a form of curriculum-aware supervision that guides gradient updates toward the most informative parts of the output.
In practice, token weighting can be implemented via:
Heuristic Rules
This approach uses pre-defined, human-designed rules to assign weights based on linguistic or semantic properties of tokens. For example, you might automatically down-weight common stop words like “the,” “and,” or “is” because they carry less task-specific meaning. Conversely, you up-weight rare or semantically rich token, like “pedestrian” in autonomous driving or “tumor” in medical imaging , because errors on these tokens are costlier.
Task-Aware Mask
Here, weights are assigned dynamically based on the type of task the model is performing. In a visual question-answering (VQA) task, answer tokens (e.g., “red,” “three”) receive higher weight, while in image captioning, descriptive nouns and adjectives might be prioritized. This mask is often generated alongside the label and tells the loss function: “Pay more attention here.”
Conclusion and Final Thought
Together, sequence packing and token weighting form a powerful duo that significantly enhances the efficiency and intelligence of multi-modal AI training. Sequence packing maximizes hardware utilization by reducing idle computation, while token weighting sharpens the model’s learning focus by emphasizing what to learn from, not just what to attend to. This combination doesn’t just save time and energy, it fundamentally reshapes how models acquire knowledge, making them faster, more accurate, and better aligned with human intent.
In essence, these techniques transform raw data into curated learning experiences, enabling scalable, robust, and ethically aware AI systems that can adapt across diverse tasks from medical diagnosis to autonomous navigation without wasting resources on noise or redundancy.
Sequence Packing and Token Weighting was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.