
Generative AI RAG Applications — Choosing RightVector Database
Generative AI RAG Applications — Choosing Right Vector Database
This is second part of the series on RAG application if you are looking to overview of RAG applications and embedding models refer to part 1. In this article I will be discussing on types of vector databases exists and which category of databases we should target for our RAG application.
lets start for some of the definitions —
- Vector Database — A vector database stores and searches high-dimensional numerical representations (embeddings) of complex data like text, images, and audio, allowing AI to find semantically similar items through efficient similarity search rather than exact keywords.
- Vector store — A vector store is a logical way of storing and retrieving vectors, not necessarily a full database. Sometimes both terms “vector database” and “vector store” used interchangeably but their is a distinction in terms of feature being offered. A vector store can be just a library wrapper on the underlying storage like cloud storage or S3.
- Similarity search — is a process of finding items in a database that are most similar to a given query item. In case of generative ai applications we talk about not the exact word matching but the meaning matching generally referred to as semantic search.
- Approximate similarity search (ANN) — is a technique used to quickly find the “nearest” or most similar items in very large collections of vectors (embeddings) without checking every single one exactly. ANN uses smart indexing and shortcuts to return results and are much faster then the exact similarity search. Popular ANN algorithms are HNSW (Hierarchical Navigable Small World Graph) , IVF / IVF-PQ (Inverted File Index + Product Quantisation), ScaNN, DiskANN etc.
- Filtering + hybrid search — Also called keyword + semantic search combines the strengths of traditional search and vector (semantic) search to get results that are both relevant in meaning and match specific constraints or keywords.
What all vector databases do —
- fast k-nearest neighbour (k-NN) search
- storage of vectors + metadata
- filtering + hybrid search (keyword + semantic)
- horizontal scaling for millions/billions of vectors
Popular Vector databases and types —
( Not the exhaustive list but overs most categories with popular onces)
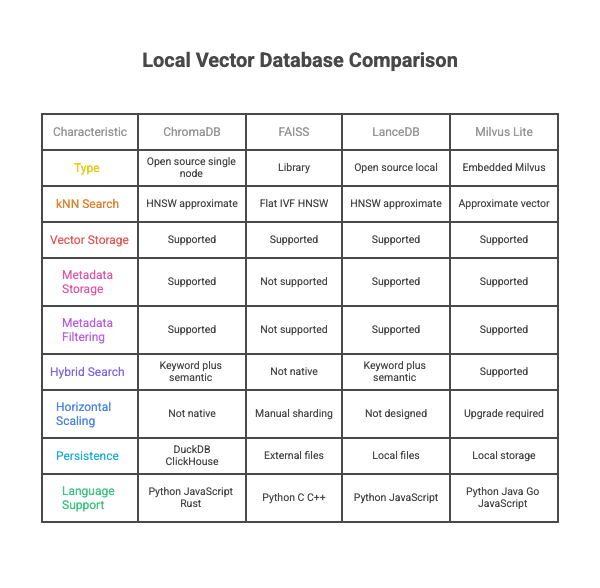
Local/Embedded Vector Stores
These are generally easy to use embedded stores for prototyping, notebooks , early stage MVPs. They generally do not support massive scaling , distributed database, enterprise SLAs or advanced security/Compliance.
- ChromaDB — ChromaDB is an open-source, single-node vector store designed for easy local use and fast prototyping. It supports LangChain and LlamaIndex out of the box and uses HNSW for approximate k-NN search. Vectors and metadata are stored together, and metadata filtering is supported. It offers Python, JavaScript, and Rust clients, and can use DuckDB, ClickHouse, or in-memory storage as a backend.
- FAISS — FAISS is a vector similarity search library, not a full database. It focuses purely on storing vectors with numeric IDs and performing fast similarity search with index types like Flat, IVF, and HNSW. It does not store metadata, does not support metadata filtering, and offers no native hybrid search. Persistence and scaling must be implemented externally using storage systems such as files, S3, or GCS.
- LanceDB — LanceDB is an open-source local vector database built on Apache Arrow and the Lance columnar format. It supports storing vectors with structured metadata and enables k-NN search using HNSW-based indexes. It provides native filtering, hybrid search with keyword + vector queries, and handles persistence automatically in local files. Provided multi model support. It is lightweight and developer-friendly.
- Milvus Lite — Milvus Lite is a lightweight embedded version of Milvus designed to run locally without a separate cluster. It supports approximate k-NN search, vector + metadata storage, and filtering similar to full Milvus, but optimised for single-machine workloads. It’s suitable for prototyping and small-to-medium datasets, with an easy upgrade path to distributed Milvus for large-scale deployments.
Cloud Managed Vector Databases
These are cloud based enterprise scale vector databases including the once’s provided by major cloud providers. They can be used for production workloads, supports millions to billions of vectors, supports enterprise features and SLA. They provide elastic scaling , high availability , managed backups but are have higher cost and have vendor lock-in.
- Pinecone — Pinecone is a fully managed, cloud-native vector database built for production workloads at scale. It supports elastic scaling across millions to billions of vectors with strong SLAs, high availability, and automatic backups. Pinecone provides fast approximate nearest neighbour search, metadata filtering, and hybrid vector + sparse search. Pinecone offers SDKs for multiple languages and integrations with frameworks like LangChain. Pinecone is SOC 2, GDPR, ISO 27001, and HIPAA certified.
- Weaviate Cloud — Weaviate Cloud is the hosted version of the open-source Weaviate vector database. It delivers enterprise-grade features such as horizontal scaling, distributed indexing, multi-tenant support, and automated backups. Weaviate natively supports hybrid search, metadata filtering, and semantic search with contextionary or custom embeddings. As a managed service it reduces operational burden while incurring higher costs and platform dependency. Clients include REST, GraphQL, and SDKs in major languages.
- Qdrant Cloud — Qdrant Cloud is a managed vector search service built on the Qdrant engine. It provides scalable, highly available search across millions to billions of vectors with SLA guarantees, automated scaling, and backups. Qdrant supports fine-grained metadata filters, payload indexing, and hybrid search patterns. Provide deployment patterns for Managed , Hybrid and Private clouds. SDKs are available in Python, JavaScript, and other languages.
- Milvus on Zilliz Cloud — Milvus on Zilliz Cloud offers the full Milvus vector engine as a managed, elastic service. Designed for large-scale enterprise workloads, it delivers distributed indexing, high throughput, multi-node HA, and multi-tenant isolation. Milvus supports many ANN indexes, advanced filtering, and hybrid search patterns. Zilliz Cloud also handles backups, scaling, and monitoring.
- Vertex AI search — Vertex AI Search (Google Cloud) is a fully managed search service combining dense vector retrieval with traditional information retrieval features. It scales elastically across large datasets, provides enterprise SLAs, high availability, and integration with other GCP services. Vertex AI Search supports rich filtering, hybrid search workflows, and can leverage Google’s embedding models.
- Alloy DB (with Vector search) — AlloyDB (Google Cloud) is a managed PostgreSQL-compatible database with vector search capabilities. It delivers enterprise features such as auto-scaling clusters, HA, backups, and integration with GCP tooling. Vector search is implemented via pgvector, allowing hybrid keyword + semantic search within SQL. AlloyDB provides reliable infrastructure for production vector workloads at scale.
- Azure AI Search — Azure AI Search is Microsoft’s managed search service with vector search support. It provides elastic scaling, high availability, SLA guarantees, and built-in cognitive enrichments. Vector retrieval, metadata filters, and hybrid scoring models (BM25 + vector) are supported. As part of Azure, it integrates with the ecosystem (Synapse, Cosmos DB, Azure Functions).SDKs are available in .NET, Python, Java, and REST.
- Amazon OpenSearch vector Search — Amazon OpenSearch Service adds vector search capabilities to the managed OpenSearch platform. It provides scalable clusters, automated backups, and HA with AWS SLAs. OpenSearch supports approximate vector search alongside traditional inverted index search for hybrid workflows. Being part of AWS gives deep integrations with the ecosystem (IAM, CloudWatch, S3). As a managed service it eases operations but involves cost and vendor coupling.

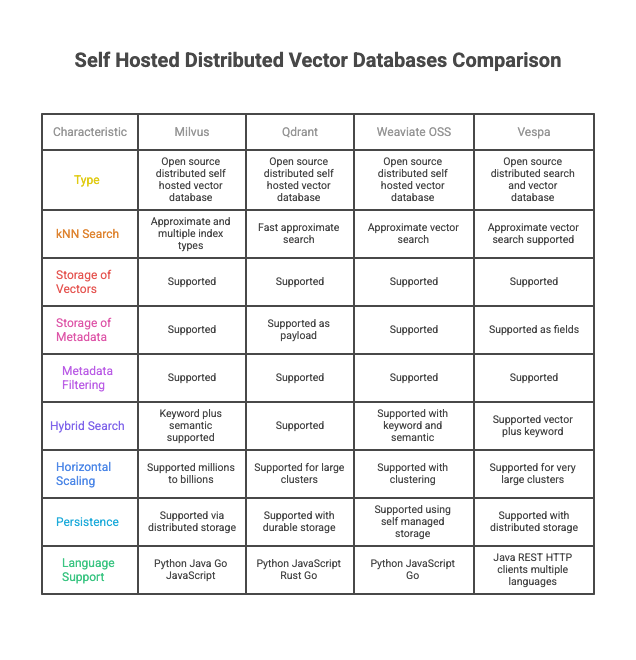
Distributed/Self Hosted Vector Databases
These are distributed and self hosted databases for enterprise scale but suited for on-prem / private cloud solutions. These needs be self hosted and supported.
- Milvus — Milvus is a distributed, open-source vector database designed for large-scale similarity search in on-prem and private-cloud environments. It supports approximate k-NN search with multiple index types and stores both vectors and associated metadata. Milvus includes native metadata filtering and hybrid search capabilities, and can scale horizontally. It is suitable for enterprise deployments but requires self-hosting, cluster management, and operational expertise, often combined with commercial support from Zilliz.
- Qdrant — Qdrant is an open-source, distributed vector database built for production-grade similarity search and recommendation systems. It supports fast approximate k-NN search, payload (metadata) storage, and expressive filtering. Hybrid search combining semantic and keyword search is supported via payload filters and scoring. Qdrant clusters can scale horizontally and are well suited for on-premise or private cloud environments where users manage their own infrastructure. Enterprise features are available through self-hosting and optional commercial support.
- Weaviate OSS — Weaviate OSS is the open-source, self-hosted version of the Weaviate vector database. It provides distributed clustering, horizontal scaling, and multi-tenant capabilities suited for enterprise environments. Weaviate supports approximate k-NN vector search, hybrid semantic + keyword search, and rich metadata filtering. It integrates with multiple embedding providers and can run in Kubernetes, private cloud, or fully on-prem installations. As an OSS system, users are responsible for operations, upgrades, and reliability unless they adopt paid support.
- Vespa — Vespa is a large-scale, open-source search and serving engine developed originally at Yahoo, supporting both vector and traditional search. It is designed for high-throughput, low-latency enterprise workloads such as recommendation, ranking, and semantic search. Vespa supports approximate k-NN, hybrid retrieval, structured metadata filters, and complex ranking pipelines. It scales horizontally across distributed clusters for billions of documents and vectors, but typically requires significant operational expertise to deploy and maintain in self-hosted environments.
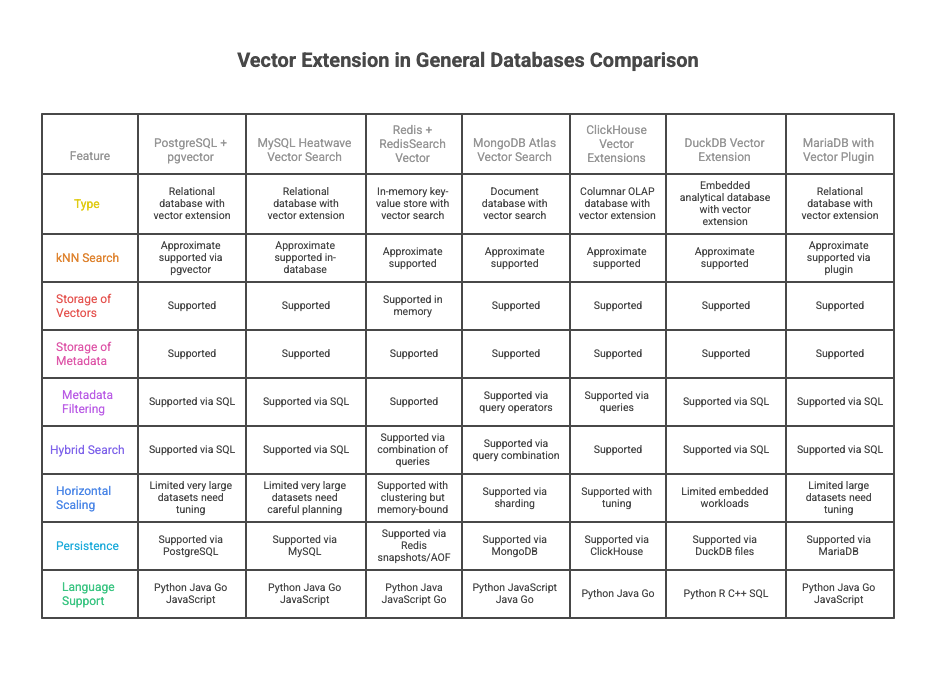
Vector Extension inside General Databases
These are the traditional databases with added vector capabilities. These simplifies existing stacks but can hit limits at large scale.
- PostgreSQL + pgvector — PostgreSQL with the pgvector extension adds vector search capabilities to the popular relational database. It supports approximate k-NN search, stores vectors and metadata in the same table, and allows filtering and hybrid search via SQL.
- MySQL Heatwave Vector Search — MySQL Heatwave integrates vector search into the MySQL database engine for in-database similarity search. It supports approximate k-NN search, vector storage alongside metadata, and filtering through SQL queries. Hybrid search is possible by combining traditional MySQL queries with vector search.
- Redis + Redis-Search vector — Redis with RedisSearch and vector capabilities allows embedding search inside the in-memory key-value store. Vectors and metadata can be stored together, with support for approximate k-NN search and filtering. Hybrid search can be implemented through combination of vector and traditional Redis queries. Being in-memory, it is extremely fast but memory-bound, and scaling to very large datasets requires clustering and memory planning.
- MongoDB Atlas Vector Search — MongoDB Atlas Vector Search adds vector search features to the managed MongoDB database. It supports k-NN search, stores vectors and metadata in the same collection, and allows filtering and hybrid search through MongoDB query operators. It is ideal for users already in the MongoDB ecosystem, but extremely large-scale workloads may require sharding and careful cluster sizing.
- Clickhouse vector extensions — ClickHouse with vector extensions allows approximate k-NN search inside the high-performance columnar OLAP database. Vectors and metadata are stored together, and filtering is supported via ClickHouse queries. It is well-suited for analytics workflows where large-scale data and vector search co-exist.
- DuckDB vector extension — DuckDB with vector extension enables k-NN vector search in an embedded, analytics-focused relational database. Vectors and metadata can be stored in tables, and filtering is possible via SQL queries. It is ideal for local analysis, notebooks, and embedded applications, but not designed for horizontal scaling or very large production workloads.
- MariaDB with vector plugin — MariaDB with a vector plugin adds vector search support to the popular relational database. It supports approximate k-NN search, stores vectors and metadata in the same table, and allows filtering and hybrid search using SQL.
Vector databases come in many flavors — embedded, cloud-managed, self-hosted, and as extensions to traditional databases. Choosing the right one for your RAG application depends on scale, deployment needs, and workflow integration. Understanding these options helps you build faster, more reliable generative AI applications.
Generative AI RAG Applications — Choosing RightVector Database was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.