
Attention, But Smarter: Inside Jet-Nemotron’s Hybrid Design

Paper-explained Series 1
Modern language models face a fundamental trade-off: accuracy versus efficiency. Full-attention Transformers deliver strong accuracy but scale quadratically with context length O(n²), making long-context inference expensive. Linear-attention models reduce complexity to O(n) but often sacrifice reasoning ability and precision.
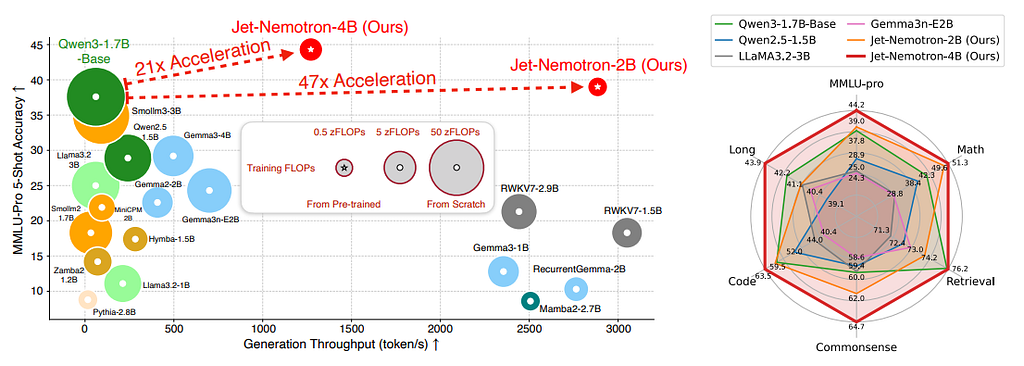
In Jet-Nemotron, NVIDIA introduces a new family of hybrid-architecture language models that match or exceed full-attention model accuracy while delivering dramatic throughput gains — without relying on MoE tricks.
This article explains how.
What Is Jet-Nemotron?
Jet-Nemotron is a family of models discovered using Post Neural Architecture Search (PostNAS) — a novel pipeline that redesigns attention architectures after pretraining.
The flagship Jet-Nemotron-2B model:
- Matches or exceeds Qwen 2.5 / Qwen 3, Gemma 3, Llama 3.2
- Outperforms recent MoE full-attention models on MMLU and MMLU-Pro
- Delivers:
– 6.1× prefilling speed-up
– 53.6× generation throughput speed-up
– Scales efficiently to 256K-token contexts
This is achieved without abandoning attention entirely, but by using it only where it truly matters.
The Core Idea: Hybrid Attention Architecture
Jet-Nemotron does not replace attention wholesale. Instead, it mixes multiple attention mechanisms — each used where it performs best.
Layer Composition:
- Full Attention
Used sparingly for tasks that require exact token-to-token precision (e.g., retrieval). - Sliding Window Attention (SWA)
Used for localized pattern matching such as multiple-choice reasoning. - JetBlock
A new linear-attention block that provides speed and expressiveness.
This hybrid design is the foundation — but the real breakthrough comes from how these layers are selected.
So how did Nvidia achieve this speed-up while maintaining the same level of accuracy??? Lets explore.
Nvidia followed 4 key techniques;
PostNAS: Finding Where Attention Actually Matters
As we all know the major bottleneck with current transformers is that they use full-attention mechanism which is powerful but remains O(n²). To improve this much research was done towards linear attention methods like mamba which does the job in O(n) but is less acuracte.
The Solution: PostNAS figures out exactly where full attention is actually needed. It trains a “super network” to test which layers matter most for specific tasks.
But How??? The overall approach is illustrated in Figure.
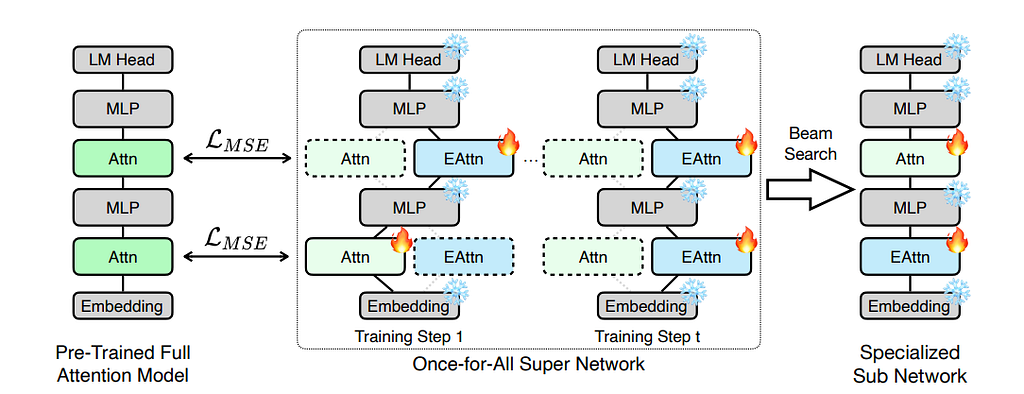
How PostNAS Works:
- Once-for-All Super-Network
Each original attention layer is augmented with alternative linear-attention paths - Random Subnetwork Sampling
During training, we randomly sample an active path at each step, forming a subnetwork, which is trained using feature distillation loss. - Beam Search Selection
Optimal layer configurations are chosen under constraints
(e.g., only two full-attention layers allowed)
The search objective is task-dependent: for MMLU, we select the configuration with the lowest loss on the correct answer (i.e., maximizing −𝑙𝑜𝑠𝑠), while for mathematical and retrieval tasks, we choose the one with the highest accuracy.
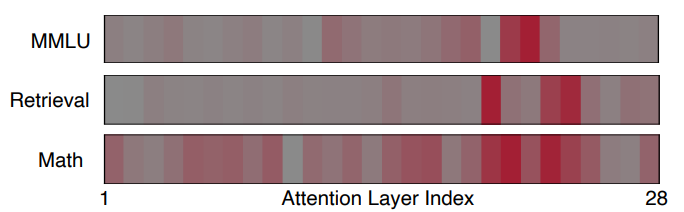
Key Finding 1: In the pre-trained full-attention model, not all attention layers contribute equally. For MMLU, only two layers exhibit critical importance, while for retrieval tasks, just two to three layers are particularly crucial.
Key Finding 2: Different attention layers contribute to different capabilities. Layers that are critical for MMLU accuracy are not necessarily important for retrieval tasks.
Note: Instead of starting from scratch, PostNAS begins with a pre-trained full-attention model (like Qwen2.5). It freezes the heavy Multi-Layer Perceptron (MLP) weights of the original model to save training costs. Then, it focuses purely on redesigning and optimizing the attention blocks.
Linear Attention Block Selection
Once the replaceable layers are identified, the next question is:
Replace them with what? In thier experiments, they evaluate six SOTA linear attention blocks, including RWKV7, RetNet, Mamba2, GLA, Deltanet, and Gated DeltaNet.
Gated DeltaNet achieves the best overall accuracy among the evaluated linear attention blocks. This is attributed to the combination of two factors: a) the Data-Dependent Gating Mechanism, which dynamically controls whether the model should focus more on the current token or the history state.
b) the Delta Rule, which updates the history state with the information increment from the current token, to save the limited state memory. Therefore, we proceed with Gated DeltaNet in our experiments.
Heads-up: We will dive deeper into Gated-DeltaNet in our next articles.
JetBlock: Dynamic Convolution for Linear Attention
After selecting Gated DeltaNet as their base, the researchers found that it was not sufficiently expressive on its own. While linear attention offers strong efficiency, it can sometimes be too simple, as it processes sequences strictly in order and struggles to capture richer local patterns.
To address this limitation, they introduced convolution into the attention block. Convolution allows the model to look at small groups of neighboring tokens simultaneously — capturing phrase-level information rather than processing tokens in isolation. Prior work has shown that convolution is essential for achieving strong accuracy in many linear attention architectures. However, most existing approaches rely on static convolution kernels, which apply the same fixed filters to every input sequence and cannot adapt their feature extraction behavior based on context.
The key innovation of JetBlock is the introduction of dynamic convolution. Instead of using fixed kernels, JetBlock employs a kernel generator module that dynamically produces convolution kernels conditioned on the input itself.
Kernel Generator:
- Takes the same input as the Q/K/V projections
- Applies SiLU → Linear
- Outputs input-conditioned convolution kernels
- Kernels are generated on the fly, per sequence
This allows context-adaptive local feature extraction, unlike fixed filters.
Importantly, the dynamically generated convolution is applied only to the Value (V) tokens. Through empirical analysis, the researchers found that extending this complex filtering to the Query (Q) and Key (K) components provided little performance benefit while significantly increasing computational cost. By omitting convolution over Q and K, JetBlock achieves a favorable trade-off: increased expressive power without sacrificing efficiency.
Question 1: Why did researchers not see performance benefit while applying dynamic convolution to Query and Key vectors?
Hardware-Aware Architecture Search
Key Finding 3: KV cache size is the most critical factor influencing long-context and long-generation throughput. When the KV cache size is constant, models with different parameter counts exhibit similar generation throughput
This is because the decoding stage is typically memory-bandwidth-bound rather than compute-bound.
The Myth: “Fewer parameters = Faster model.”
The Reality: The authors found that KV Cache Size (the memory used to store context) is actually the biggest bottleneck for speed, not just the parameter count.
The Fix:
- They ran a search to find the perfect balance of Head Number (how many “sub-brains” the model has) and Dimension Size (how much data each “sub-brain” holds).
- They forced the model to keep a small KV Cache size (for speed) but allowed it to have more parameters elsewhere to keep it smart.
Result: A model that is “larger” on paper but runs faster on actual GPU hardware.
Question 2: We said that they increased the model parameters, so can you tell if they scaled vertically (Adding Depth) or horizontally (Adding Width)?
Sliding Window Attention (SWA)
Certain tasks need local scratchpads, not global memory.
How SWA Works
- Attention is limited to the last W tokens (e.g., 1,000)
- Earlier tokens are ignored
Why It Helps
- Efficient localized reasoning
- Excellent for:
– Multiple-choice questions
– Pattern matching
– Much cheaper than full attention
In Jet-Nemotron-2B, SWA is applied selectively (e.g., layers 21–22).
Conclusion:
Jet-Nemotron demonstrates that:
- Full attention is not universally necessary
- Careful layer placement beats blanket architectural changes
- Hardware constraints must inform model design
- Linear attention, when properly enhanced, can rival Transformers
By combining PostNAS, JetBlock, and hardware-aware search, NVIDIA achieves what previously seemed contradictory.
Until next time folks…
El Psy Congroo
Attention, But Smarter: Inside Jet-Nemotron’s Hybrid Design was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.