Building Reliable Machine Learning Systems for Heart Disease Prediction
Why ensemble methods generalize better than deep learning on clinical tabular data
Heart disease continues to be the leading cause of death worldwide, responsible for millions of deaths every year. Despite advances in clinical diagnostics, early and accurate detection remains a persistent challenge. Traditional diagnostic procedures are often invasive, expensive, and heavily dependent on physician interpretation.
This is where Machine Learning (ML) offers a compelling alternative.
In this article, I present a comprehensive machine learning study that benchmarks Deep Learning, Stacking Ensembles, and a Multi-Level Hybrid Stacking Ensemble for heart disease prediction. The results demonstrate that carefully designed ensemble methods outperform standalone deep learning models, achieving state-of-the-art discrimination while maintaining robustness on real-world clinical data.
This work is based on our full experimental report and implementation.
Why Heart Disease Prediction Is a Perfect ML Problem
Heart disease diagnosis relies on a combination of physiological indicators such as:
- Age
- Blood pressure
- Cholesterol levels
- Exercise-induced angina
- ECG results
These variables interact in nonlinear and complex ways. Humans struggle to reason about these interactions at scale, but machine learning models excel at detecting subtle patterns across multiple dimensions.
The goal of this project was not merely to train a classifier, but to answer a deeper question:
Which modeling strategy provides the most reliable, generalizable, and clinically useful predictions for heart disease risk?
Background and Related Research
The UCI Heart Disease dataset has been a benchmark in medical machine learning research for decades. Early studies, including the original work by Detrano et al., achieved approximately 77% accuracy using logistic regression.
Over time, more advanced models such as:
- Support Vector Machines (SVM)
- K-Nearest Neighbors (KNN)
- Random Forests
- Gradient Boosting
pushed performance into the 80–88% accuracy range. However, a persistent challenge remains in the literature:
Higher accuracy often comes at the cost of interpretability and stability, especially with deep neural networks.
This project directly addresses that trade-off by comparing single deep learning models against ensemble-based strategies designed for tabular clinical data.
Dataset Overview: From Raw Clinical Records to ML-Ready Features
Data Source:
I used a consolidated heart disease dataset assembled from four UCI repositories:
- Cleveland Clinic Foundation
- Hungarian Institute of Cardiology
- VA Medical Center (Long Beach)
- University Hospital, Zurich
This produced approximately 920 patient records, making the dataset more diverse and representative than any single source alone.
Target Definition
The original dataset labeled heart disease severity on a scale from 0 to 4.
For clinical relevance and modeling clarity, I converted this into a binary classification task:
- 0 → No heart disease
- 1 → Presence of heart disease
Data Cleaning and Feature Engineering
Medical data is rarely clean — and this dataset was no exception.
Missing Values
Missing entries marked as “?” were replaced using median imputation, a robust choice that reduces sensitivity to outliers while preserving distributional stability.
Advanced Feature Engineering
To improve predictive signal, I introduced clinically meaningful composite features:
- Physiological ratios (e.g., cholesterol-to-max-heart-rate)
- Severity scores combining chest pain type and exercise-induced angina
- One-hot encoded categorical features
After engineering, the final dataset contained 24 informative features.
Scaling and Transformation
- Standard Scaling ensured stable convergence for neural networks and linear models
- Quantile Transformation corrected skewed distributions (notably chol and oldpeak)
This preprocessing pipeline proved critical for model stability and generalization.
Model Architectures Compared
I evaluated three fundamentally different modeling strategies, each representing a different philosophy of machine learning.
Deep Learning Baseline: Multilayer Perceptron (MLP)
The deep learning model served as a strong single-model benchmark.
Key characteristics:
- Feed-forward neural network implemented in PyTorch
- Funnel-shaped architecture compressing 24 features into abstract representations
- BCEWithLogitsLoss for numerical stability
- Adam optimizer with careful regularization
Despite extensive tuning (batch normalization, dropout, early stopping), the MLP showed signs of overfitting and instability, a common issue with tabular medical data.
Two-Level Stacking Ensemble (MLP Meta-Learner)
This architecture introduced ensemble learning while keeping complexity controlled.
Level 0: Base Models:
- Random Forest
- Gradient Boosting
- XGBoost
- LightGBM
Each model captures different decision boundaries and inductive biases.
Out-of-Fold (OOF) Predictions
Using 5-fold cross-validation, base models generated predictions only on unseen folds, eliminating data leakage and ensuring true generalization signals.
Level 1: Meta-Learner:
A compact MLP learned how to nonlinearly weight and combine the base model predictions.
This architecture produced the best AUC-ROC score in the entire study.
Multi-Level Hybrid Stacking Ensemble
This was the most advanced and computationally expensive architecture.

Level 0 (9 Base Models):
Included:
- Linear models (Logistic Regression, Ridge)
- Kernel and distance-based models (SVM, KNN)
- Tree-based ensembles (RF, Extra Trees, GB, XGBoost, LightGBM)
Level 1 (Meta Models):
- Logistic Regression
- Ridge Classifier
- LightGBM
Each trained on Level 0 OOF predictions.
Level 2 (Final Blender):
XGBoost, trained on a hybrid feature set combining Level 0 and Level 1 predictions. This design allows the final model to selectively trust both individual learners and refined blends.
How the Ensemble Learns: Model Diversity & Trust
This section goes beyond reporting performance metrics and aims to explain how the stacking ensemble arrives at its final predictions. Understanding the internal behavior of an ensemble is especially important in medical applications, where trust, robustness, and decision transparency matter as much as raw accuracy.
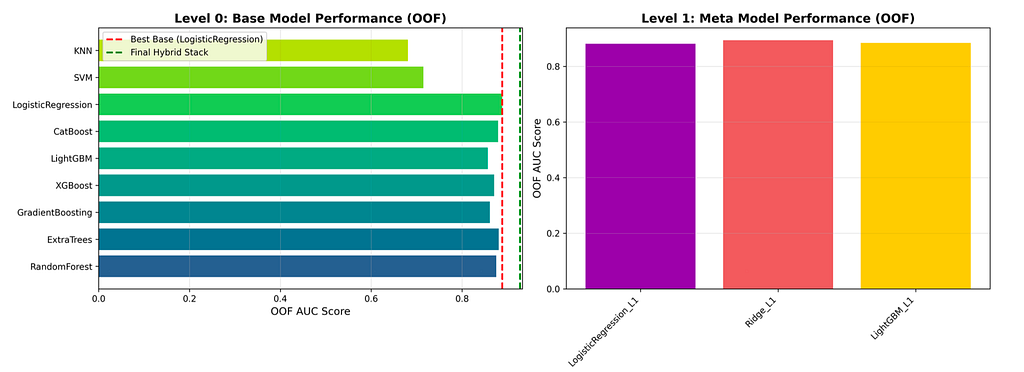
The first plot from figure 1 presents the Out-of-Fold (OOF) AUC scores of the Level 0 base models, offering a clear view of model diversity within the ensemble. Each base learner represents a different learning strategy — ranging from linear and distance-based methods to advanced tree-based ensembles. Strong performers such as Random Forest, Gradient Boosting, XGBoost, and LightGBM consistently achieve high OOF AUC scores, indicating their ability to capture complex, non-linear relationships in clinical data. At the same time, simpler models contribute complementary signals that help reduce bias and improve overall generalization. This diversity is a key strength of the ensemble, as it prevents over-reliance on any single modeling assumption.
The second plot from figure 1 focuses on the Level 1 meta-models, which are trained to combine the predictions generated by the Level 0 models. Rather than making decisions directly from raw clinical features, these meta-models learn from the behavior of the base learners themselves. By comparing different blending strategies — linear, regularized, and non-linear — the plot illustrates how higher-level aggregation can smooth inconsistencies, correct systematic errors, and produce more stable predictions. This stage plays a crucial role in transforming diverse model outputs into a more coherent and reliable signal.
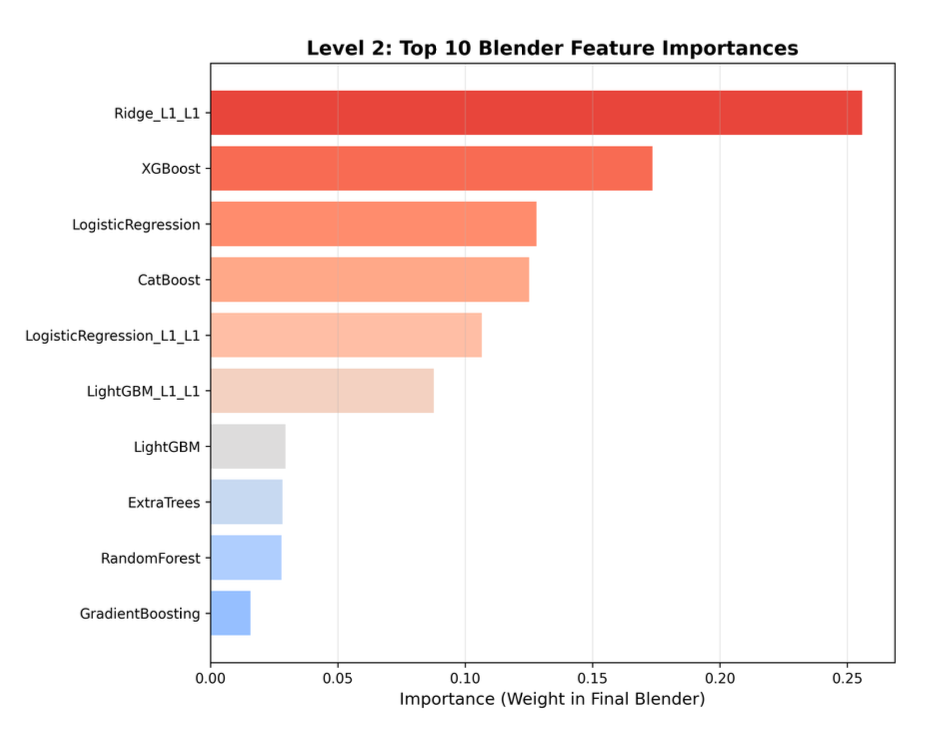
The final feature-importance plot provides insight into the decision logic of the Level 2 XGBoost blender, revealing which predictions the ensemble ultimately trusts most. Instead of averaging all inputs equally, the final model assigns different weights to base-level and meta-level predictions based on their reliability and contribution to overall performance. Strong individual learners and well-refined meta-model outputs are given greater importance, while weaker or noisier signals are naturally down-weighted. This selective weighting mechanism allows the ensemble to balance model diversity with precision, leading to robust and well-regularized final predictions.
Taken together, these visualizations demonstrate that the stacking ensemble is not a black box that blindly aggregates models. Instead, it follows a structured, hierarchical decision-making process — first encouraging diversity, then refining consensus, and finally selecting the most trustworthy signals. This layered approach explains why the ensemble achieves superior discrimination and stability compared to single models, making it particularly well-suited for high-stakes clinical prediction tasks.
Comparison and Results: A Clear Performance Hierarchy

Key Observations
- Ensembles consistently outperform deep learning
- The stacking ensemble achieved the best risk discrimination (AUC)
- Hybrid stacking favored accuracy but slightly sacrificed ranking quality
In clinical screening, AUC-ROC matters more than raw accuracy, as it measures how well patients are ranked by risk.
AUC–ROC vs Accuracy: What the Results Really Tell Us

A closer look at the evaluation metrics reveals an important insight into how different modeling strategies behave in clinical prediction tasks.
The Stacking Ensemble achieved the highest AUC-ROC score of 0.9316, surpassing its strongest individual base learner, Random Forest, which achieved an AUC of 0.9265. While this numerical improvement may appear modest at first glance, it represents a meaningful gain in risk discrimination. In medical screening problems, even small increases in AUC can translate into better ranking of high-risk patients — helping clinicians prioritize who needs further testing or intervention. This improvement is the core success of the stacking approach: it combines multiple strong learners in a way that enhances generalization beyond any single model.
Interestingly, the Hybrid Stacking Ensemble tells a slightly different story. This model achieved the highest test accuracy (0.8750), indicating that it was particularly effective at drawing a sharp decision boundary between diseased and non-diseased patients. However, its AUC-ROC (0.9278) was marginally lower than that of the simpler stacking ensemble. This trade-off highlights an important modeling nuance:
different meta-learners shape how ensembles make decisions. The MLP meta-learner in the stacking ensemble emphasized smooth probability ranking, while the XGBoost final blender in the hybrid model optimized for classification precision, favoring correctness at the threshold rather than overall ranking quality.
Beyond the ensembles, several baseline behaviors are worth noting. Logistic Regression performed surprisingly well, suggesting that the underlying decision boundary in this dataset may be closer to linear than expected. This reinforces a common lesson in applied machine learning: simpler models should never be dismissed without empirical testing.
As anticipated, the single Decision Tree showed clear signs of overfitting, with degraded performance on the test set. When aggregated into a Random Forest, however, performance improved substantially — validating the principle that ensembling unstable learners reduces variance and improves generalization.
Overall, these results demonstrate that while accuracy is important, AUC-ROC is the more informative metric for clinical risk prediction, and that stacking ensembles strike the best balance between discrimination, robustness, and reliability in this task.
Clinical Perspective: Type I vs Type II Errors
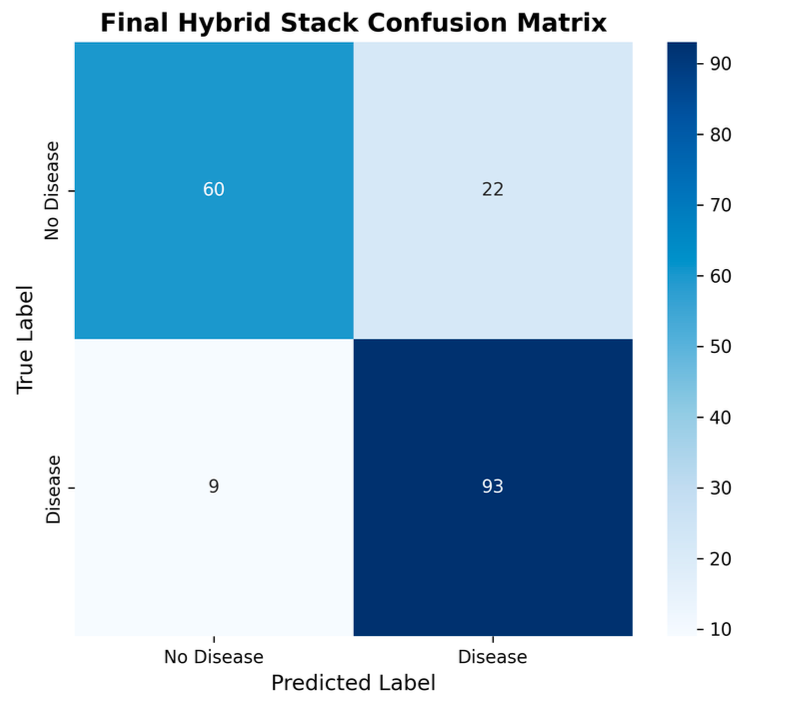
In healthcare:
- False negatives (Type II errors) can be life-threatening
- False positives increase cost and anxiety
The ensemble models demonstrated superior control over both error types, making them better suited for real-world diagnostic support.
Why Ensembles Beat Deep Learning on Tabular Medical Data
Our findings reinforce a growing consensus in applied ML:
For structured, tabular clinical data, ensemble learning often outperforms deep neural networks.
Reasons include:
- Better bias–variance tradeoff
- Natural resistance to noise
- Reduced sensitivity to feature scaling
- More stable generalization
Challenges Encountered
- Data heterogeneity across multiple sources
- Computational cost of multi-level stacking
- Interpretability concerns for black-box ensembles
- Training instability in deep learning models
These challenges highlight why performance alone is not enough — deployability matters.
Future Directions
- Prune low-impact base models to reduce complexity
- Explore TabNet and FT-Transformer architectures
- Integrate Explainable AI (SHAP, LIME) for clinician trust
- Evaluate robustness under data drift
- Extend to longitudinal risk prediction
Final Thoughts
This study demonstrates that stacking ensembles represent the current state-of-the-art for heart disease prediction on tabular clinical data.
The recommended model — a two-level stacking ensemble with an MLP meta-learner — achieves:
- Excellent discrimination (AUC-ROC 0.9316)
- Strong generalization
- Practical clinical relevance
In high-stakes domains like healthcare, robust ensemble learning is not just an option — it is a necessity.
References
Dua, D. and Graff, C. (2019) UCI Machine Learning Repository. University of California, Irvine, School of Information and Computer Sciences. Available at: https://archive.ics.uci.edu (Accessed: 8 March 2025).
Detrano, R., Janosi, A., Steinbrunn, W., Pfisterer, M., Schmid, J., Sandhu, S., Guppy, K., Lee, S. and Froelicher, V. (1989) ‘International application of a new probability algorithm for the diagnosis of coronary artery disease’, American Journal of Cardiology, 64(10), pp. 711–716.
Géron, A. (2019) Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow. 2nd edn. Sebastopol, CA: O’Reilly Media.
Mitchell, T.M. (2017) Machine Learning. New York: McGraw-Hill.
UCI Machine Learning Repository (1988) Heart Disease Dataset. Available at: https://archive.ics.uci.edu/dataset/45/heart+disease (Accessed: 8 March 2025).
Building Reliable Machine Learning Systems for Heart Disease Prediction was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.