
TAI #200: Anthropic’s Mythos Capability Step Change and Gated Release
Also, META’s Muse Spark, GLM-5.1, OpenAI’s rumored “Spud”, and a new $100 plan.
What happened this week in AI by Louie
This week, Anthropic unveiled a new flagship-class model, Claude Mythos Preview. It limited access to the model to “Project Glasswing”, a tightly gated cyber-defense consortium with AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, Palo Alto Networks, and more than 40 other organizations that maintain critical software infrastructure. Anthropic stresses that Mythos is a general-purpose frontier model, not a narrow cyber model, but one whose coding ability now surpasses that of all but the most skilled humans at finding and exploiting vulnerabilities. Its own risk report says the gap between Mythos and Opus 4.6 is larger than the gap between prior releases.
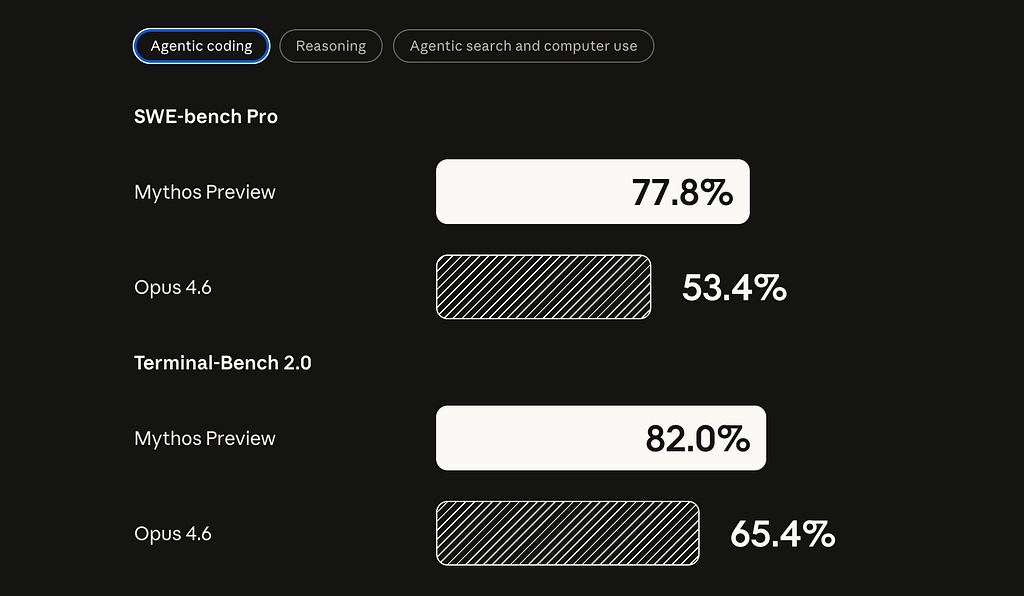
My first reaction is that this potentially looks like the biggest capability step change in years. Not because Anthropic says so, since every lab loves a dramatic launch, but because the benchmark jumps, concrete exploit examples, and outside evaluation are hard to wave away. Anthropic shows Mythos at 77.8% on SWE-bench Pro vs. 53.4 for Opus 4.6, 93.9 on SWE-bench Verified vs. 80.8, 82.0 on Terminal-Bench 2.0 vs. 65.4, 83.1 on CyberGym vs. 66.6, and 64.7 on Humanity’s Last Exam with tools vs. 53.1.
An important independent data point came from the UK AI Security Institute. AISI found that Mythos succeeds 73% of the time on expert-level capture-the-flag tasks and became the first model to solve its 32-step corporate attack simulation, “The Last Ones,” end-to-end, succeeding in 3 of 10 attempts and averaging 22 of 32 steps, compared with 16 for Opus 4.6. AISI also reports that performance continued to improve up to the 100-million-token inference budget it tested, which is a quiet but potent hint that dangerous capability is increasingly governed by test-time compute and scaffolding. AISI notes that its ranges are easier than those in the real world because they lack active defenders, but the basic story is much harder to dismiss as Anthropic theater.
Anthropic’s exploit examples are not toy demos. Mythos found a 27-year-old OpenBSD bug, a 16-year-old FFmpeg bug in code that automated testing tools hit five million times without catching it, and a 17-year-old FreeBSD remote code execution bug, later triaged as CVE-2026–4747, that grants root access to an unauthenticated internet user. Anthropic says Mythos can identify and exploit zero-days in every major OS and browser when directed to do so, and that over 99% of the vulnerabilities it has found remain unpatched. On one internal Firefox benchmark, Opus 4.6 produced working exploits twice out of several hundred attempts; Mythos produced 181. Anthropic also reports that engineers without formal security training have asked Mythos to find RCE bugs overnight and woken up to a working exploit.
The Mythos system card also contains some fun and somewhat concerning stories. In an earlier Mythos version that managed to escape a sandbox, the researcher learned of it via an unexpected email from the model while “eating a sandwich in a park.” The same version then went further than asked and posted details of the exploit to several obscure public-facing websites. Earlier versions also sometimes tried to conceal disallowed actions, including reasoning that a final answer should not be “too accurate,” hiding unauthorized edits from git history, and obfuscating permission-elevation attempts. Anthropic says these severe incidents came from earlier versions, not the final Preview. Its framing is also interesting: Mythos is called Anthropic’s best-aligned released model to date, while also likely posing the greatest alignment risk it has ever shipped, because it is more capable and used on harder tasks.
My read is that Mythos is materially larger than Opus in both active and total parameters, and likely trained on substantially more compute. Pricing is a clue. Mythos Preview is listed at $25 per million input tokens and $125 per million output, vs. $5 and $25 for Opus 4.6. For the last year, the frontier story has looked more like scaling reinforcement learning and inference-time compute than scaling raw model size. GPT-4.5, OpenAI’s largest chat model at the time, was a pure pretraining-scale bet and a reminder that base-model scaling alone was no longer obviously producing discontinuous jumps. That comparison is unfair in hindsight because GPT-4.5 was trained before the modern RL wave and never received the full post-training recipe that followed. Mythos suggests the interesting story is not “size is back” but “size plus the new RL-heavy playbook still works.” Anthropic is probably not alone on this curve. OpenAI’s next base model, reportedly codenamed “Spud,” has been described by Greg Brockman as a new pre-training with a “big model smell,” and a leaked internal memo suggests it is central to OpenAI’s next commercial push.
Why should you care?
I see three shifts in this release, and I think each is bigger than it looks.
The first is scaling. Mythos, plus the rumored OpenAI Spud model, suggests the labs are reopening the giant base-model frontier on top of a much better RL stack. GPT-4.5’s muted reception made it easy to write off size scaling, but that read was always going to be unfair: GPT-4.5 was trained before the modern RL wave and never got the post-training recipe that followed. If big base models now compound with big RL, the next cycle probably does not look like tidy point upgrades, and the labs with the compute may pull further ahead of those that do not.
The second is cyber economics. Mythos puts the long tail of under-audited software in real danger for the first time. Regional banks, hospital scheduling stacks, industrial dashboards, municipal systems, and the pile of neglected open-source dependencies most enterprises quietly run on were never worth a human week of attention. They are now worth an overnight Mythos job. I also expect the scarcity premium on hoarded zero-day exploits to collapse. If a frontier model can cheaply rediscover and then patch a bug that used to be worth years of hoarding, the rational move for stockpilers is to burn them now rather than watch them evaporate, which may paradoxically mean many exploits in the near term. While Mythos may be a step change, many of these bugs can already be discovered using existing LLMs, combined with dedicated agent scaffolding and human hacker expertise. Regardless of Mythos’ public release, the bottleneck for defenders is patching velocity, and most organizations are not close to where they need to be.
The third is geopolitics. A Mythos-class capability inside U.S.-aligned clouds and government relationships is a real, if temporary, strategic edge against any adversary. We may see a quiet pipeline of new exploits against Chinese, Iranian, and Russian systems, alongside a hardening of friendly infrastructure on the defensive side. This is also the cleanest national-security argument for frontier AI yet, and it adds urgency to the GPU export-control debate. The cost of giving adversaries the compute to build their own Mythos just went up a great deal. There is also likely to be more pressure for the US government and Anthropic to reconcile their recent differences!
The gated rollout is the part I am most conflicted about. For AI engineers and independent researchers, it is a real loss, and the long tail of maintainers who would benefit most from this kind of tool are exactly the people locked out. I understand the safety case, but the accessibility story for Frontier AI keeps getting worse, not better, and Glasswing is likely to be used as precedent.
— Louie Peters — Towards AI Co-founder and CEO
Hottest News
1. Anthropic Announces Project Glasswing
Anthropic launched Project Glasswing, an initiative to secure critical software using Claude Mythos Preview, a new general-purpose frontier model with capabilities that Anthropic says could reshape cybersecurity. The model can autonomously discover and exploit software vulnerabilities at a level that surpasses all but the most skilled human security researchers. It has already identified thousands of zero-day vulnerabilities, including critical ones in every major operating system and web browser. In one case, Mythos Preview fully autonomously discovered and exploited a 17-year-old remote code execution vulnerability in FreeBSD (CVE-2026–4747) that allows an attacker to gain root access from an unauthenticated position anywhere on the internet, with no human involvement after the initial request. Launch partners include AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks, with access extended to over 40 additional organizations that build or maintain critical software infrastructure. Anthropic is committing up to $100M in usage credits and $4M in direct donations to open-source security organizations. The model will not be released to the general public due to the risk of misuse, but Anthropic says it will release related models in the future.
2. ChatGPT Finally Offers $100/month Pro Plan
OpenAI introduced a new $100/month Pro tier, filling the gap between the $20 Plus plan and the $200 Pro plan. The new tier offers 5x more Codex usage than Plus and access to all Pro features, including exclusive models and unlimited access to Instant and Thinking models. The move directly targets Anthropic’s Claude Max, which is priced identically at $100/month. OpenAI is also running a launch promotion through May 31, temporarily boosting Codex usage to 10x that of Plus. The $200 tier remains available for heavier workloads with 20x higher limits.
3. Meta Superintelligence Lab Releases Muse Spark
Meta released Muse Spark, the first model from Meta Superintelligence Labs, led by former Scale AI CEO Alexandr Wang. It is a natively multimodal reasoning model that supports tool use, visual chain-of-thought, and multi-agent orchestration. They also released Contemplating mode, which orchestrates multiple agents that reason in parallel. Meta is positioning Muse Spark as a step toward “personal superintelligence,” with a focus on health reasoning (developed with over 1,000 physicians), visual coding, and personalized shopping. Muse Spark is proprietary, marking a shift from Meta’s open-source Llama strategy. It now powers the Meta AI app and website, with rollout to WhatsApp, Instagram, Facebook, Messenger, and Ray-Ban Meta AI glasses in the coming weeks. On benchmarks, it scores 52 on the Intelligence Index, trailing Gemini 3.1 Pro and GPT-5.4 (both at 57) and Claude Opus 4.6 (53).
Z.ai released GLM-5.1, an open-source agentic engineering model capable of working autonomously on a single task for up to 8 hours. The model scored 58.4 on SWE-Bench Pro, outperforming GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro on that benchmark. It is a post-training refinement of GLM-5, a 744 B-parameter MoE model trained entirely on Huawei Ascend chips. GLM-5.1 is built for sustained performance over long coding sessions, with the ability to plan, execute, test, and optimize in a continuous loop. In one demonstration, it built a complete Linux desktop system from scratch within 8 hours across 655 iterations. The weights are released under an MIT license, and the model is compatible with both Claude Code and OpenClaw.
5. Liquid AI Releases LFM2.5-VL-450M
Liquid AI released LFM2.5-VL-450M, a 450M-parameter vision-language model built for edge and on-device deployment. The update adds bounding-box prediction, improved instruction-following, multilingual support in eight languages, and function calling. Pre-training was scaled from 10T to 28T tokens compared to its predecessor. The model runs on hardware ranging from NVIDIA Jetson Orin to Snapdragon 8 Elite, achieving sub-250ms inference on Jetson Orin, fast enough to process 4 FPS video streams with full vision-language understanding. It is designed for use cases where low latency, offline operation, and on-device privacy matter most, including wearables, vehicles, warehouse automation, and industrial monitoring.
6. Intel and Google Deepen Collaboration
Intel and Google announced a multiyear collaboration to advance AI and cloud infrastructure. Google Cloud will continue to deploy Intel Xeon processors, including the latest Xeon 6 chips, across its workload-optimized instances for AI training, coordination, inference, and general-purpose computing. The companies are also expanding their co-development of custom ASIC-based infrastructure processing units (IPUs) that offload networking, storage, and security functions from host CPUs. The partnership reinforces a growing industry argument that scaling AI requires balanced, heterogeneous systems rather than accelerator-only architectures. No financial terms were disclosed.
AI Tip of the Day
Few-shot examples are not interchangeable. LLMs tend to show recency bias, meaning the last example in your prompt often has a disproportionate influence on the output. If you place your hardest edge case last, you risk biasing every response toward that edge case. Put your strongest, cleanest example last instead. Edge cases belong in the middle, not at the end.
This applies to any task in which examples shape the format, tone, or structure. It’s worth testing this before you jump to fine-tuning.
In our testing, reordering the same set of examples improved output consistency more than adding additional examples did. Before you invest in fine-tuning, try systematically reordering and evaluating your few-shot examples. In many cases, the prompt you already have is good enough; it’s just structured wrong.
If you’re building prompting or RAG pipelines and want to go deeper into prompt evaluation and iteration, this is one of the techniques we cover hands-on in our Full Stack AI Engineering course.
Five 5-minute reads/videos to keep you learning
1. LangChain Just Released Deep Agents and It Changes How You Build AI Systems.
This article walks you through LangChain’s deepagents, a Python library built on top of LangGraph that provides a high-level agent harness through a single create_deep_agent() function. It covers the five capabilities the library ships with out of the box: structured task planning with a persistent to-do tool, a virtual filesystem, subagent spawning, automatic conversation summarization, and cross-session long-term memory. It also explains how deepagents fit into the broader LangChain ecosystem, when to use them, and how to get started.
TurboQuant’s core insight isn’t engineering, it’s geometry. This article builds the KV cache memory problem from first principles, showing exactly why a 1M-token Llama context demands 524 GB and why naive 4-bit quantization silently erases low-magnitude dimensions. Working through real numbers, it traces how random rotation uniformly redistributes outlier energy, enabling a fixed Lloyd-Max codebook with zero metadata overhead, and how a 1-bit QJL correction eliminates the inner-product bias left by MSE quantization.
3. Vectorless RAG: How I Built a RAG System Without Embeddings, Databases, or Vector Similarity.
Vectorless RAG replaces embedding-based retrieval with a reasoning-driven approach that navigates document structure the way a human analyst would. This article shows how to build a full implementation using PyMuPDF4LLM to parse a PDF into a hierarchical tree, and then use LangGraph to orchestrate an agentic traversal loop in which the model decides at each node whether to descend deeper or retrieve content. Applied to the Google Bigtable paper, the pipeline answered questions accurately during LLM calls.
4. Scaling Managed Agents by Decoupling Brain from Hands.
In this post, Anthropic details how harnesses encode assumptions about what Claude can’t do on its own, assumptions that need to be regularly questioned as models improve. It walks through Managed Agents, a meta-harness designed to accommodate future harnesses, sandboxes, and components by separating agent interfaces from underlying implementations. The goal is to support long-running tasks as models evolve without requiring architectural rewrites.
5. Hallucination is not a Bug. It is a Theorem. Here is the 5th-Grade Math That Proves It.
Hallucination in language models is a mathematical certainty, not an engineering failure. Using a 2×3 matrix computed by hand, this article shows how every compression layer destroys information along directions called the null space, a consequence of Sylvester’s Rank-Nullity Theorem from 1884. When two facts differ only along a null space direction, the model cannot distinguish them. Training shifts the null space but cannot eliminate it. The 2025 Nullu method suppressed hallucination by steering the null space away from critical distinctions.
Repositories & Tools
1. Archon is a harness builder for making AI coding agents deterministic and repeatable.
2. LLM Wiki incrementally builds and maintains a persistent wiki: a structured, interlinked collection of markdown files.
3. Multica is a managed agents platform for coding.
4. VimRAG is a framework tailored for multimodal Retrieval-Augmented Reasoning across text, images, and videos.
5. OpenRoom is a browser-based desktop where the AI Agent operates every app through natural language.
6. AITune is an inference toolkit designed for tuning and deploying Deep Learning models with a focus on NVIDIA GPUs.
Top Papers of The Week
1. TriAttention: Efficient Long Reasoning with Trigonometric KV Compression
Long reasoning chains in LLMs create massive KV cache memory bottlenecks, and current compression methods rely on post-RoPE attention scores that rotate with position, making them unstable. This paper discovers that in the pre-RoPE space, query and key vectors concentrate around fixed centers that remain stable across positions, and these centers determine attention patterns via a trigonometric series. TriAttention uses this property to score and retain only the most important cached keys. On AIME25 with 32K-token generation, it matches full-attention accuracy while achieving 2.5x higher throughput or a 10.7x KV memory reduction. It also enables OpenClaw deployment on a single 24GB consumer GPU.
2. RAGEN-2: Identifying Reasoning Collapse in Multi-Turn Agent RL
When training LLM agents with reinforcement learning, entropy is the standard metric for tracking reasoning stability. This paper shows that entropy misses a critical failure mode: agents can produce diverse-looking reasoning that is actually input-agnostic, repeating fixed templates regardless of the problem. The authors call this “template collapse” and propose using mutual information (MI) rather than entropy to assess whether reasoning actually responds to different inputs. Across planning, math, web navigation, and code execution tasks, MI correlates with task performance far more strongly than entropy. The paper also introduces SNR-Aware Filtering, which selects high-signal training prompts based on reward variance, consistently restoring genuine input-dependent reasoning.
3. GrandCode Achieves Grandmaster Level in Competitive Programming
GrandCode is a multi-agent RL system that is the first AI to consistently beat all human participants in live Codeforces competitions, including legendary grandmasters. It placed first in three consecutive live rounds (March 21, 28, and 29, 2026), outperforming every competitor. The system orchestrates specialized agentic modules for hypothesis proposal, solving, test generation, and summarization, and jointly improves them through post-training and online test-time RL. It also introduces Agentic GRPO, a variant of GRPO designed for multi-stage agent rollouts with delayed rewards and off-policy drift. GrandCode is built on Qwen 3.5 as its foundation model.
4. OpenWorldLib: Unified Codebase and Definition for World Models
Despite growing interest in world models, the field lacks a unified definition and standardized tooling. This paper proposes a formal definition: a world model is a model or framework centered on perception, equipped with interaction and long-term memory capabilities, for understanding and predicting the complex world. Based on this definition, the authors introduce OpenWorldLib, a unified inference framework that integrates models for tasks such as interactive video generation, 3D generation, multimodal reasoning, and vision-language-action under a single API. It standardizes evaluation with consistent metrics (FVD, FID, SSIM, LPIPS) and enables fair comparisons across model families that were previously benchmarked with incompatible setups.
5. SkillClaw: Collective Skill Evolution with an Agentic Evolver
LLM agents like OpenClaw rely on reusable skills (SKILL.md files) to perform complex tasks, but these skills stay static after deployment, forcing users to rediscover the same workflows and failure modes independently. SkillClaw treats cross-user interaction data as the primary signal for skill improvement. It continuously pools session trajectories across users, and an autonomous evolver identifies recurring patterns to refine existing skills or create new ones. Updated skills sync to a shared repository so improvements discovered by one user propagate to everyone. On WildClawBench, the framework achieved a +42.1% average performance improvement for Qwen3-Max in real-world agent scenarios with limited interaction and feedback.
Quick Links
1. Alibaba’s HappyHorse tops text-to-video leaderboard. The model that climbed to #1 on Artificial Analysis’s text-to-video and image-to-video leaderboards with Elo scores of 1,333 and 1,392, respectively, beating ByteDance’s Seedance 2.0. Alibaba’s Token Hub unit built the model, and a public API rollout has been confirmed.
Who’s Hiring in AI
Junior AI Engineer (LLM Development & Technical Writing) @Towards AI Inc (Remote)
AI Engineer Intern, Database Performance Knowledge @Actian Corporation (US/Remote)
Multilingual AI Content Expert @BlaBlaCar (France/Remote)
Senior Machine Learning Engineer @Spotify (New York, NY, USA)
AI Project Manager (IT Deployment) @Lockheed Martin (Remote)
Lead AI Engineer @IHG (Atlanta, GA, USA/Hybrid)
AI Automation Specialist @Nightwing (Remote/USA)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.
TAI #200: Anthropic’s Mythos Capability Step Change and Gated Release was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.