
9 RAG Architectures That Save You Months of Dev Work
From Standard RAG to GraphRAG — battle-tested patterns, copy-paste implementation notes, and the contrarian move that kills hallucinations faster than better embeddings
TL;DR
RAG is a toolbox, not a single recipe. Pick the wrong pattern and you’ll waste months fighting hallucinations, latency, or runaway costs.
Start with Standard RAG as your baseline. For accuracy-critical systems, use CRAG; for multi-source enterprise applications, use Fusion or GraphRAG; for automation-heavy workflows, use Agentic RAG.
Contrarian rule: Invest as much engineering effort in verification and generation as you do in retrieval.
Pick the wrong RAG architecture and you’ll spend months chasing hallucinations, latency, and exploding cloud bills.
Read this once — you’ll walk away with a clear mental map of 9 RAG architectures, a one-line implementation pattern for each, production-tested tips, and a practical 2-week plan you can actually ship.
Quick Read
- Skim the nine architecture headings to find what matches your product.
- Read the One-liner / When to use / Pattern / Takeaway for the patterns aligned with your risk profile.
- Implement Standard RAG as your baseline, then prototype one additional pattern (CRAG for accuracy, Conversational for chat, Fusion for enterprise).
- Run the A/B test plan at the end to validate impact.
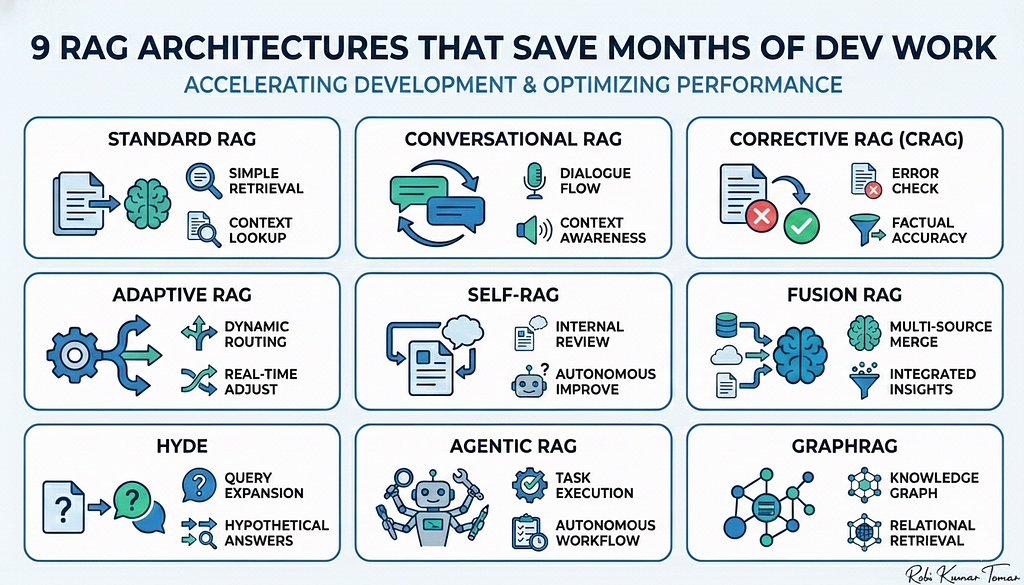
The 9 RAG architectures:
1. Standard RAG — the workhorse
One-liner: Retrieve top-k passages → inject into the prompt → generate.
When to use: Fast MVPs, FAQ search, and single-turn Q&A.
Quick pattern:
docs = retriever.get(query, k=5)
prompt = f"Context:n{join(docs)}nnQ: {query}"
answer = llm.generate(prompt)
Pros: Fast to prototype; clear, explainable baseline.
Cons: Conflicting passages can increase hallucinations; not multi-turn aware.
Production tip: Add a light cross-encoder reranker and enforce strict token budgets.
Takeaway: Start here — then measure precision@k and hallucination rate before iterating.
2. Conversational RAG — RAG with memory & condensation
One-liner: Standard RAG augmented with dialogue state and query condensation.
When to use: Assistants, customer support chat, and multi-turn workflows.
Quick pattern:
condensed = condense(current_turn, convo_history)
docs = retriever.get(condensed, k=5)
answer = llm.generate(history + docs + prompt)
Production tip: Persist only salient turns (entity changes, decisions). Sample or summarize older turns to control token usage.
Takeaway: Query condensation keeps context relevant while staying cost-efficient.
3. One-liner: Generate → extract claims → retrieve evidence → verify and rewrite.
When to use: Legal, medical, and finance domains — anywhere mistakes are expensive.
Mini-pseudocode:
draft = llm.generate(prompt_with_context)
claims = extract_claims(draft)
evidence = retriever.get_many(claims)
final = llm.generate(verification_prompt(draft, evidence))
Pros: Reduces factual errors and produces evidence-backed answers.
Cons: Higher latency and cost.
Production tip: Build a robust claim extractor (rules + NER) and track claim-level precision.
Takeaway: When accuracy matters more than latency, CRAG is the default choice.
4. Adaptive RAG — route to fit intent
One-liner: Route queries to different retrieval and prompt pipelines based on detected intent or confidence.
When to use: Mixed workloads (FAQs, research queries, creative tasks).
Pattern: Intent classifier → select pipeline.
- Fast path: Low-k retrieval, cached or templated answers.
- Deep path: High-k retrieval, multi-hop or iterative retrieval with richer prompts.
Production tip: Keep the intent model small and inexpensive; ensure routing rules and policies are auditable.
Takeaway: Adaptive RAG delivers speed for simple queries and depth where it truly matters.
5. Self-RAG — let the model propose search terms
One-liner: The LLM generates query expansions or keywords that are then used for retrieval.
When to use: Vague user inputs and domains with heavy paraphrasing.
Pattern:
- LLM proposes 2–3 query expansions
- Use expansions to query the vector database
- Aggregate retrieved passages and generate the final answer
- Guardrail: Validate or constrain generated queries to prevent model-invented or out-of-scope terms
Takeaway: Self-RAG boosts recall for messy inputs — but only when search terms are tightly guarded.
6. Fusion RAG — multiple retrievers, one synthesizer
One-liner: Pull evidence from vectors, web search, and DBs → rerank → synthesize.
When to use: Enterprise systems that combine internal docs + web + DBs.
Pattern: Run vector search + web API + SQL → merge & rerank → LLM synthesize with provenance labels.
Production tip: Normalize provenance and surface it to users.
Takeaway: Use Fusion when breadth of sources matters.
7. HyDE (Hypothetical Document Embeddings) — generate to retrieve
One-liner: Generate hypothetical Q/A pairs from documents, index their embeddings, and significantly boost recall.
When to use: Sparse documentation or content with many paraphrases and varied phrasing.
Pattern: Generate multiple Q/A variants per document → embed and index them → retrieve against user queries.
Production tip: Regenerate HyDE entries whenever models or source documents change.
Takeaway: HyDE is a low-cost preprocessing technique that dramatically improves recall for paraphrase-heavy queries.
8. Agentic RAG — retrieval inside an agent loop
One-liner: Retrieval becomes a first-class tool in an agent’s planner → executor → verifier cycle.
When to use: Multi-step automation, research agents, and code-writing bots.
Pattern: Planner → (retriever as a tool) → executor → verifier, with the agent spawning sub-queries and iterating as needed.
Production tip: Sandbox tool execution and implement step-level rollbacks for safety and recovery.
Takeaway: Agentic RAG moves you from Q&A to action — use it for automation-heavy products.
9. GraphRAG — vector retrieval + graph reasoning
One-liner: Combine vector retrieval with a knowledge graph to enable entity-driven, multi-hop reasoning.
When to use: Biotech, legal, and research domains where complex entity relationships and provenance are critical.
Pattern: Retrieve relevant passages → entity-link to graph nodes → perform graph traversal for multi-hop inference → synthesize with an LLM and surface the traversal path.
Production tip: Invest heavily in accurate entity-linking and a clear provenance UI.
Takeaway: GraphRAG is the right choice when explainable, multi-hop answers with traceable provenance are non-negotiable.
Quick decision cheat-sheet
- Accuracy critical: CRAG or GraphRAG.
- Conversational: Conversational RAG + condensation.
- Mixed workload: Adaptive or Fusion RAG.
- Paraphrase-heavy / sparse docs: HyDE or Self-RAG.
- Automation / agents: Agentic RAG.
Common engineering pitfalls (don’t do these)
- Dump top-k blindly — conflicting passages → hallucination. Rerank & filter.
- No citation policy — design how provenance is surfaced.
- Single retriever for everything — different tasks need different retrievers & thresholds.
- No monitoring — track hallucination rate, precision@k, latency, token cost.
- Ignore token budgets — higher k increases cost nonlinearly.
Monitoring & evaluation
- Hallucination rate — % answers with at least one false claim (manual + automated).
- Precision@k / Recall@k — retrieval quality.
- Latency (p95) — critical for UX.
- Cost / query — tokens + API charges.
- User trust score — human-review pass rate or NPS.
- Claim-level accuracy — for CRAG systems.
Automated test ideas: synthetic adversarial queries, paraphrase tests, regression suite after index/LLM updates.
Micro-case study
A fintech pilot launched with Standard RAG for customer summaries. Legal flagged risky claims. They implemented CRAG (generate → extract claims → verify). After 3 sprints:
- Hallucination rate ↓ 78%
- Legal sign-off time ↓ 86% (from ~3 weeks to ~3 days)
- Human review interventions ↓ 60%
Why it worked: The verification loop forced reconciliation between draft claims and retrieved evidence — engineering investment in verification delivered outsized reliability gains.
A/B test you should run (2-week plan)
Goal: Reduce hallucination while keeping latency acceptable.
- A (Baseline): Standard RAG.
- B (Variant): CRAG (verification loop) or Adaptive RAG (intent routing).
- Traffic: 10–20% stratified traffic for 2 weeks.
- Primary metric: Hallucination rate.
- Secondary: latency (p95), cost/query, user trust score.
Decision rule: Adopt B if hallucination rate ↓ ≥30% with latency ≤ +200ms p95 and cost increase ≤ 30%.
Packaging & production checklist
- Semantic chunking with overlap; keep chunk sizes within prompt-window limits.
- Cross-encoder reranker for top-N retrieval results.
- Incremental embedding refresh for dynamic or frequently updated sources.
- Caching for high-frequency and repeat queries.
- Token-budget enforcement with summarization for long contexts.
- Snapshot, backup, and rebuild plan for the vector database.
- PII redaction pipeline and strict access controls for private data.
- Human-in-the-loop review for flagged outputs, with feedback loops for retraining or re-indexing.
This is the part most people skip (U don’t)
Stop chasing tiny retrieval gains. A moderate retriever paired with strong verification and generation (claim extraction, rewrite prompts, conservative answer styles) consistently outperforms a brittle, hyper-tuned retriever in real production systems.
👉 Rebalance your roadmap: 50% retrieval, 50% verification + generation.
“A better generator + verification loop beats a perfect retriever in production.”
If you’re not an engineer (quick summary)
- Need accuracy (legal, finance, product)? Ask for CRAG.
- Need a chat assistant? Ask for Conversational RAG with condensation.
- Need cross-system answers (internal docs + web)? Ask for Fusion RAG.
👉 Tell your engineering lead one metric that matters most (accuracy, latency, cost, or trust). That single choice should determine which RAG pattern gets prototyped next.
💬 Over to you
Comment one word to vote: Which will you try next?
- Standard RAG
- CRAG (verification-first)
- Conversational RAG
- Fusion / GraphRAG
❤️ If this shifted how you think about RAG Architecture, drop a clap 👏 and follow for more practical, battle-tested AI engineering insights.
9 RAG Architectures That Save You Months of Dev Work was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.