 to Near-Linear O(L·n)")
DeepSeek Sparse Attention: From O(L²) to Near-Linear O(L·n)
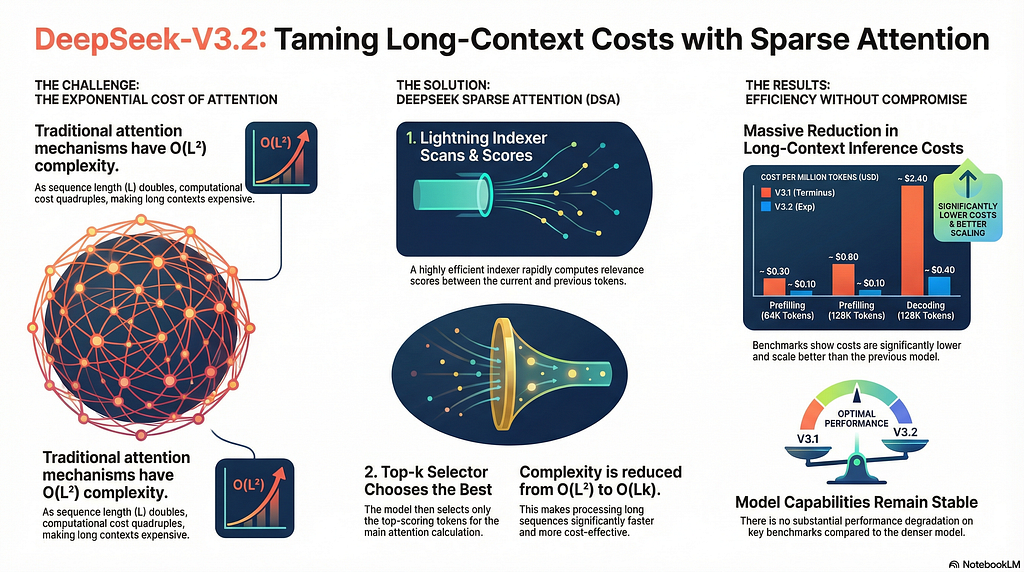
Large Language Models have a well-known scalability problem: attention does not scale.
In standard Transformers, every token attends to every previous token. For a sequence of length L, this results in O(L²) compute and memory complexity. As context windows stretch from 8K → 32K → 128K tokens, attention becomes the dominant bottleneck — both economically and computationally.
In their latest experimental model, DeepSeek-V3.2-Exp, the DeepSeek team introduces DeepSeek Sparse Attention (DSA): a fine-grained sparse attention mechanism designed to push long-context efficiency without sacrificing model capability
This article breaks down how DSA works, how it’s trained, and what trade-offs still remain.

The green part illustrates how DSA selects the top-k key-value entries according to the indexer.
The Core Idea: Attention Doesn’t Need to Look Everywhere
The central insight behind DSA is simple but powerful:
“Most tokens are irrelevant for predicting the next token”
Instead of computing full attention over all past tokens, DSA introduces a two-stage process:
- Cheap relevance estimation
- Selective full attention
This reduces effective attention complexity from O(L²) to O(L·k), where k ≪ L.
Architecture Overview: Lightning Indexer + Sparse Attention
At a high level, DeepSeek Sparse Attention (DSA) separates “figuring out what matters” from “doing expensive attention.”
This separation is what makes long-context efficiency practical instead of theoretical.
Instead of forcing every token to attend to everything, DSA asks a simpler question first:
Which past tokens are actually worth paying attention to right now?
To answer this, DSA introduces two tightly coupled components: the Lightning Indexer and a Fine-Grained Sparse Attention layer.1. Lightning Indexer: Fast Token Relevance Scoring
1. ⚡ Lightning Indexer: Learning What Matters (Fast)
The Lightning Indexer is a lightweight relevance scorer, not an attention mechanism.
For each query token, it quickly scans all previous tokens and assigns them importance scores. These scores are computed using dot products between specialized query and key projections, followed by a simple ReLU activation.
A few important design choices make this work in practice:
- Small head count → keeps computation cheap
- FP8 compatibility → extremely fast on modern hardware
- No value mixing → it never aggregates context, only ranks relevance
This is a crucial distinction. The indexer does not try to understand or reason — it only answers “Which tokens are likely to be useful?”
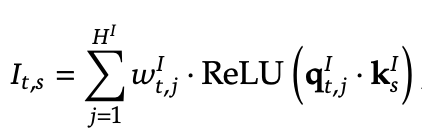
Because of this narrow role, it can afford to run over the entire sequence, even at long context lengths.
2. 🎯 Fine-Grained Token Selection: Spend Compute Where It Counts
Once relevance scores are computed, DSA performs a top-k selection. Only the most important key–value pairs are retained, and everything else is ignored.
This is where the real efficiency gains come from.

Instead of full attention over L tokens, the model now applies standard attention over k ≪ L tokens:
- Same attention math
- Same expressive power
- Radically lower compute and memory cost
In other words, attention is no longer diluted across thousands of irrelevant tokens — it is focused, intentional, and sparse.
Why Multi-Query Attention (MQA) Matters Here
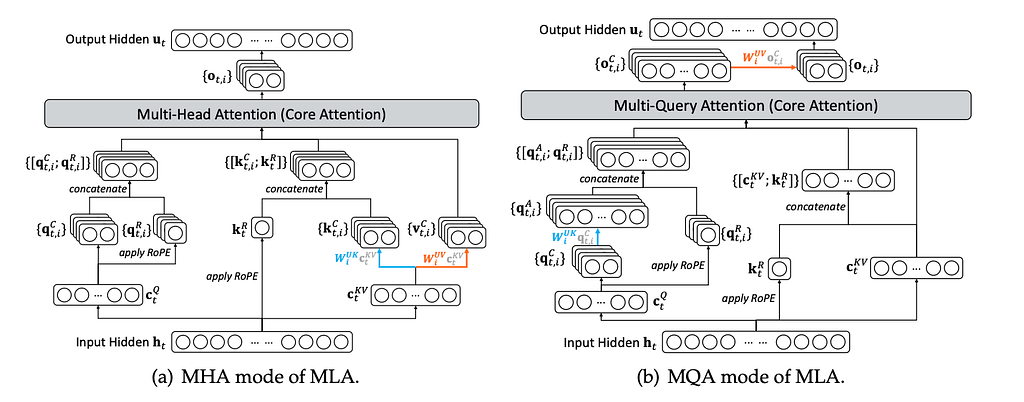
MHA mode is used for training and prefilling, while the MQA mode is used for decoding.
DeepSeek instantiates DSA under Multi-Query Attention (MQA) rather than classic multi-head attention.
Why?
- Key–value entries must be shared across query heads for efficiency
- MQA allows sparse selection without duplicating KV storage
- This choice enables DSA to integrate cleanly into DeepSeek-V3.1 without architectural disruption
Training DSA Is the Hard Part
Sparse attention is not plug-and-play. Training it incorrectly leads to severe performance collapse.
DeepSeek addresses this with a two-phase continued training strategy, followed by post-training.
Phase 1: Continued Pre-Training
Stage 1 — Dense Warm-Up: Teaching the Indexer What Matters
In the Dense Warm-Up stage:
- The model keeps full dense attention
- All parameters are frozen except the lightning indexer
- The indexer is trained to imitate full attention patterns
This is done by:
- Aggregating attention scores across all heads
- Normalizing them into a probability distribution
- Training the indexer using KL-divergence loss
This aligns sparse relevance scoring with dense attention behavior before sparsity is introduced
Stage 2 — Sparse Training: Learning to Survive with Less Context
Once the indexer is reliable:
- Fine-grained token selection is enabled
- The model predicts tokens using only top-k context
- All parameters are optimized jointly
Importantly:
- The indexer is trained only via KL loss
- The main model is trained only via language modeling loss
- Gradients are carefully decoupled to ensure stability
This stage adapts the model to sparse context without catastrophic forgetting
Phase 2: Post-Training with Reinforcement Learning
After continued pre-training, DeepSeek applies the same post-training pipeline used for prior models — but now entirely under sparse attention.
Specialist Distillation
- Domain-specific specialists (math, reasoning, coding, agents) are trained via large-scale RL
- These specialists generate high-quality domain data
- The final model is distilled from this data
Mixed RL with GRPO
Instead of multi-stage RL, DeepSeek merges:
- Reasoning
- Agent behavior
- Human alignment
into a single GRPO-based RL stage, reducing catastrophic forgetting and stabilizing training across skills
Does It Actually Work?
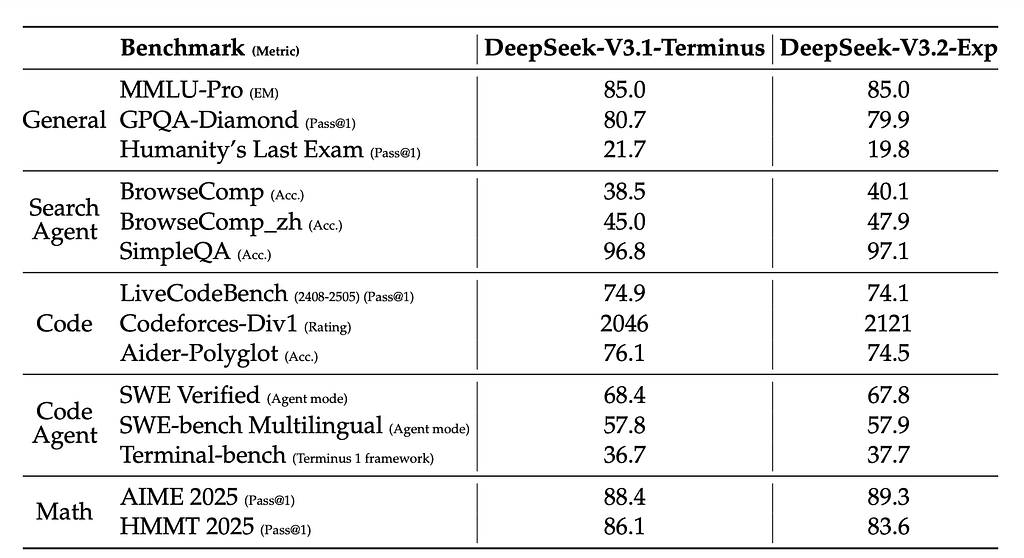
Performance
Across benchmarks (MMLU, GPQA, SWE-bench, AIME, Codeforces), DeepSeek-V3.2-Exp shows no substantial degradation compared to the dense baseline.
Some reasoning benchmarks show minor drops due to shorter reasoning traces, not worse reasoning ability — this gap closes when token lengths are matched
Efficiency Gains
DSA reduces core attention complexity from:
- O(L²) → O(L·k)
Even though the lightning indexer still scales quadratically, it is:
- Much cheaper than full attention
- Implemented efficiently
- Amortized over large contexts
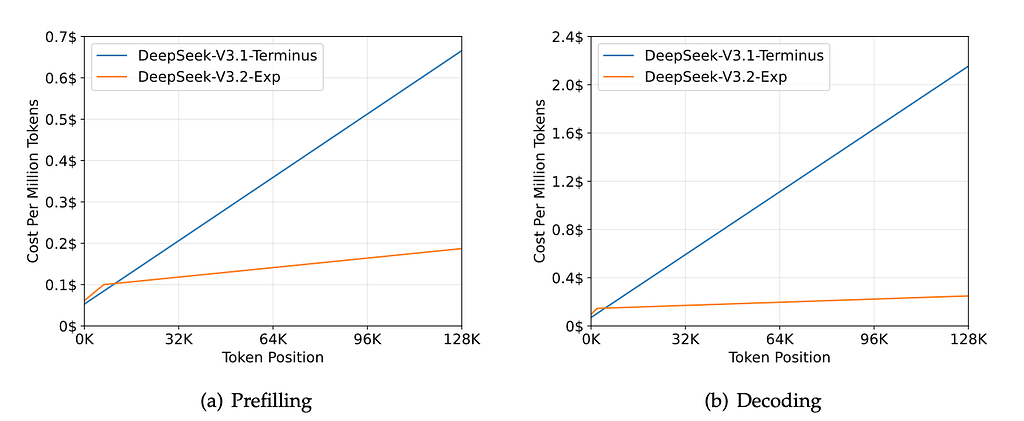
Inference cost curves show dramatic savings at 64K–128K tokens on H800 GPUs
Limitations and Open Questions
DSA is promising — but not free.
Key challenges remain:
- Short-sequence inefficiency: when L < k, attention is effectively computed twice
- Training rigidity: skipping warm-up or misaligning losses leads to degradation
- Potential information loss: sparse selection risks missing subtle long-range dependencies
- Real-world validation: large-scale deployment behavior is still being evaluated
Final Takeaway
DeepSeek Sparse Attention is not a cosmetic optimization — it’s a system-level rethinking of attention scalability.
It demonstrates that:
- Sparse attention can match dense performance
- Long-context efficiency is achievable without architectural overhaul
- Careful training design is more important than clever sparsity alone
DSA may not be the final answer — but it’s one of the most practical steps toward truly scalable long-context LLMs today.
References
- DeepSeek V3.2 https://arxiv.org/abs/2512.02556
DeepSeek Sparse Attention: From O(L²) to Near-Linear O(L·n) was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.